

持续创作,加速成长!这是我参与「掘金日新计划 · 10 月更文挑战」的第6天,点击查看活动详情 信息泄露在ctf web题里算是特别基础的了。这次来学习一下,
web1
以下关卡全是这样的形式:页面只有这一句话:where is flag?
鼠标右键查看网站源码,得到flag
web2
提示说:js前台拦截 === 无效操作
无脑bp抓包,send to repeater,找到flag
web3
提示:找不到flag就抓个包试试。和第二题思路一毛一样。
web4
提示:总有人把后台地址写入robots,帮黑阔大佬们引路
之前buu的入门题,还有点印象,URL后面加上/robots.txt
于是无脑在URL后面加上Disallow后面那一串,得到flag.再百度一下robot协议加深一下印象。
robots协议也称爬虫协议、爬虫规则等,是指网站可建立一个robots.txt文件来告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取。看完这一句,这个题就明白了,disallow后面的页面是只有在URL后面加上robots.txt才看完一抓取的。
web5
提示说源码泄露有时候能帮上忙,于是域名后面加上index.phps,是个文件,打开,下载以后用记事本打开,发现flag
web6
源码啥也没有,bp抓包也没任何发现,遇事不决扫目录。用dirsearch浅扫一下
直接就是一个大发现,有个www.zip文件,打开,下载,一气呵成
flag就在里面
web7
用dirsearch扫一下目录,发现有隐藏文件,访问直接得到flag,看提示,这个应该是属于git泄露
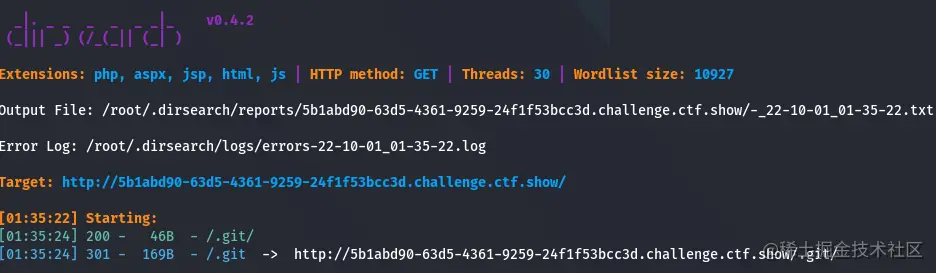 web8
web8
一样的思路,dirsearch扫目录,发现/.svn文件,打开就有了flag
web9
这个考察的是vim缓存
临时文件是在vim编辑文本时就会创建的文件,如果程序正常退出,临时文件自动删除,如果意外退出就会保留,当vim异常退出后,因为未处理缓存文件,导致可以通过缓存文件恢复原始文件内容 以 index.php 为例 第一次产生的缓存文件名为 .index.php.swp第二次意外退出后,文件名为.index.php.swo第三次产生的缓存文件则为 .index.php.swn。
URL后面加上.index.php.swn,生成了一个文件,我用的notepad++打开,flag就在里面。
web10
看提示,flag应该是跟cookie有关,那就看一下这个网页的cookie,不看不知道,一看就发现了flag,
等等,这个形式貌似有点问题,打开ctf工具箱。
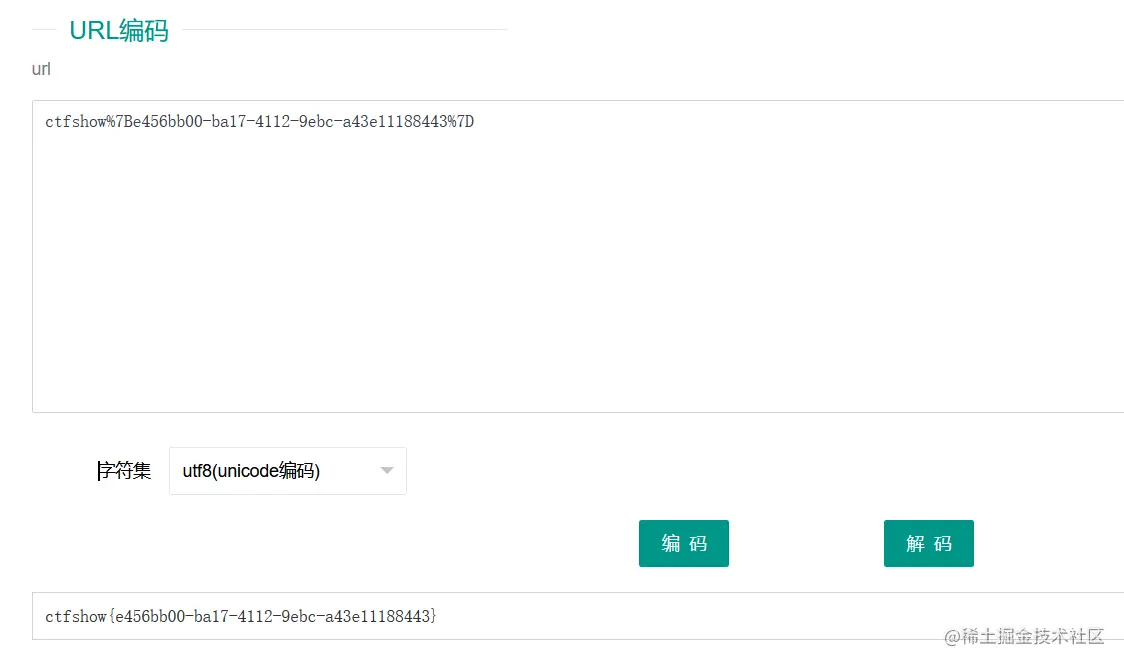 ok,大功告成。
ok,大功告成。
web12
查看robots.txt文件,访问/admin/弹出一个登录框:
但是密码呢?我们看一下这个题目的描述:有时候网站上的公开信息,就是管理员常用密码
他的意思就是让我们在网页里找密码,果然,我们翻到最下面,看见了一串数字
试一下,登陆成功。flag就在里面。
