字典相关操作
* 类型转换:dict() 字典的转换一般不使用关键字 而是自己动手转
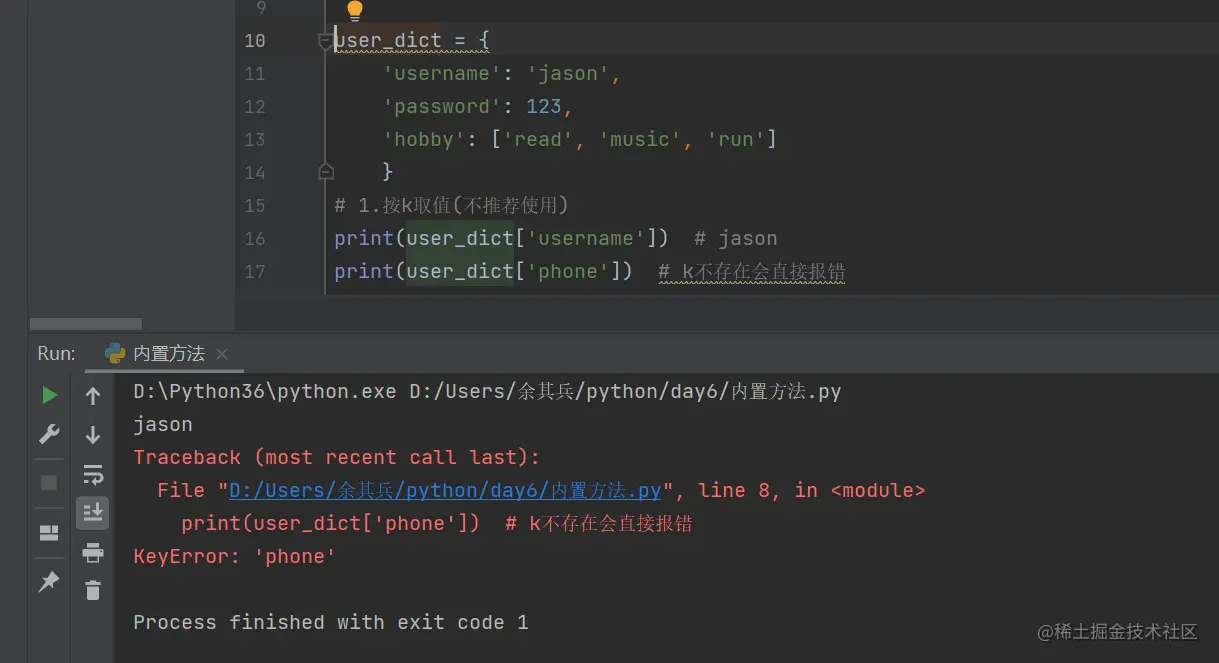
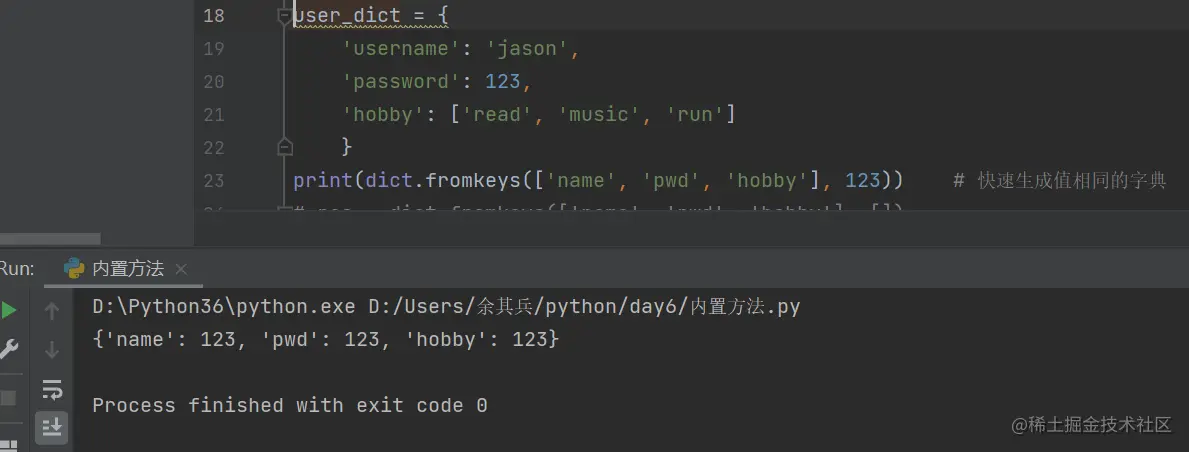
1.按k取值(不推荐使用)
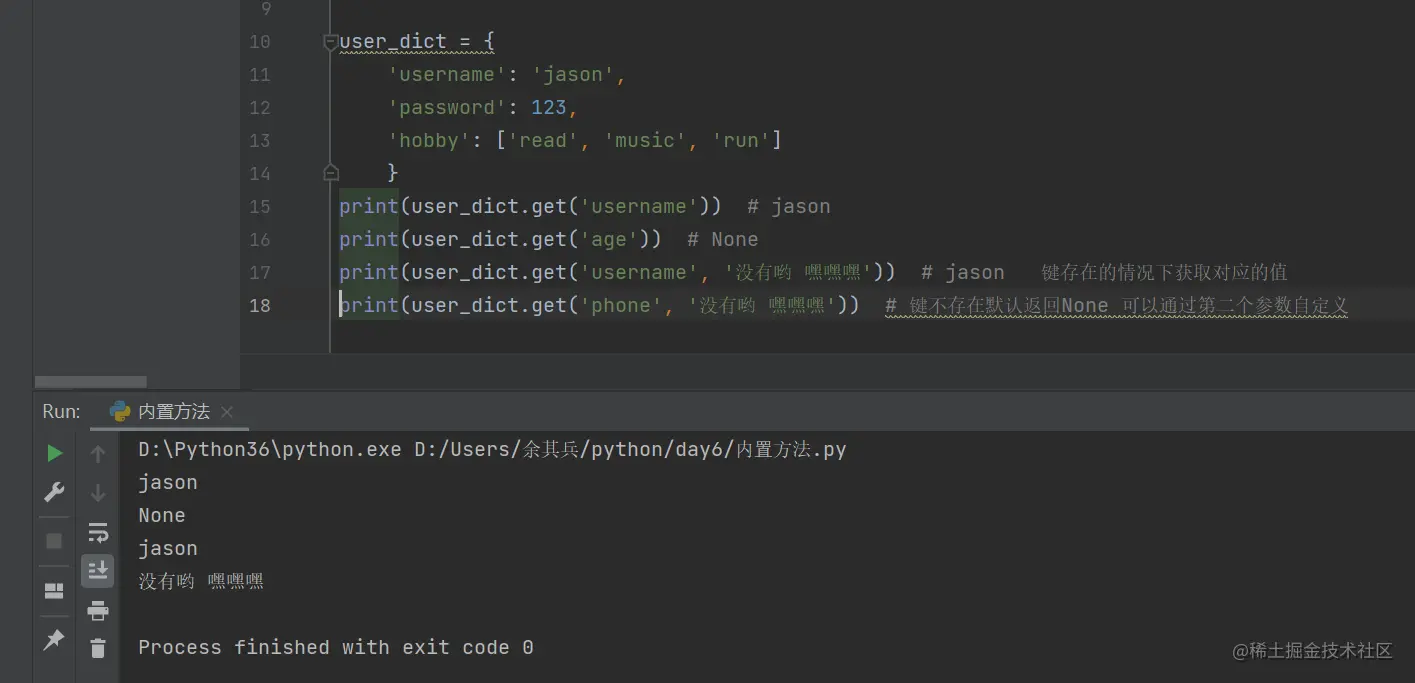
按内置方法get取值(推荐使用)
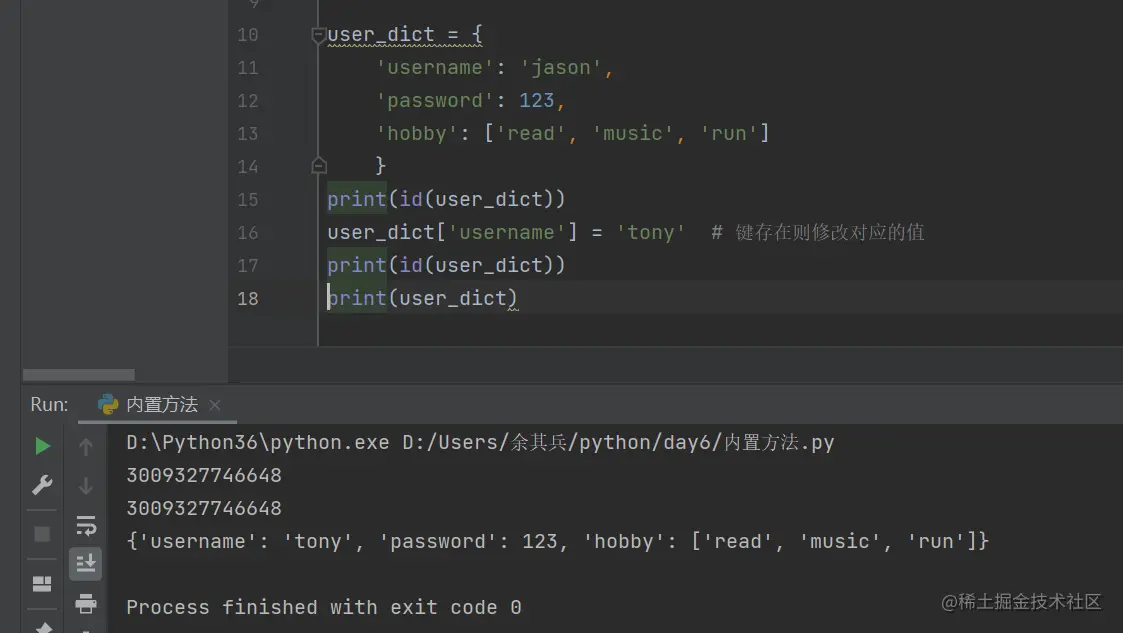
修改值数据
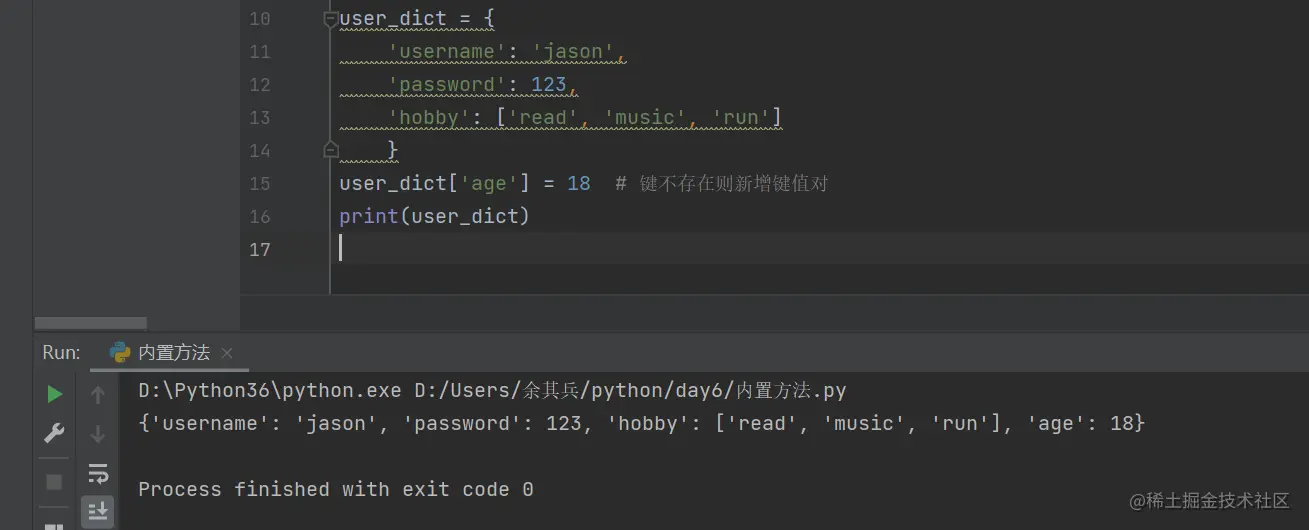
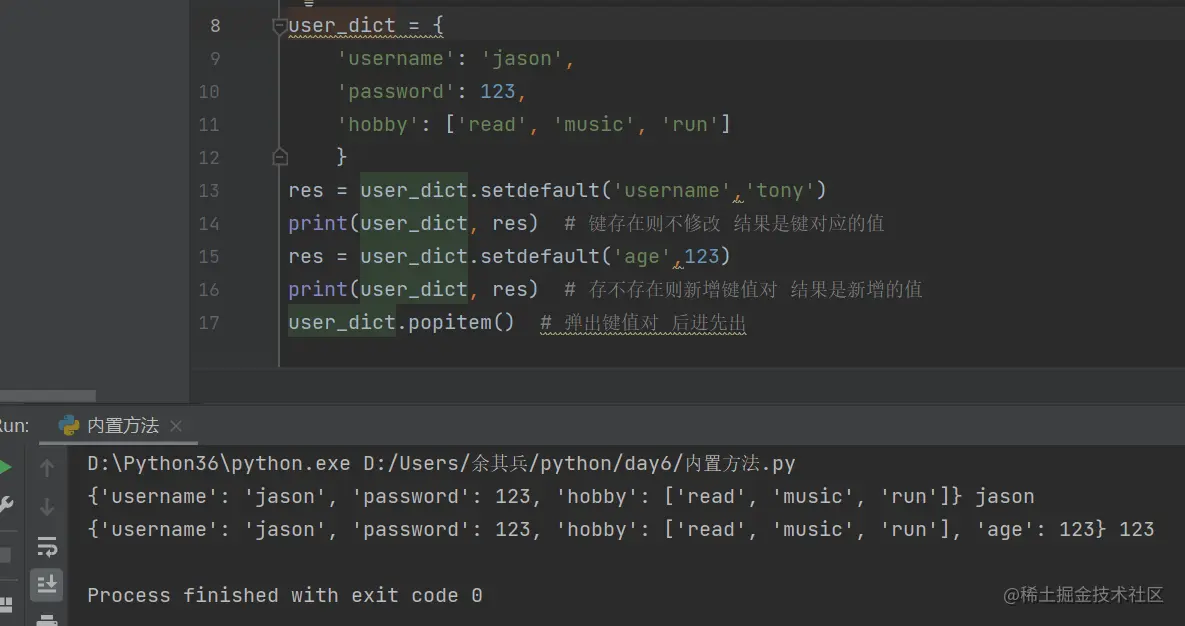
新增键值对
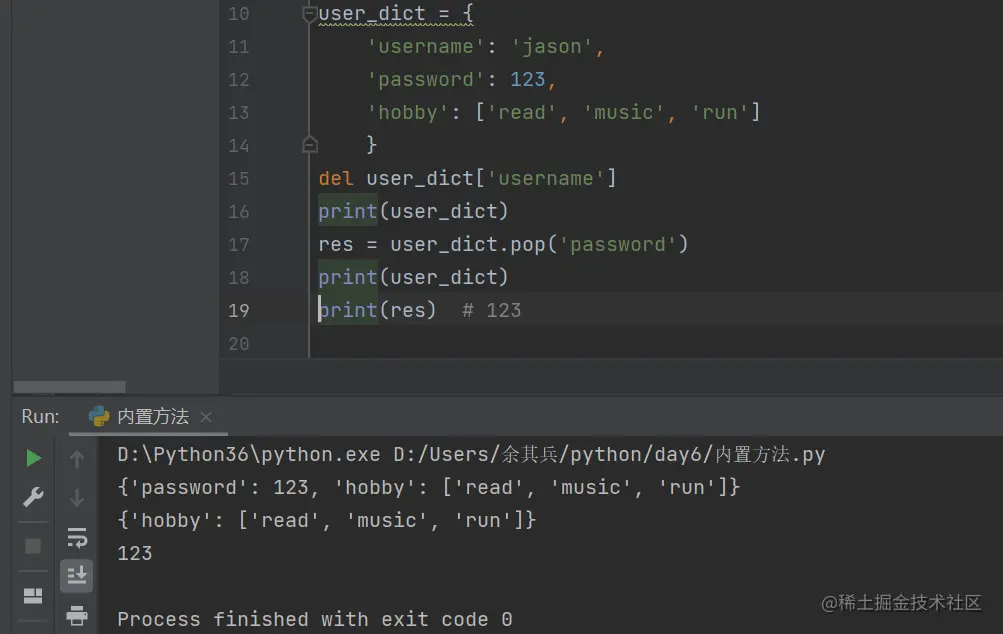
删除数据
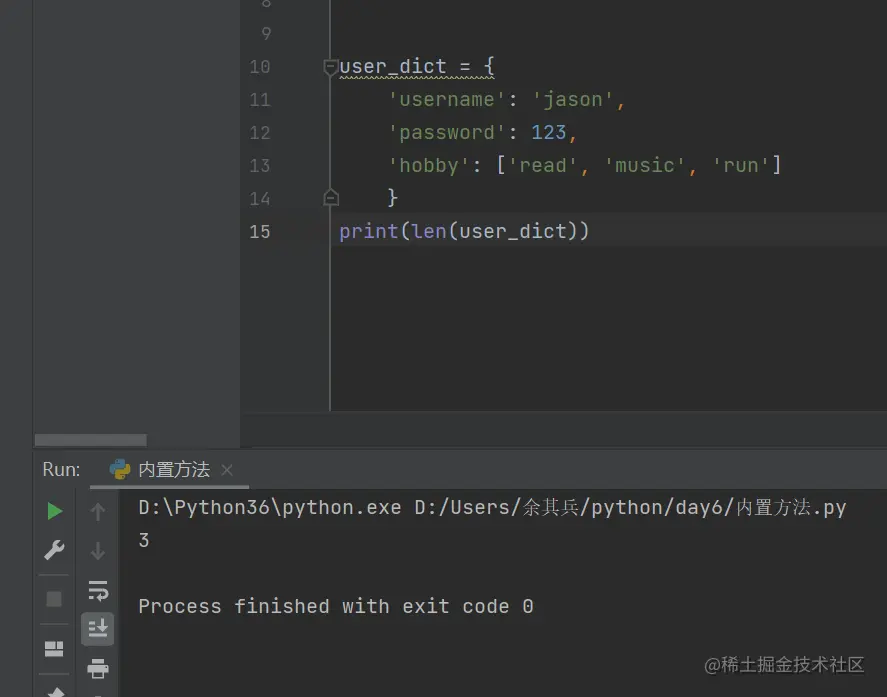
统计字典中键值对的个数
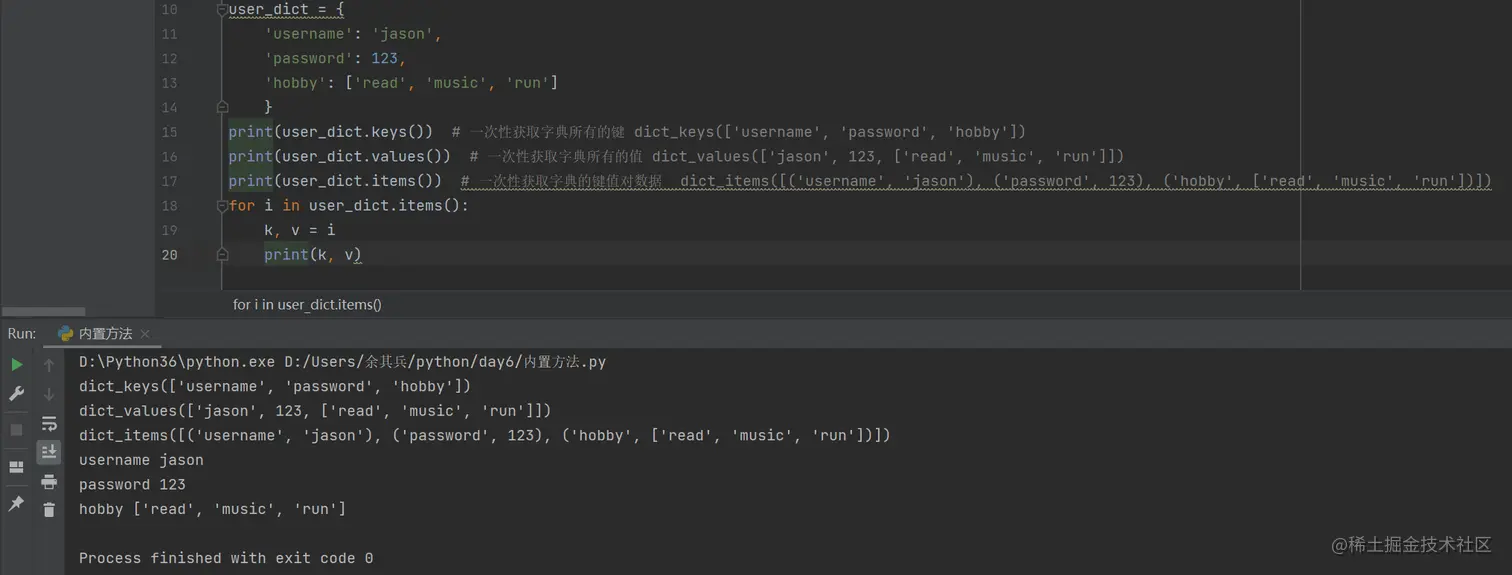
字典三剑客
补充说明
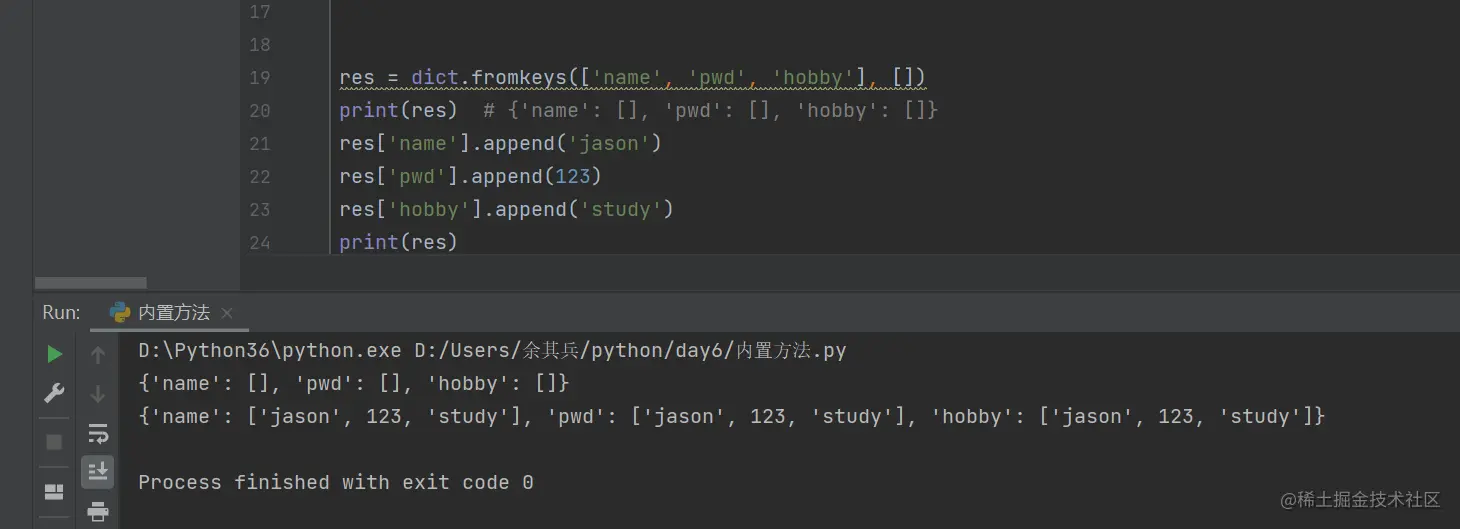
当第二个公共值是可变类型的时候 一定要注意 通过任何一个键修改都会影响所有
元组相关操作
* 类型转换tuple 支持for循环的数据都可以转成元组
* 元组必须掌握的方法
t1 = (11, 22, 33, 44, 55, 66)
1.索引取值
2.切片操作
3.间隔、方向
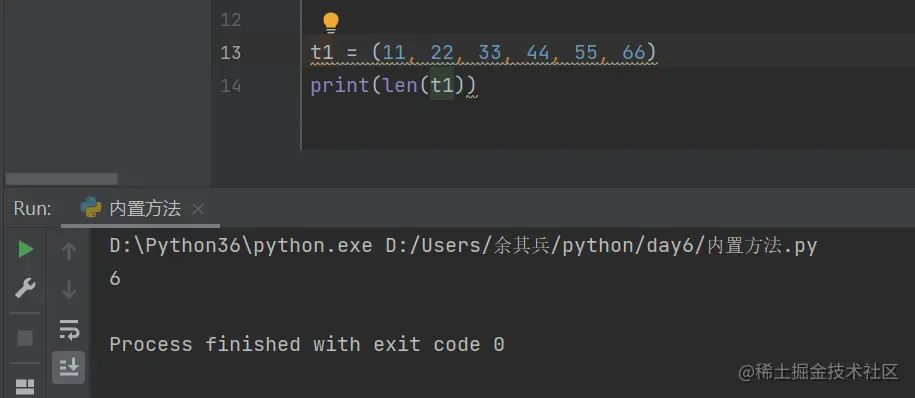
4.统计元组内数据值的个数
5.统计元组内某个数据值出现的次数
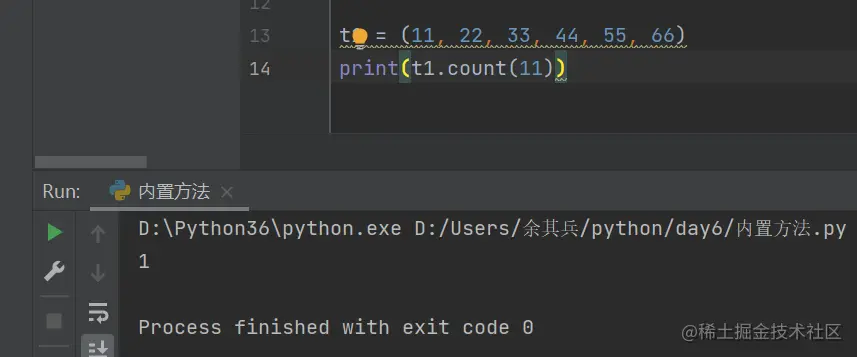
6.统计元组内指定数据值的索引值
7.元组内如果只有一个数据值那么逗号不能少
8.元组内索引绑定的内存地址不能被修改(注意区分 可变与不可变)
9.元组不能新增或删除数据
集合相关操作
* 类型转换 set()
集合内数据必须是不可变类型(整型 浮点型 字符串 元组)
集合内数据也是无序 没有索引的概念
* 集合需要掌握的方法有:去重和关系运算
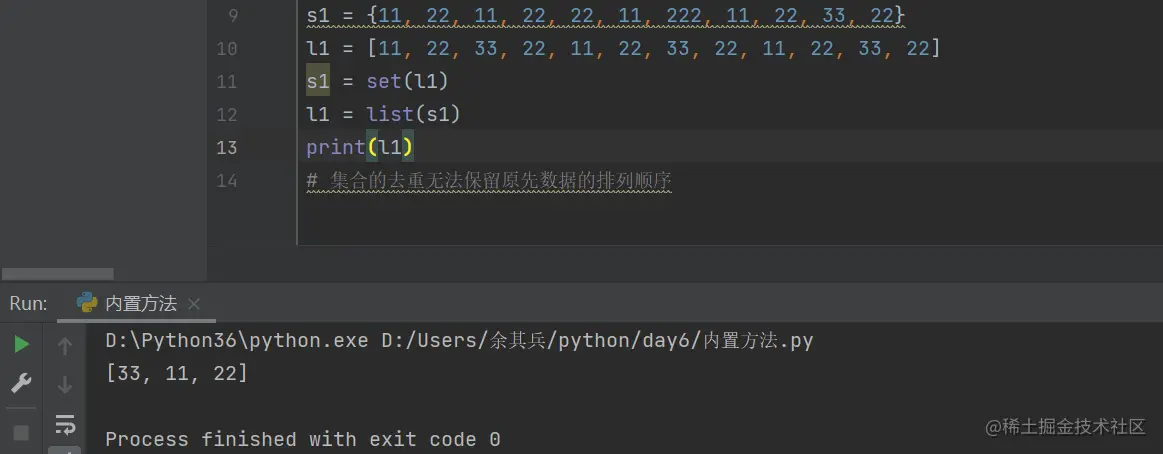
* 去重
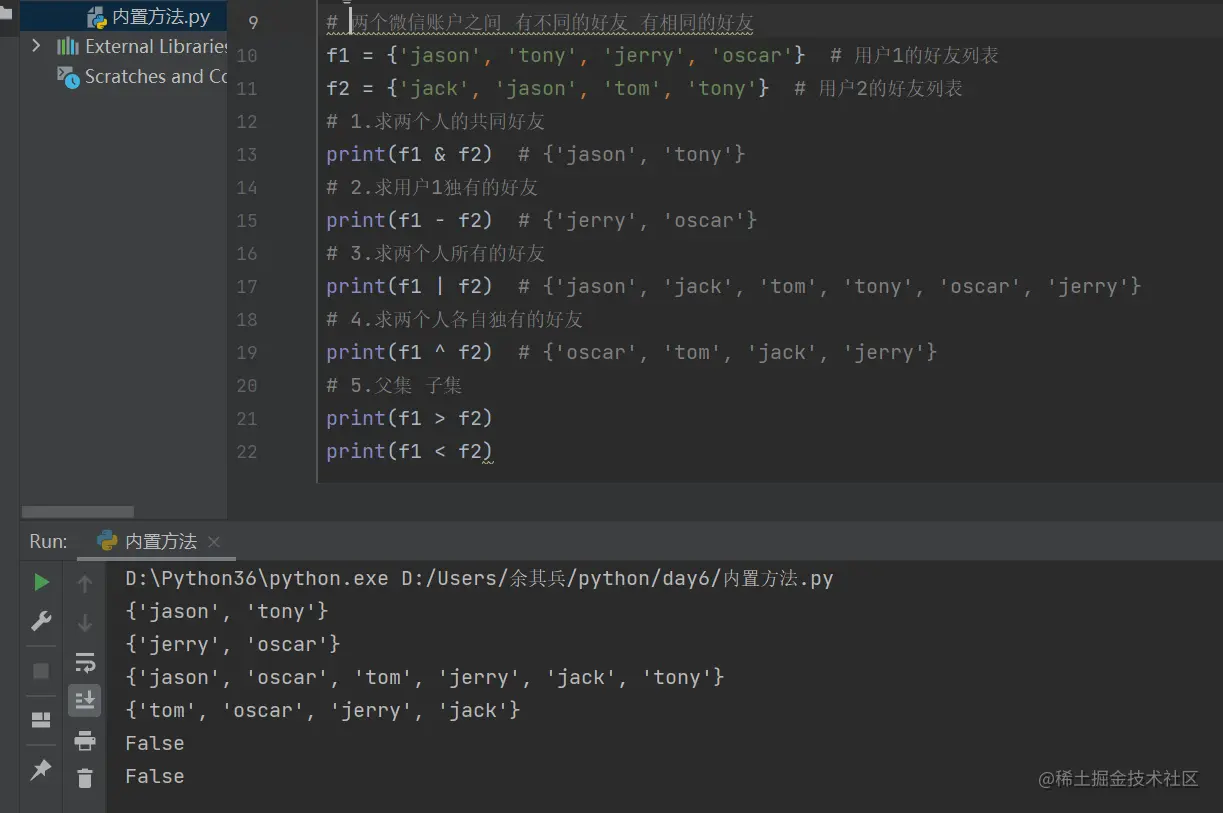
* 关系运算
字符编码理论
该知识点理论特别多 但是结论很少 代码使用也很短
1.字符编码只针对文本数据
2.回忆计算机内部存储数据的本质
3.既然计算机内部只认识01 为什么我们却可以敲出人类各式各样的字符
肯定存在一个数字跟字符的对应关系 存储该关系的地方称为>>>:字符编码本
4.字符编码发展史
4.1.一家独大
计算机是由美国人发明的 为了能够让计算机识别英文
需要发明一个数字跟英文字母的对应关系
ASCII码:记录了英文字母跟数字的对应关系
用8bit(1字节)来表示一个英文字符
4.2.群雄割据
中国人GBK码:记录了英文、中文与数字的对应关系
用至少16bit(2字节)来表示一个中文字符
很多生僻字还需要使用更多的字节
英文还是用8bit(1字节)来表示
日本人shift_JIS码:记录了英文、日文与数字的对应关系
韩国人Euc_kr码:记录了英文、韩文与数字的对应关系
每个国家的计算机使用的都是自己定制的编码本
不同国家的文本数据无法直接交互 会出现"乱码"
4.3.天下一统
unicode万国码兼容所有国家语言字符 起步就是两个字节来表示字符
utf系列:utf8 utf16 ...
专门用于优化unocide存储问题
英文还是采用一个字节 中文三个字节
字符编码实操
* 针对乱码不要紧张 尝试切换编码就可以
* 编码::将人类的字符按照指定的编码编码成计算机能够读懂的数据 字符串.encode()
* 解码:将计算机能够读懂的数据按照指定的编码解码成人能够读懂 bytes类型数据.decode()
* python2与python3差异
python2默认的编码是ASCII
1.文件头 encoding:utf8
2.字符串前面加u u'你好啊'
python3默认的编码是utf系列(unicode)
1.优化员工管理系统
拔高: 是否可以换成字典或者数据的嵌套使用完成更加完善的员工管理而不是简简单单的一个用户名(能写就写不会没有关系)
4.定义存储用户数据的字典
data_dict = {}
while True:
print("""
1.添加员工信息
2.修改员工薪资
3.查看指定员工
4.查看所有员工
5.删除员工数据
""")
func_id = input('请输入功能的编号>>>:').strip()
if func_id == '1':
emp_id = input('请输入员工编号>>>:').strip()
if emp_id in data_dict:
print('该员工编号已经存在')
continue
emp_name = input('请输入员工姓名>>>:').strip()
emp_age = input('请输入员工年龄>>>:').strip()
emp_job = input('请输入员工岗位>>>:').strip()
emp_salary = input('请输入员工薪资>>>:').strip()
temp_dict = {}
temp_dict['emp_id'] = emp_id
temp_dict['emp_name'] = emp_name
temp_dict['emp_age'] = emp_age
temp_dict['emp_job'] = emp_job
temp_dict['emp_salary'] = emp_salary
data_dict[emp_id] = temp_dict
elif func_id == '2':
target_emp_id = input('请输入想要修改的员工编号>>>:').strip()
if target_emp_id not in data_dict:
print('当前员工编号不存在 无法修改!!!')
continue
emp_data = data_dict.get(target_emp_id)
new_salary = input('请输入该员工新的薪资>>>:').strip()
emp_data['emp_salary'] = new_salary
data_dict[target_emp_id] = emp_data
print(f'员工编号:{target_emp_id} 员工姓名:{emp_data.get("emp_name")}薪资修改成功')
elif func_id == '3':
target_emp_id = input('请输入想要查询的员工编号>>>:').strip()
if target_emp_id not in data_dict:
print('当前员工编号不存在')
continue
emp_data = data_dict.get(target_emp_id)
print(f"""
--------------------emp of info------------------
编号:{emp_data.get('emp_id')}
姓名:{emp_data.get('emp_name')}
年龄:{emp_data.get('emp_age')}
岗位:{emp_data.get('emp_job')}
薪资:{emp_data.get('emp_salary')}
-------------------------------------------------
""")
elif func_id == '4':
all_emp_data = data_dict.values()
for emp_data in all_emp_data:
print(f"""
--------------------emp of info------------------
编号:{emp_data.get('emp_id')}
姓名:{emp_data.get('emp_name')}
年龄:{emp_data.get('emp_age')}
岗位:{emp_data.get('emp_job')}
薪资:{emp_data.get('emp_salary')}
-------------------------------------------------
""")
elif func_id == '5':
target_delete_id = input("请输入想要删除的员工编号>>>:").strip()
if target_delete_id not in data_dict:
print('员工编号不存在')
continue
data_dict.pop(target_delete_id)
print(f'员工编号{target_delete_id}数据删除成功')
else:
print('输入不合法!!!')
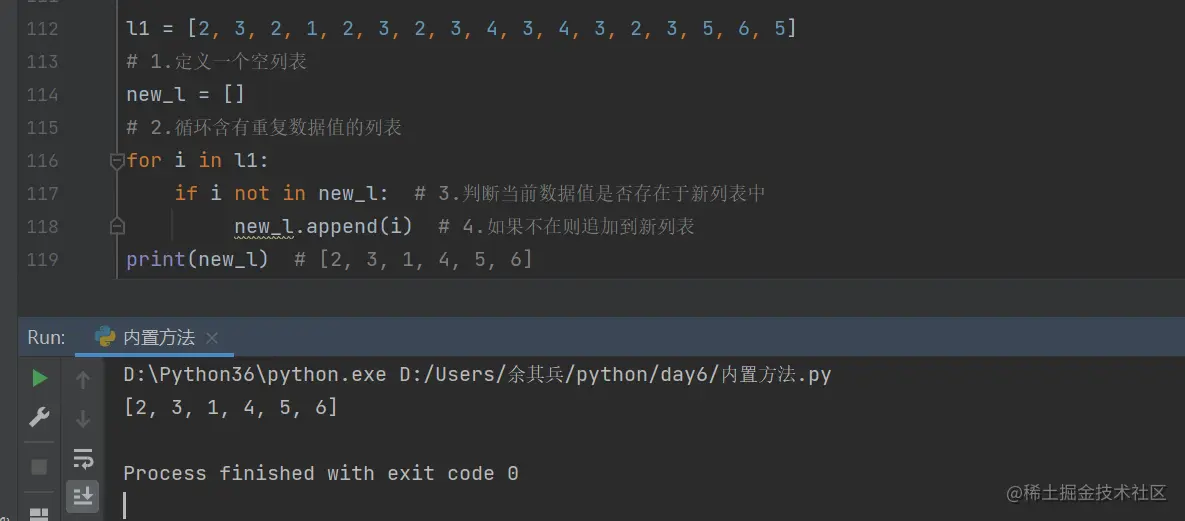
2.去重下列列表并保留数据值原来的顺序
eg: [1,2,3,2,1] 去重之后 [1,2,3]
l1 = [2,3,2,1,2,3,2,3,4,3,4,3,2,3,5,6,5]
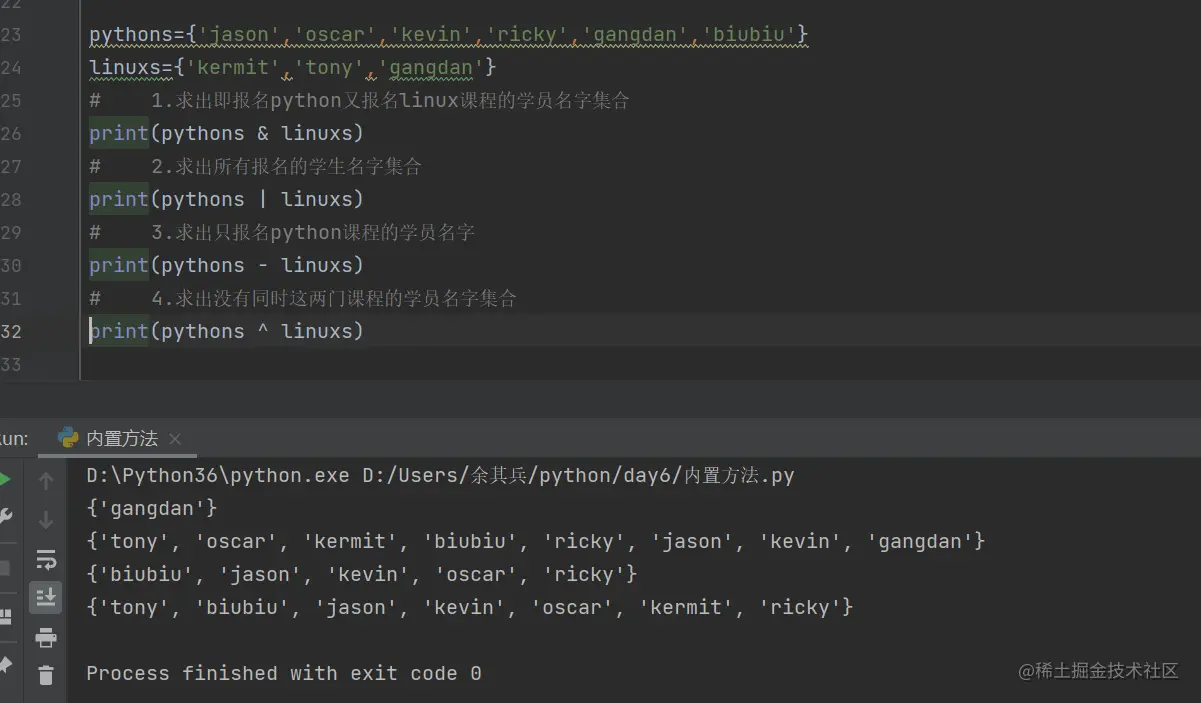
3.有如下两个集合,pythons是报名python课程的学员名字集合,linuxs是报名linux课程的学员名字集合
pythons={'jason','oscar','kevin','ricky','gangdan','biubiu'}
linuxs={'kermit','tony','gangdan'}
1. 求出即报名python又报名linux课程的学员名字集合
2. 求出所有报名的学生名字集合
3. 求出只报名python课程的学员名字
4. 求出没有同时这两门课程的学员名字集合
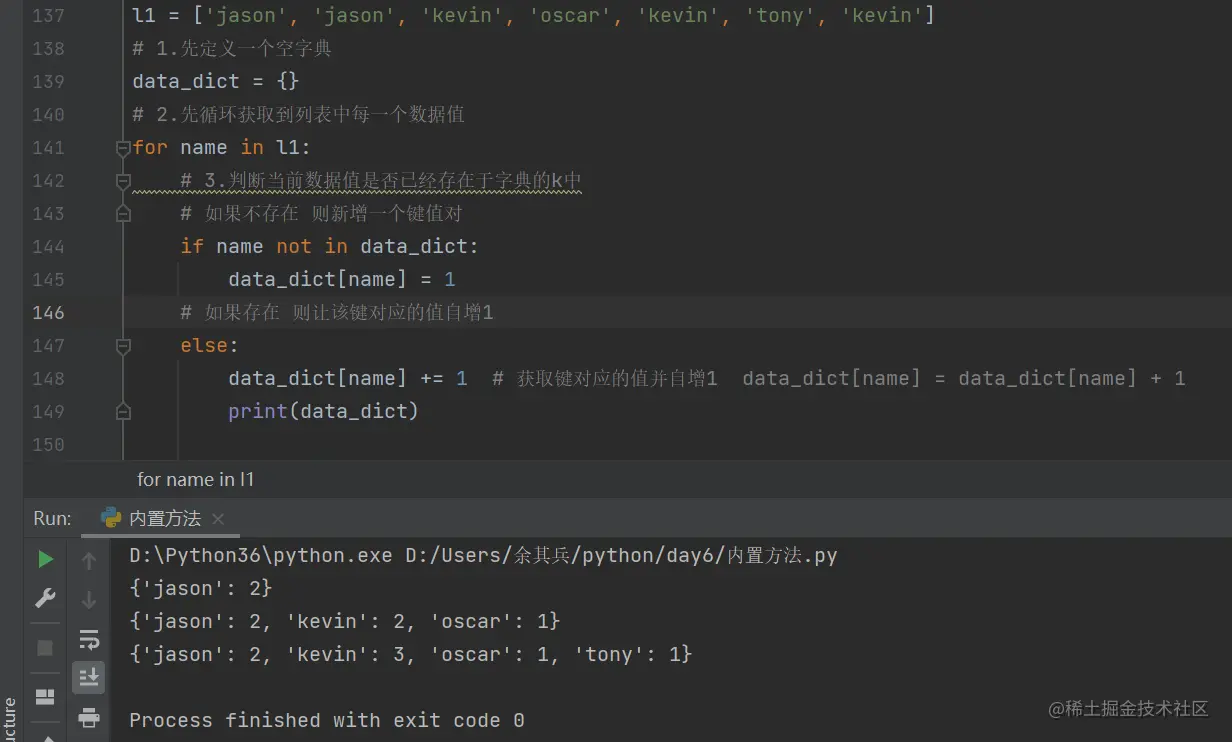
4.统计列表中每个数据值出现的次数并组织成字典战士
eg: l1 = ['jason','jason','kevin','oscar']
结果:{'jason':2,'kevin':1,'oscar':1}
真实数据
l1 = ['jason','jason','kevin','oscar','kevin','tony','kevin']