word2vec过程详解
本文将对文章word2vec Parameter Learning Explained ——Xin Rong进行解读
摘要
word2vec是一种词嵌入模型,对单词进行one-hot编码得到的序列数据训练,得到d维空间上的词向量,从而得到降维的效果。word2vec核心思想是根据多类分类任务构建模型,而词嵌入只是其中的一个副产物。word2vec包含两个模型,分别为CBOW(Continuous Bag-of-Word Model)和SG(skip-gram Model)。两种模型的思路一样,但损失函数稍微有点不一样。在看本文前,需要的前提知识:
- 了解一些经典的机器学习流程。
- 了解损失函数和梯度下降法的含义。
- 了解one-hot编码。
- 了解多分类任务,softmax交叉熵损失的意义。
- 了解稀疏概念。
- 了解条件概率。
一个机器学习模型的构建流程关键在于:
- 定义输入数据的类型。
- 定义计算过程。
- 定义损失函数。
- 定义参数更新方法。
1 Continuous Bag-of-Word Model
CBOW模型是基于上下文对中心词进行预测,首先基于one-hot编码对单词进行数据化,再投入到模型训练,得到的模型参数为降维后的词向量。
| 符号 | 说明 |
|---|
| V | 词典单词数 |
| N | 隐藏元个数(降维维度d) |
1.1 One-word context
我们先讨论一个单词的任务。一个单词的任务主要思想是:降维后的词向量需要保持单词在词典中的位置信息。首先我们贴上一张过程图,随后对图的过程进行详解。
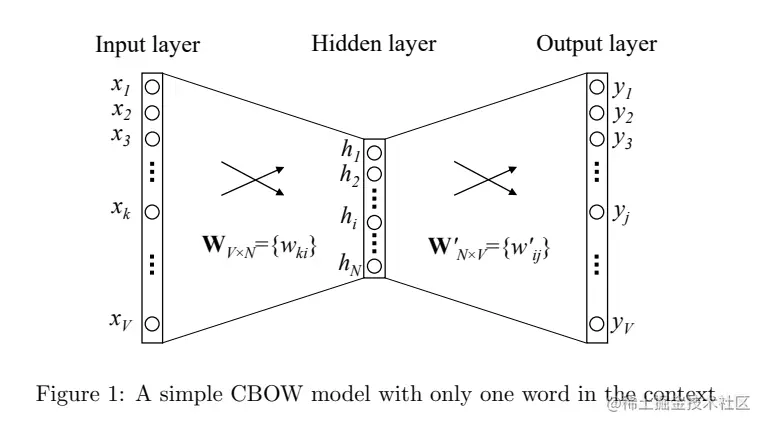
Step1、定义输入模型的数据(one-hot编码)
给定一个单词x=“真香”,假设词典中单词数为V个,假设x位于词典中第二个词,则根据one-hot编码可得,x=[0,1,0,0,⋯,0],第二个位置编码为1,其他为0。目的是将X进行降维。
Step2、前向计算,定义两个将向量进行"稠密化"的矩阵。
第一次计算:定义Input→Hidden的矩阵W,定义W矩阵维度为V×N。
h=WTx=W(k,)T:=vwIT
其中vwIT定义为降维后的单词向量,原文的意思是“is the vector representation of input word”,为了更直观的看出计算过程,将以"真香"为例,计算过程如下:
h=WTx=⎣⎡w11w21⋮wV1w12w22⋮wV2⋯⋯⋱⋯w1Nw2N⋮wVN⎦⎤T⎣⎡01⋮0⎦⎤=⎣⎡w11w12⋮w1Nw21w22⋮w2N⋯⋯⋱⋯wV1wV2⋮wVN⎦⎤⎣⎡01⋮0⎦⎤=⎣⎡w21w22⋮w2N⎦⎤
即:
hT=vwI=[w21w22⋯w2N]
第二步计算:定义Hidden→Output的矩阵W′,定义W′矩阵维度为N×V,该矩阵的意义是将h映射为和一开始输入one-hot变量一样长度为V的向量进行输出,从而可以定义交叉熵损失函数。将以"真香"为例,计算过程为:
u=W′Th=⎣⎡w11′w21′⋮wN1′w12′w22′⋮wN2′⋯⋯⋱⋯w1V′w2V′⋮wNV′⎦⎤T⎣⎡w21w22⋮w2N⎦⎤=⎣⎡w11′w12′⋮w1V′w21′w22′⋮w2V′⋯⋯⋱⋯wN1′wN2′⋮wNV′⎦⎤⎣⎡w21w22⋮w2N⎦⎤=⎣⎡k=1∑Nw2kwk1′k=1∑Nw2kwk2′⋮k=1∑Nw2kwkN′⎦⎤V×1=⎣⎡u1u2⋮uV⎦⎤
化简上式,即为:
uj=vwj′Th
其中vwj是W′的第j列
第三步计算:定义Output的激活函数softmax。注意我们的任务是一个分类任务,而不是一个词嵌入任务,因此我们需要将第二步计算得到的uj进行softmax映射,得到总和为1的数值,定义得到的最终输出为:(此处需要了解softmax交叉熵损失函数具体参考简单的交叉熵损失函数,你真的懂了吗? - 知乎 (zhihu.com))
p(wj∣wI)=yj=∑j′=1Vexp(uj′)exp(uj)(1)
(注意此处是一个单词的模型)还是以"真香"为例,我们输入x=“真香”,x=[0,1,0,0,⋯,0]。
- 从图中可以看出,输出层有V个y值,根据多分类任务的思想,我们取最大的yj,输出结果则为成功分类到第j类。
- 因此word2vec构建的模型可以看作是V类分类任务(V是词典中的单词数)。
- 为了保持降维后的词向量是拥有在词典中的位置信息的,因此word2vec模型的目标是最大化y2(因为"真香"位于第二个位置)。
那么有人就可能问了,输入一个词,构建一个模型分类识别出是这个词,那不是多此一举吗?
答:并不是多此一举,word2vec的目标产物并不是最终层的输出,而是模型的副产物,中间隐藏层WV×N和WN×V′,如输入”真香“,训练得到的对应模型参数W后,我们可以计算
从而查询“真香"对应的词向量为
hT=vwI=[w21w22⋯w2N]
Step3、损失函数,从上述我们可以知道word2vec模型实际是一个分类任务,首先我们将公式(1)进行转化,带入uj的实际值,得到:
p(wj∣wI)=∑j′=1Vexp(vwj′TvwI)exp(vwj′TvwI)
定义损失函数E为:
maxp(wO∣wI)=maxyj∗=maxlogyj∗=uj∗−logj′=1∑Vexp(uj′):=−E,
其中j∗为输入词在词典的真实位置,如真香的位置是2,因此j∗=2,从损失函数的定义可以看出,以真香为例,我们想要最大化y2。
Step4、方向传播参数更新:word2vec模型采用梯度下降法进行参数更新,由于本文是对word2vec的过程详解,主导过程的详解,因此将不详细进行推导,有兴趣的同学可以去看原文。
1.2 Multi-word context
本节我们将讨论多个单词的模型。在1.1节中,我们讨论了一个单词的模型,在一个单词模型中,word2vec只使用了单词在词典的位置信息。由于一个单词不可能是独立出现的,而是随着句子出现的,因此我们还可以利用单词在句子中的位置:即上下文。如将对句子"螺蛳粉真香啊"进行训练,首先对句子进行分词,分为"螺蛳粉",”真香“,”啊",我们假设"螺蛳粉"在词典的第1个位置,“啊”在第3个位置(这样假设是为了我写one-hot编码得到的向量)。同样,我们先贴一张过程图。
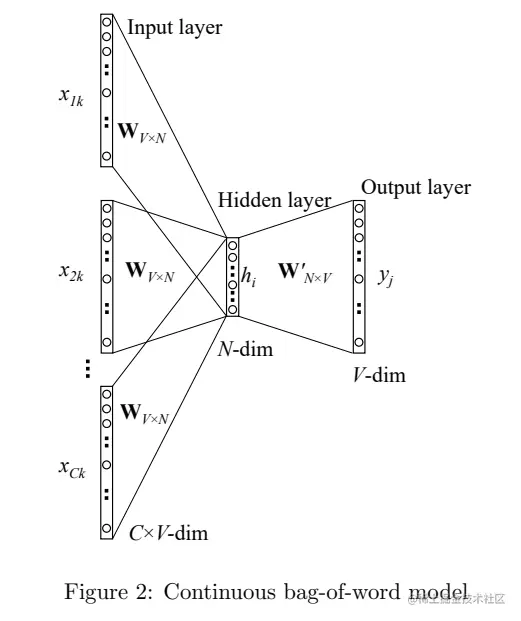
Step1、定义输入模型的数据(one-hot编码)
- "螺蛳粉":x1=[1,0,0,0,⋯,0]
- ”真香“:x2=[0,1,0,0,⋯,0]
- ”啊":x3=[0,0,1,0,⋯,0]
和一个单词模型(输入和输出目标一样),不一样的是:模型目标为输入x1,x3,预测中心词x2
Step2、和一个单词模型的Step1大致一样,不同的是在隐藏层中,我们将对得到的值进行平均化操作
h=21WT(x1+x3)=21(vw1+vw3)T
Step3、由于是分类"真香",因而和一个单词模型的损失函数一样,目标是让y2值最大化
E=−logp(wO∣wI,1,⋯,wI,C)=−uj∗+logj′=1∑Vexp(uj′)=−vwO′T⋅h+logj′=1∑Vexp(vwj′T⋅h)
Step4、同样为反向传播,梯度下降法。
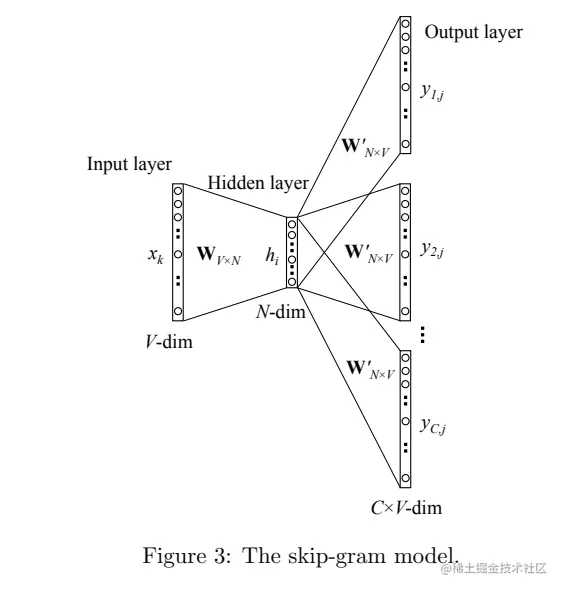
2 Skip-Gram Model
Skip-Gram Model 的思想是利用中心词预测上下文,具体操作是对损失函数进行修改。同样以句子"螺蛳粉真香啊"举例,首先对句子进行分词,分为"螺蛳粉",”真香“,”啊"。我要预测出”真香“的上下文,即预测出”螺蛳粉“,”啊“。
因此模型修改为模型目标为输入中心词x2,预测上下文x1,x3,根据one-hot编码信息,和下图对应的位置,我们需要对y11和y23最大化(因为y1,j对应的是x1,y2,j对应的是x3)。
其他过程类似,对应的损失函数修改为:
E=−logp(wO,1,wO,2,⋯,wO,C∣wI)=−logc=1∏C∑j′=1Vexp(uj′)exp(uc,jc∗)=−c=1∑Cujc∗+C⋅logj′=1∑Vexp(uj′)
存在的缺陷
- word2vec模型的参数量很大,如2万个词的词典,降维设定为256维,则W矩阵将有20000×256
- 损失函数计算量过大,因为word2vec实际上是一个分类任务,如果是2万个词的词典,将对应2万类的分类模型,计算Softmax中的∑j′=1Vexp(vwj′TvwI)将变得十分困难。
目前word2vec采用的两种加速方法:Hierarchical Softmax,Negative Sampling。均是解决Softmax中的问题,有兴趣的同学自行了解。


