持续创作,加速成长!这是我参与「掘金日新计划 · 10 月更文挑战」的第20天,点击查看活动详情
视频作者:简博士 - 知乎 (zhihu.com);简博士的个人空间_哔哩哔哩_bilibili
链接:【合集】十分钟 机器学习 系列视频 《统计学习方法》_哔哩哔哩_bilibili
原书:《统计学习方法》李航
基尼指数
ID3算法通过信息增益求特征、C4.5通过信息增益比求特征,而在CART算法中,是通过基尼指数来选择最优特征的。
假设有K个类,样本点属于第k类的概率为pk,概率分布的基尼指数定义为
Gini(p)=k=1∑Kpk(1−pk)=1−k=1∑Kpk2
显然,这就是样本点被错分的概率期望并进行加权,权重为pk。
对于二分类问题来说,如果样本点属于第一类的概率是p,那么第二类的概率就行1−p,代入到基尼指数为
Gini(p)=p(1−p)+(1−p)(1−(1−p))=2p(1−p)
如果对给定的样本集合D,可以分为两个子集C1和C2
Gini(D)=1−k=1∑2(∣D∣∣Ck∣)2
其中,Ck表示k类样本的个数,∣D∣∣C1∣就是p的经验值
CART算法生成二叉决策树是通过基尼指数挑选特征,但其实基尼指数可以用到多分类问题中
如果给定的样本集合D,可以分为K个子集:C1,C2,⋯,CK,其基尼指数
Gini(D)=1−k=1∑K(∣D∣∣Ck∣)
其中,∣D∣∣Ck∣就是pk的经验值
对于特征A条件下,样本集D的基尼指数为
Gini(D,A)=∣D∣∣D1∣Gini(D1)+∣D∣∣D2∣Gini(D2)
这里就是选定了特征A,并且将数据集中按照特征分成了两个数据集,再分别求它们对应的基尼指数
例:用基尼指数的最小化来选出最优特征
设有10个水蜜桃,其中5个好吃,5个不好吃,那么我们可以计算整个数据集的基尼指数
Gini(D)=2p(1−p)=2×21×21=0.5
假设,甜度大于0.2的有6个桃子,其中5个好吃,1个不好吃,甜度小于等于0.2的有4个桃子,都不好吃
![![[附件/Pasted image 20221005212139.png|200]]](https://p3-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/2584a8eec5a749d0a5580b5b8e587a6c~tplv-k3u1fbpfcp-zoom-in-crop-mark:1512:0:0:0.awebp)
分别计算D1,D2的基尼指数
Gini(D1)Gini(D2)=2×65×61=3610=2×40×44=0
计算甜度特征下的基尼指数
Gini(D,A)=ω1×3610+ω2×0=106×3610+104×0=0.17
假设,有5个硬桃子,其中2个好吃,3个不好吃,5个软桃子中,有3个好吃,2个不好吃。
![![[附件/Pasted image 20221006101345.png|500]]](https://p3-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/cac84af1efc24ff0a2b9b57a676003f5~tplv-k3u1fbpfcp-zoom-in-crop-mark:1512:0:0:0.awebp)
分别计算D1,D2的基尼指数
Gini(D1)Gini(D2)=2×52×53=2512=2×53×52=2512
计算甜度特征下的基尼指数
Gini(D,B)=21×2512+21×2512=0.48
通过比较可以看出
Gini(D,A)<Gini(D,B)
因此按照甜度分类时,我们选择硬度作为根节点
CART分类算法
如果输出变量是离散的,对应的就是分类问题;如果输出变量是连续的,对应的就是回归问题
分类树算法
输入:数据集D,特征集A,停止条件阈值ϵ
输出:分类决策树
-
从根节点出发,构建二叉树。
-
计算现有特征下对数据集D基尼指数,选择最优特征
- 在特征Ag下,对其可能取的每个值ag,根据样本点对Ag=ag的测试为“是”或“否”,将D分割成D1和D2两部分,计算Ag=ag时的基尼指数
- 选择基尼指数最小的那个值作为该特征下的最优切分点
- 计算每个特征下的最优切分点,并比较在最优切分下每个特征的基尼指数,选择基尼指数最小的那个特征,即最优特征
-
根据最优特征与最优切分点,从现结点生成两个子结点,将训练集依照特征分配到两个子结点中去
-
分别对两个子结点递归地调用上述步骤,直至满足停止条件(比如结点中的样本个数小于预定阈值,或样本集的基尼指数小于预定阈值(样本基本属于同一类),或者密友更多特征),即生成CART决策树
例:利用CART构建分类树
![![[附件/Pasted image 20221006101949.png|500]]](https://p3-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/e8e518ca312a46fea20a00a99ed01066~tplv-k3u1fbpfcp-zoom-in-crop-mark:1512:0:0:0.awebp)
训练集D,特征集分别是A1年龄,A2是否有工作,A3是否有自己的房子,A4信贷情况。类别为y1=是,y2=否
先用基尼指数的最小化选出最优特征
Gini(D,A)=∣D∣∣D1∣Gini(D1)+∣D∣∣D2∣Gini(D2)
选择年龄A1这个特征,由于有三个分类,根据CART算法规定,我们需要将其改为二分类
设青年A11,中年A12,老年A13
![![[附件/Pasted image 20221006102554.png|500]]](https://p3-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/409a62f2ec8b4e9ab2ed3f6bd657f25f~tplv-k3u1fbpfcp-zoom-in-crop-mark:1512:0:0:0.awebp)
划为青年和非青年,计算基尼指数
Gini(D1)Gini(D2)Gini(D,A11)=2×52×53=2512=2×107×103=10042=155×2512+1510×10042=0.44
同理以中年和非中年分类,以老年和非老年分列
Gini(D,A12)Gini(D,A13)=155×2×53×52+1510×2×106×104=0.48=155×2×54×51+1510×2×105×105=0.44
青年和老年基尼指数最小,都可以作为最优划分点,我们选择青年
选择工作A2这个特征
设有工作A21,无工作A22
![![[附件/Pasted image 20221006102759.png|500]]](https://p3-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/60a7ecf26bff4f1f8ffa4f93681053fd~tplv-k3u1fbpfcp-zoom-in-crop-mark:1512:0:0:0.awebp)
计算基尼指数
Gini(D,A2)=155×2×50×55+1510×2×104×106=0.32
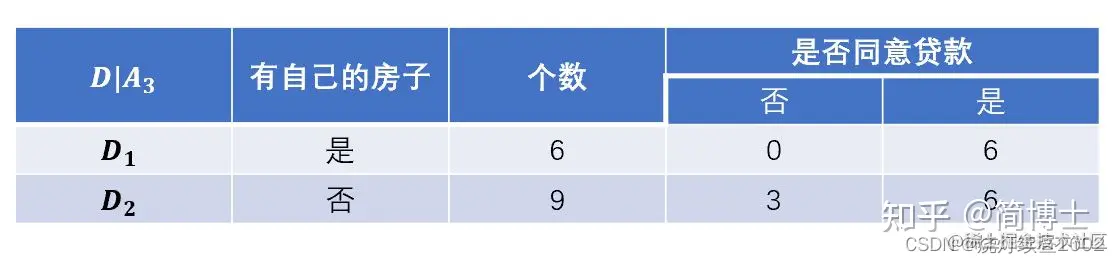
选择房子A3这个特征
设有房子A31,无房子A32
![![[附件/Pasted image 20221006103046.png|500]]](https://p3-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/8cf955ac579345aca834b533bf83abe0~tplv-k3u1fbpfcp-zoom-in-crop-mark:1512:0:0:0.awebp)
计算基尼指数
Gini(D,A3)=0+159×2×93×96=0.27
选择信贷情况A4这个特征
设非常好A41,好A42,一般A43三个特征值
![![[附件/Pasted image 20221006102759.png|500]]](https://p3-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/eec0faabade34bb48ff5353c84e0da3d~tplv-k3u1fbpfcp-zoom-in-crop-mark:1512:0:0:0.awebp)
计算基尼指数
Gini(D,A41)Gini(D,A42)Gini(D,A43)=0+1511×2×115×116=0.36=156×2×64×62+159×2×95×94=0.47=155×2×51×54+1510×2×108×102=0.32
一般的基尼指数最小,作为最优划分点
对比四个特征得到的基尼指数
| 特征值 | 基尼指数 |
|---|
| 年龄 | 0.44 |
| 工作 | 0.32 |
| 房子 | 0.27 |
| 信贷情况 | 0.32 |
因此我们选择房子,绘制二叉树
可以发现有房子的都同意贷款,因此这是一个叶结点。继续对无房子的数据集进行统计,按照年龄。工作、信贷情况来分类
在无房子数据集内,以年龄特征分类
| 年龄 | 个数 | 不同意贷款 | 同意贷款 |
|---|
| 青年 | 4 | 3 | 1 |
| 中年 | 2 | 2 | 0 |
| 老年 | 3 | 1 | 2 |
在无房子数据集内,以工作特征分类
| 工作 | 个数 | 不同意贷款 | 同意贷款 |
|---|
| 有工作 | 3 | 0 | 3 |
| 无工作 | 6 | 6 | 0 |
在无房子数据集内,以信贷情况特征分类
| 信贷情况 | 个数 | 不同意贷款 | 同意贷款 |
|---|
| 非常好 | 1 | 0 | 1 |
| 好 | 4 | 2 | 2 |
| 一般 | 4 | 4 | 0 |
显然房子作为特征的基尼指数为0,因此我们可以由房子继续构建二叉树
![![[附件/Pasted image 20221006103953.png|400]]](https://p3-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/75068c72419044d2aa9de3afc58ea46e~tplv-k3u1fbpfcp-zoom-in-crop-mark:1512:0:0:0.awebp)
回归树算法
由于是有监督的回归模型,因此我们应当对输入数据集进行划分,而不是划分输出
假设将输入空间划分成M个单元,R1,R2,⋯,RM,并在每个单元Rm上有一个固定的输出值cm,回归树模型可以表示为
f(x)=m=1∑McmI(x∈Rm)
这里的f(x)就是CART回归树模型,cm代表输出的类,I(x∈Rm)就是指示性函数
我们通过平方误差最小化来找到最优切分点。选择第x(j)个变量和取值s,分别作为切分变量和切分点,并定义两个区域
R1(j,s)R2(j,s)=x∣x(j)≤s=x∣x(j)>s
最小化平方误差就可以表示为
j,smin ⎣⎡c1min xi∈R1(j,s)∑(yi−c1)2+c2min xi∈R2(j,s)∑(yi−c2)2⎦⎤
这个公式意味着,将输出变量按照输入变量分为了两类,然后要求出来每次分类后的各个分类的平方误差最小值之和,也就意味着整体的最小平方误差,平方误差最小,意味着分类和实际最吻合。其中
c1^c2^=ave(yi∣xi∈R1(j,s))=ave(yi∣xi∈R2(j,s))
ci^就是每个区域输出变量的平均值
该算法停止可以认为划分到合适就停止,也可以整个都划分完,没有多余的点
例:利用CART构建回归树。甜度∈(0,1),好吃程度∈(0,10)
| 甜度 | 0.05 | 0.15 | 0.25 | 0.35 | 0.45 |
|---|
| 好吃程度 | 5.5 | 7.6 | 9.5 | 9.7 | 8.2 |
我们指定甜度为输入,好吃程度为输出
以甜度s=0.1进行划分
可以将表格里的连续数据划分为R1和R2两类
R1类是
R2类是
| 甜度 | 0.05 | 0.15 | 0.25 | 0.35 | 0.45 |
|---|
| 好吃程度 | 5.5 | 7.6 | 9.5 | 9.7 | 8.2 |
可得
c1^c2^xi∈R1(j,s)∑(yi−c1)2+xi∈R2(j,s)∑(yi−c2)2=5.5=47.6+9.5+9.7+8.2=8.75=3.09
以甜度s=0.2进行划分,平方误差和为3.53
以甜度s=0.3进行划分,平方误差和为9.13
以甜度s=0.4进行划分,平方误差和为11.52
因此我们选定s=0.1作为最优划分点,同时输出模型为
f(x)={5.58.75(s≤0.1)(s>0.1)
当然我们还可以对s>0.1区域进行回归划分,这就要取决于你的停止条件,如果说是继续分成三类,那么就可以按照相同的思路进行计算。
通过对连续变量进行划分,就可以转换为离散的变量来进行计算,那么就和之前的分类树模型也是相通的方法
剪枝算法
根据剪枝前后的损失函数来决定是否剪枝,剪枝后,如果损失函数减小,则意味着可以剪枝。
Cα=C(T)+α∣T∣
C(T)反映的是代价,是对训练数据的预测误差(比如基尼指数、平方误差),也就是模型的拟合能力;∣T∣反映的是模型的复杂度,体现的是泛化能力,∣T∣表示子树上叶结点的概述,叶结点越多,模型越复杂
α是一个决定拟合和泛化综合效果的参数
显然α的选取决定了整个决策树的样子
α可以从0取到+∞,我们将这个区间分成多个小区间,即
0≤α0<α1<α2<⋯<αn<αn+1<+∞
这时,令每一个α仅对应着一棵决策树。接着,我们把这些α按照左闭右开的形式划成小区间,即
α0=0,[α1,α2),[α2,α3),⋯,[αn,αn+1)
总共有n个区间,每个小区间都对应着一个决策树,我们记作
T0,T1,T2,⋯,Tn
这里T0就代表着α=0时完整的决策树,意味着没有剪枝。然而我们要找的是最优的决策树,其对应的αi使得损失函数Cα(Ti)最小
假设我们有一棵子树,叫做Tt,那么剪枝前的损失函数可以写成
Cα(Tt)=C(Tt)+α∣Tt∣
剪枝后变成一个叶结点,也就意味着此时∣T∣=1,那么损失函数可以写成
Cα(t)=C(t)+α
当α充分小,甚至α=0时,显然有
Cα(Tt)<Cα(t)
当α充分大,甚至α→+∞时,显然有
Cα(Tt)>Cα(t)
因此在[0,+∞)之间一定存在一个α,使得
Cα(Tt)=Cα(t)
在该α情况下,可得
α(∣Tt∣−1)αα=Cα(t)−C(t)=C(Tt)+α∣Tt∣−C(t)=C(t)−C(Tt)=∣Tt∣−1C(t)−C(Tt)
这里我们要先明确一点
Breiman等人证明:可以用递归的方法对树进行剪枝,将α从小到大排列,0=α0<α1<⋯<αn<+∞,产生一系列的区间,剪枝得到的子树序列对应着区间α∈[αi,αi+1),i=0,1,...,n的最优子树序列{T0,T1,T2,...,Tn},序列中的子树是嵌套的(即T1是T0的子树、T2是T1的子树)。
作者:猎人yy
链接:机器学习篇:(一)决策树_猎人yy的博客-CSDN博客
有说李航书中有写,但我好像看漏了……
这也告诉我们,每次一定可以只减一个结点,因为上面的α大于等于下面的α
这里有个疑问,根据这个原理,是否我们只需要计算每一个枝条最下面的叶结点的α,然后对比,谁小剪谁
实际上这个g(t)表示剪枝的阈值,即对于某一结点α,当总体损失函数中的参数α=g(t)时,剪和不剪总体损失函数是一样的(这可以在书中(5.27)和(5.28)联立得到)。这时如果α稍稍增大,那么不剪的整体损失函数就大于剪去的。即α大于g(t)该剪,剪了会使整体损失函数减小;α小于g(t)不该剪,剪了会使整体损失函数增大。
(请注意上文中的总体损失函数,对象可以是以α为根的子树,也可以是整个CART树,对α剪枝前后二者的总体损失函数增减是相同的。)
对于同一棵树的结点,α都是一样的,当α从0开始缓慢增大,总会有某棵子树该剪,其他子树不该剪的情况,即α超过了某个结点的g(t),但还没有超过其他结点的g(t)。这样随着α不断增大,不断地剪枝,就得到了n+1棵子树,接下来只要用独立数据集测试这n+1棵子树,试试哪棵子树的误差最小就知道那棵是最好的方案了。
作者:Zergzzlun - 知乎 (zhihu.com)
链接:cart树怎么进行剪枝? - 知乎 (zhihu.com)
因此对于CART算法生成的一个很大的决策树,其剪枝只是剪出了n+1个子树,告诉我们应该如果要剪枝,那么剪枝的顺序应该是什么,即从1到n+1
步骤
输入:CART算法生成的完整决策树
输出:最优决策树Tα
- 设k=0,T=T0也就是从完整的决策树出发
k表示迭代次数,这里从0开始,也就意味着还没开始迭代,那么树也是完整的,从这里开始出发。
-
设α=+∞,因为后面我们要比较大小,当损失函数小的时候可以剪枝。
-
自下而上的对各个内部结点t计算C(Tt),∣Tt∣,以及
g(t)=∣Tt∣−1C(t)−C(Tt),α=min(α,g(t))
这里g(t)代表了在这个结点对应的α值;C(t)代表了单结点时的误差;C(Tt)代表了子树时的误差
注意:此处的预测误差与我们之前所介绍的预测错误率不同,它还可以包括平方损失、基尼指数等。为了简便,后面例题中,我们还是以预测错误率来计算。
-
自下而上的方位内部结点t,如果有g(t)=α,则进行剪枝,并对叶结点t以多数表决法决定类,得到数T
-
接着增加迭代次数,继续调用,最终采用交叉验证法在子树T0,T1,T2,⋯,Tn中选取最优子树Tα
例题
![[[附件/Pasted image 20221006194325.png|300]]](https://p3-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/85d736041fab44f8a9b9e61380491725~tplv-k3u1fbpfcp-zoom-in-crop-mark:1512:0:0:0.awebp)
设k=0,T=T0,从完整的决策树开始,设置α=+∞,又有
g(t)=∣Tt∣−1C(t)−C(Tt),α=min(α,g(t))
因为内部节点有三个,我们可以把T0,T1,T2分别对应t=0,t=1,t=2,对于C(t)代表了单结点时的预测误差,这里因为我们选用的是预测错误率来计算
第一次迭代
对于T0子树而言,一共有17个样本点,其中8个正类,9个负类,如果按照多数表决来设置单结点的话,那么应该设为负类,这样误判的个数就为8,同时还要乘以这棵子树中样本点占总体的权重。 因此
C(0)=1717×178=178
接着求C(T0),可以看出在T0子树中,对应的6个叶子结点里,只有从左数第2个结点有1个误判。 因此
C(T0)=171
代入计算
g(0)=∣T0∣−1C(0)−C(T0)=4−1178−171=517
取
α=min(α,g(0))=min(+∞,517)=517
对于T1子树而言,一共有9个样本点,其中7个正类,2个负类,如果按照多数表决来设置单结点的话,那么应该设为正类,这样误判的个数就为2,同时还要乘以这棵子树中样本点占总体的权重。 因此
C(1)=179×92=172
接着求C(T1),可以看出在T1子树中,没有误判。因此
C(T1)=0
代入计算
g(1)=∣T1∣−1C(1)−C(T1)=3−1172−0=171
取
α=min(α,g(1))=min(517,171)=171
对于T2子树而言,一共有8个样本点,其中7个正类,1个负类,如果按照多数表决来设置单结点的话,那么应该设为负类,这样误判的个数就为1,同时还要乘以这棵子树中样本点占总体的权重。 因此
C(2)=178×81=171
接着求C(T2),可以看出在T2子树中,对应的2个叶结点中,没有误判,因此
C(T2)=0
代入计算
g(2)=∣T2∣−1C(2)−C(T2)=2−1171−0=171
取
α=min(α,g(2))=min(171,171)=171
可以看出,g(2)=g(1)=α=171,因此不妨对内部节点T2子树剪枝
![![[附件/Pasted image 20221006204150.png|300]]](https://p3-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/0fdd451a739f4090a6a37844477605af~tplv-k3u1fbpfcp-zoom-in-crop-mark:1512:0:0:0.awebp)
第二次迭代
对于T0子树而言,一共有17个样本点,其中8个正类,9个负类,如果按照多数表决来设置单结点的话,那么应该设为负类,这样误判的个数就为8,同时还要乘以这棵子树中样本点占总体的权重。 因此
C(0)=1717×178=178
接着求C(T1),这里就发生了一些不一样,可以看出在T0子树中,对应的三个叶结点里,对于T1结点而言,由于这里拿正类结点替代,那么误判个数就变成了2个,因此:
C(T0)=172
代入计算
g(0)=∣T0∣−1C(0)−C(T0)=3−1178−172=173
取
α=min(α,g(0))=min(171,173)=171
注意:在第二次迭代中,此时的α是第一轮中的结果,也就是171
对于T0子树而言,一共有9个样本点,其中7个正类,2个负类,如果按照多数表决来设置单结点的话,那么应该设为正类,这样误判的个数就为2,同时还要乘以这棵子树中样本点占总体的权重。 因此
C(1)=179× 92=172
接着求C(T1),可以看出在T1子树中,由于第一个叶结点属于正类,误判了1个。 因此:
C(T1)=171
个人理解,这里也是加权过的,即
C(T1)=179×91=171
代入计算
g(1)=∣T1∣−1C(1)−C(T1)=2−1172−171=171
取
α=min(α,g(1))=min(171,171)=171
可以看出,这里的T1子树对应的α是最小值,意味着对T1剪枝
![![[附件/Pasted image 20221006210016.png|300]]](https://p3-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/cc0e7f7dfd82433cbd4b3f1eca173370~tplv-k3u1fbpfcp-zoom-in-crop-mark:1512:0:0:0.awebp)
第三次迭代
对于T0子树而言,一共有17个样本点,其中8个正类,9个负类,如果按照多数表决来设置单结点的话,那么应该设为负类,这样误判的个数就为8,同时还要乘以这棵子树中样本点占总体的权重。 因此
C(0)=1717×178=178
接着求C(T1),这里就发生了一些不一样,可以看出在T0子树中,对应的两个叶结点里,对于T1结点而言,由于这里拿正类结点替代,那么误判个数就变成了3个,因此:
C(T0)=173
代入计算
g(0)=∣T0∣−1C(0)−C(T0)=3−1178−173=175
取
α=min(α,g(0))=min(171,175)=171
T0子树对应的不是最小α,因此不剪枝,同时根节点满足两个叶结点的停止条件,剪枝结束


