函数参数
函数参数之位置参数
* 当子代码只有一行并且很简单的情况下 可以直接在冒号后编写 不用换行
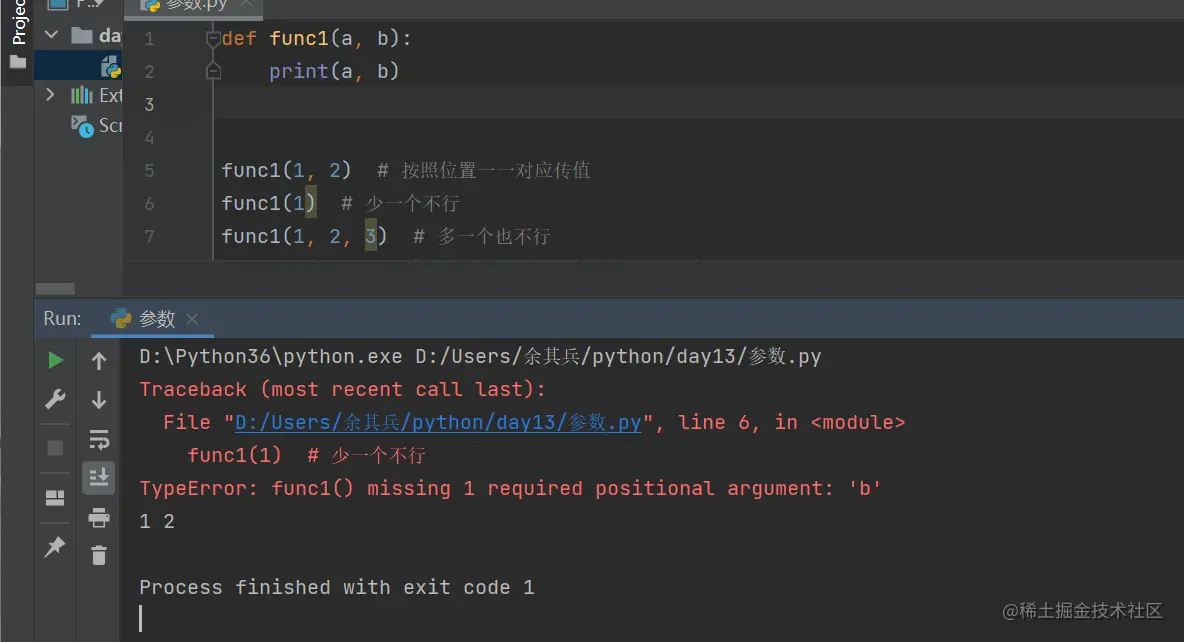
* 位置形参:函数定义阶段括号内从左往右依次填写的变量名
def func(a,b,c):pass
* 位置实参:函数调用阶段括号内从左往右依次填写的数据值
func1(1, 2, 3)
越短的越简单的越靠前
越长的越复杂的越靠后
但是遇到下列的情况除外
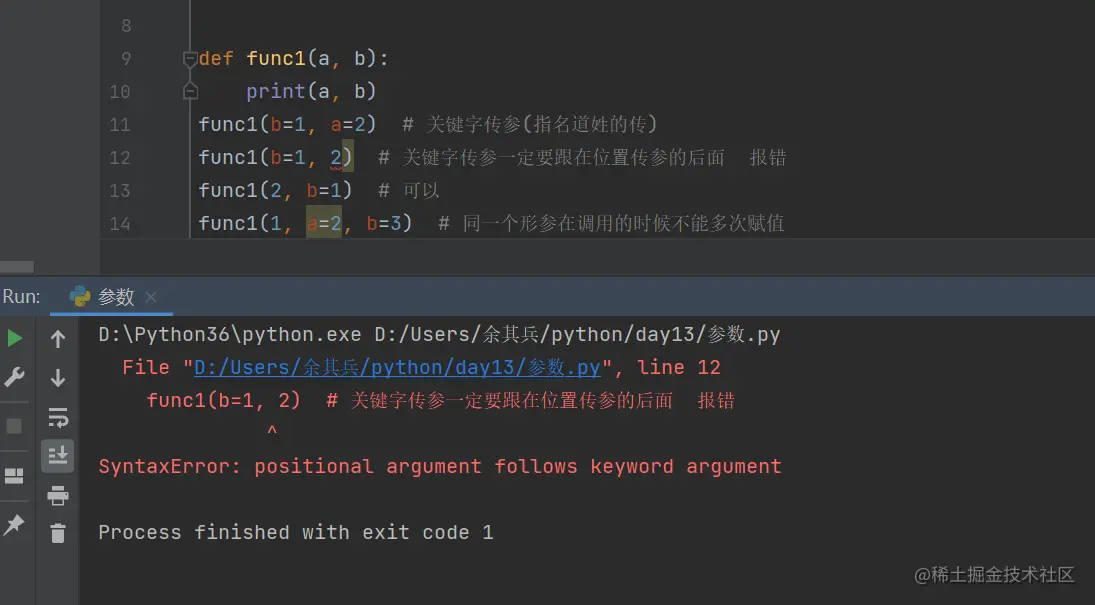
同一个形参在调用的时候不能多次赋值
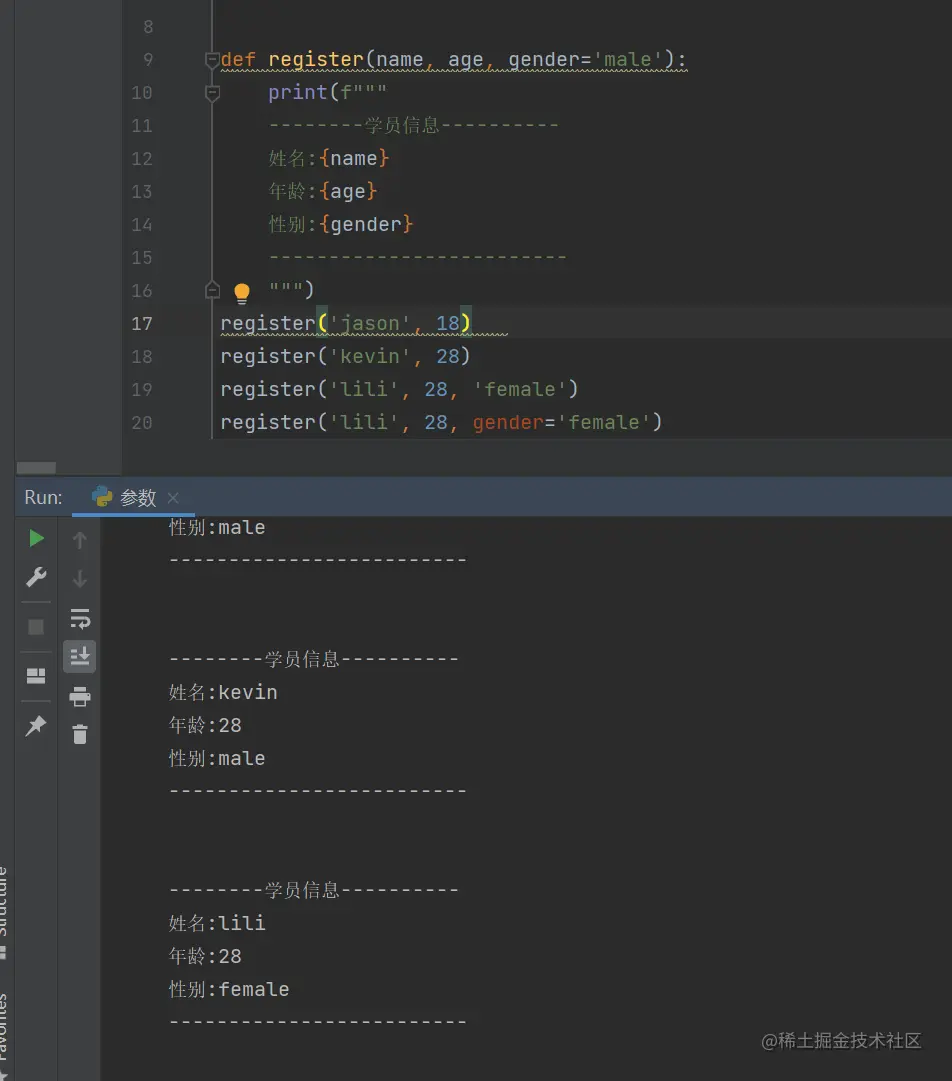
函数参数之默认参数
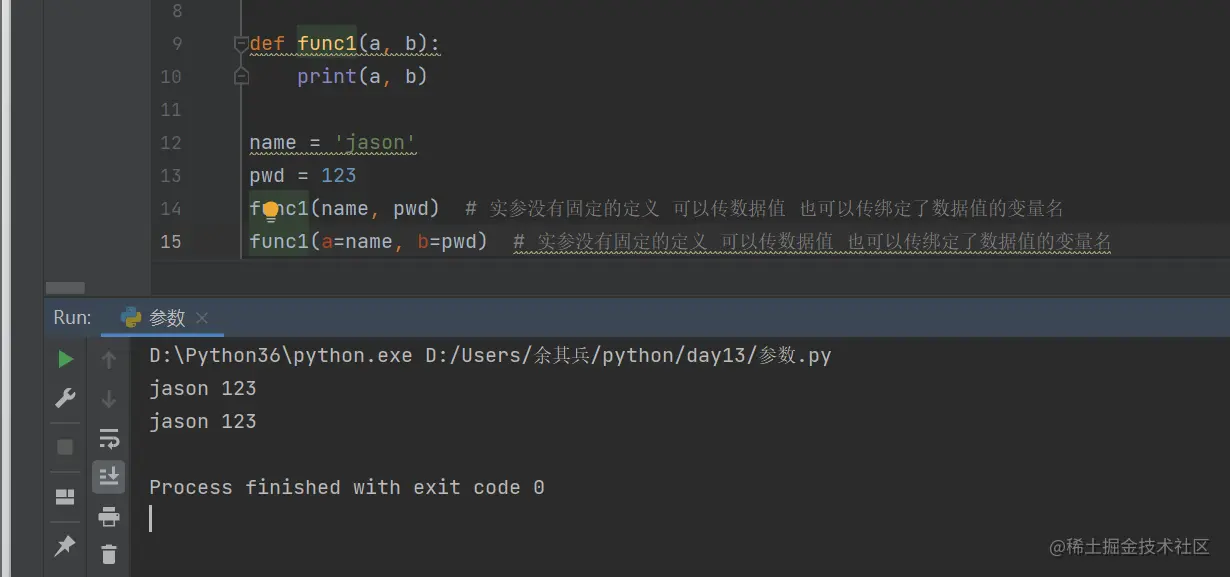
* 本质其实就是关键之形参
别名叫默认参数:提前就已经给了 可以不传也可以传
默认参数的定义也遵循短的简单的靠前 长的复杂的靠后
函数参数之可变长参数
| 名称 | 形参 | 实参 |
|---|
| * | *号会把溢出的位置存成元组,然后赋值其后的形参名 | *号会把值打散,字符串会变成单个字符.... |
| ** | **号会把溢出来的关键字实参存成字典,然后赋值其后的形参名 | **只能跟字典,只能将字典的key进行打散 |
由于*和**在函数的形参中使用频率很高 后面跟的变量名推荐使用
*args
**kwargs
def index(*args,**kwargs):pass
def func1(*a):
print(a)
func1() ()
func1(1) (1,)
func1(1,2) (1, 2)
def func2(b, *a):
print(a, b)
func2() 函数至少需要一个参数给到b
func2(1) () 1
func2(1, 2, 3, 4) (2, 3, 4) 1
"""
*号在形参中
用于接收多余的位置参数 组织成元组赋值给*号后面的变量名
"""
def func3(**k):
print(k)
func3() {}
func3(a=1) {'a': 1}
func3(a=1, b=2, c=3) {'a': 1, 'b': 2, 'c': 3}
def func4(a, **k):
print(a, k)
func4() 函数至少需要一个参数给到a
func4(a=1) 1 {}
func4(a=1, b=2, c=3) 1 {'b': 2, 'c': 3}
func4(a=1, b=2, c=3, x='jason', y='kevin') 1 {'b': 2, 'c': 3, 'x': 'jason', 'y': 'kevin'}
**号在形参中
用于接收多余的关键字参数 组织成字典的形式赋值给**号后面的变量名
def func5(*a, **k):
print(a, k)
func5() () {}
func5(1, 2, 3) (1, 2, 3) {}
func5(a=1, b=2, c=3) () {'a': 1, 'b': 2, 'c': 3}
func5(1, 2, 3, a=1, b=2, c=3) (1, 2, 3) {'a': 1, 'b': 2, 'c': 3}
def func5(n, *a, **k):
print(a, k)
func5() 函数至少需要一个参数给到n
func5(1, 2, 3) (2, 3) {}
func5(111,a=1, b=2, c=3) () {'a': 1, 'b': 2, 'c': 3}
func5(n=111,a=1, b=2, c=3) () {'a': 1, 'b': 2, 'c': 3}
func5(a=1, b=2, c=3, n=111) () {'a': 1, 'b': 2, 'c': 3}
func5(1, 2, 3, a=1, b=2, c=3) (2, 3) {'a': 1, 'b': 2, 'c': 3}
函数参数之可变长实参
def index(a, b, c):
print(a, b, c)
l1 = [11, 22, 33]
t1 = (33, 22, 11)
s1 = 'tom'
se = {123, 321, 222}
d1 = {'username': 'jason', 'pwd': 123, 'age': 18}
将列表中三个数据值取出来传给函数的三个形参
index(l1[0], l1[1], l1[2])
index(*l1) # index(11, 22, 33)
index(*t1) # index(33, 22, 11)
index(*s1) # index('t','o','m')
index(*se) # index(321 123 222)
index(*d1) # index('username','pwd','age')
*在实参中
类似于for循环 将所有循环遍历出来的数据按照位置参数一次性传给函数
def index(username, pwd, age):
print(username, pwd, age)
d1 = {'username': 'jason', 'pwd': 123, 'age': 18}
index(username=d1.get('username'), pwd=d1.get('pwd'), age=d1.get('age'))
index(**d1) # index(username='jason',pwd=123,age=18)
**在实参中
将字典打散成关键字参数的形式传递给函数
def index(*args, **kwargs):
print(args) (11, 22, 33, 44)
print(kwargs) {}
index(*[11, 22, 33, 44]) index(11, 22, 33, 44)
index(*(11, 22, 33, 44)) index(11, 22, 33, 44)
名称空间
名称空间就是用来存储变量名与数据值绑定关系的地方(我们也可以简单的理解为就是存储变量名的地方)
* 内置空间:解释器运行自动产生 里面包含了很多名字
内置名称空间:python解释器启动则创建 关闭则销毁
内置名称空间:解释器级别的全局有效
* 全局名称空间:Py文件存放文件级别的名字
全局名称空间:py文件执行则创建 运行结束则销毁
全局名称空间:py文件级别的全局有效
* 局部名称空间:函数体代码运行\类体代码运行 产生的空间
局部名称空间:函数体代码运行创建 函数体代码结束则销毁
局部名称空间:函数体代码内有效
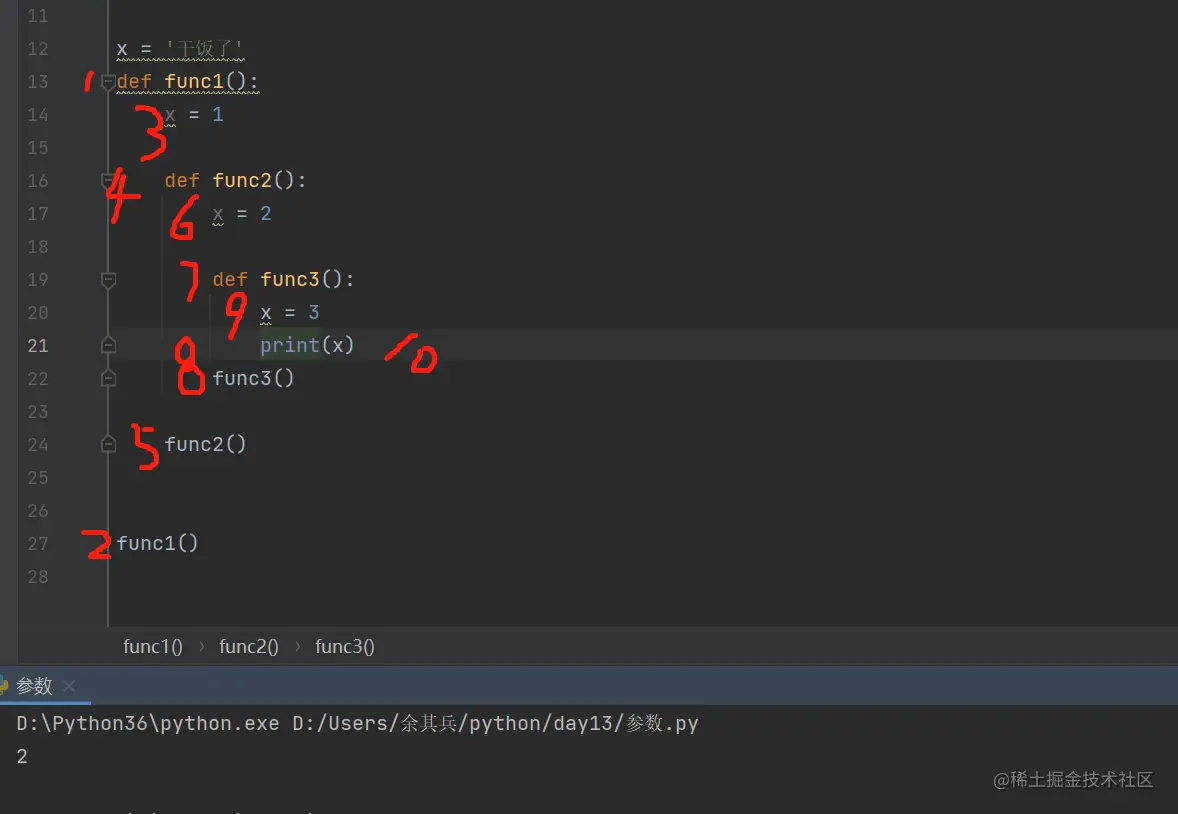
名字查找顺序
涉及到名字的查找 一定要先搞明白自己在哪个空间
1.当我们在局部名称空间中的时候
局部名称空间 >>> 全局名称空间 >>> 内置名称空间
2.当我们在全局名称空间中的时候
全局名称空间 >>> 内置名称空间
其实名字的查找顺序是可以打破的
查找顺序案例
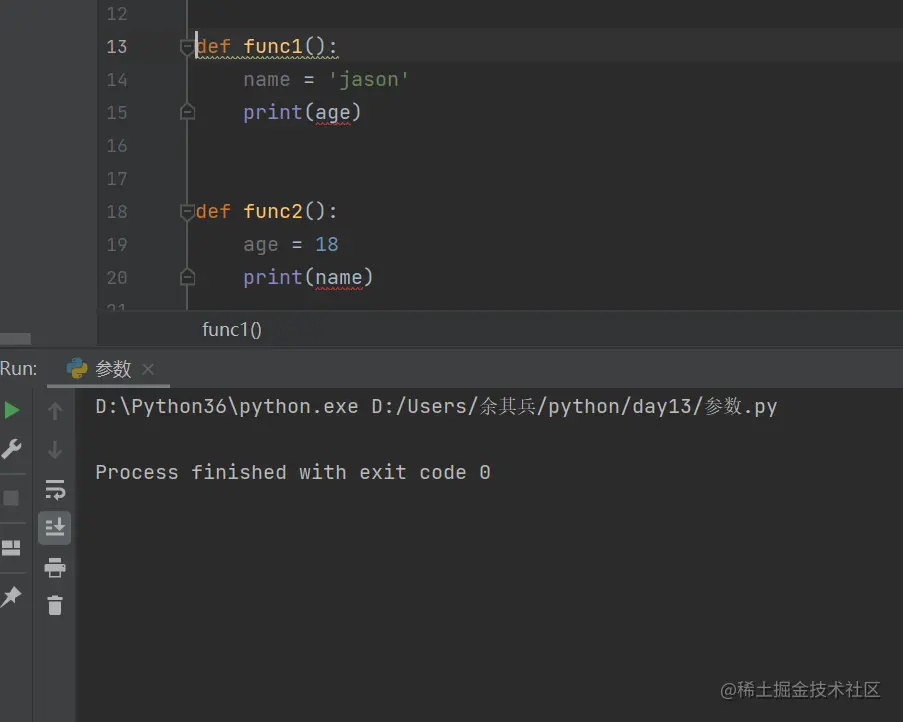
- 局部名称空间嵌套
先从自己的局部名称空间查找 之后由内而外依次查找
函数体代码中名字的查找顺序在函数定义阶段就已经固定死了