一元线性回归
判决函数
hθ=θ0+θ1x
代价函数
使用代价(损失)函数评估训练数据与模型参数的匹配程度, 一列代表一个变量
J(θ0,θ1)=2m1i=1∑m(hθ(xi1)−yi1)2
J = (X * theta - y)' * (X * theta - y) / m / 2;
m 是样本数, 代价函数实际上为 误差平方和 , 而训练过程就是要实现
最小化代价函数
解析求导法
求得最优参数只需要一步
损失函数是拟合参数 θ 的二次函数
J(θ)=aθ2+bθ+c
通过求导并令导数等于 0 获取最小值
∂θi∂J(θ)=∂θi∂(2m1i=1∑m(hθ(xi1)−yi1)2)=m1i=1∑m(hθ(xi1)−yi1)⋅xi1=0
解得
θ=(XTX)−1XTy
梯度下降法
计算一个函数的最小值, 可以从一个初始点, 朝着梯度下降的方向计算
θ0=θ0−mαi=1∑m(hθ(xi1)−yi1)
θ1=θ1−mαi=1∑m(hθ(xi1)−yi1)⋅xi1
负梯度 为
−∂θi∂J(θ)=−mαi=1∑m(hθ(xi1)−yi1)⋅xi1
α 为下降速度(步长), θ0 的 x=1 , 因此不存在末尾的 x
num_iters = 1000;
m = length(y);
J_history = zeros(num_iters, 1);
for iter = 1:num_iters
for j = 1:length(theta)
theta(j) = theta(j) - alpha / m * (X * theta - y)' * X(:, j);
end
J_history(iter) = computeCost(X, y, theta);
end
得到了拟合参数 θ 后就可以进行预测了
predict = [1, 3.5] * theta;
多元线性回归
各维相互独立, 可以分别计算
判决函数
hθ(x)=θ0+θ1x1+⋯+θnxn
代价函数
J(θ)=2m1i=1∑m(h(xi.)−yi.)2
当变量间相差多个数量级时, 应该进行 归一化 , 这样才能收敛更快
[m, n] = size(X);
X_norm = zeros(m, n);
mu = mean(X);
sigma = std(X);
for i = 1:n
X_norm(:, i) = (X(:, i) - mu(i)) / sigma(i);
end
Logistic 回归
分类与回归
- 分类 hθ(x)∈{0,1}, 0 代表负例, 1 代表正例
- 回归 hθ(x)∈R
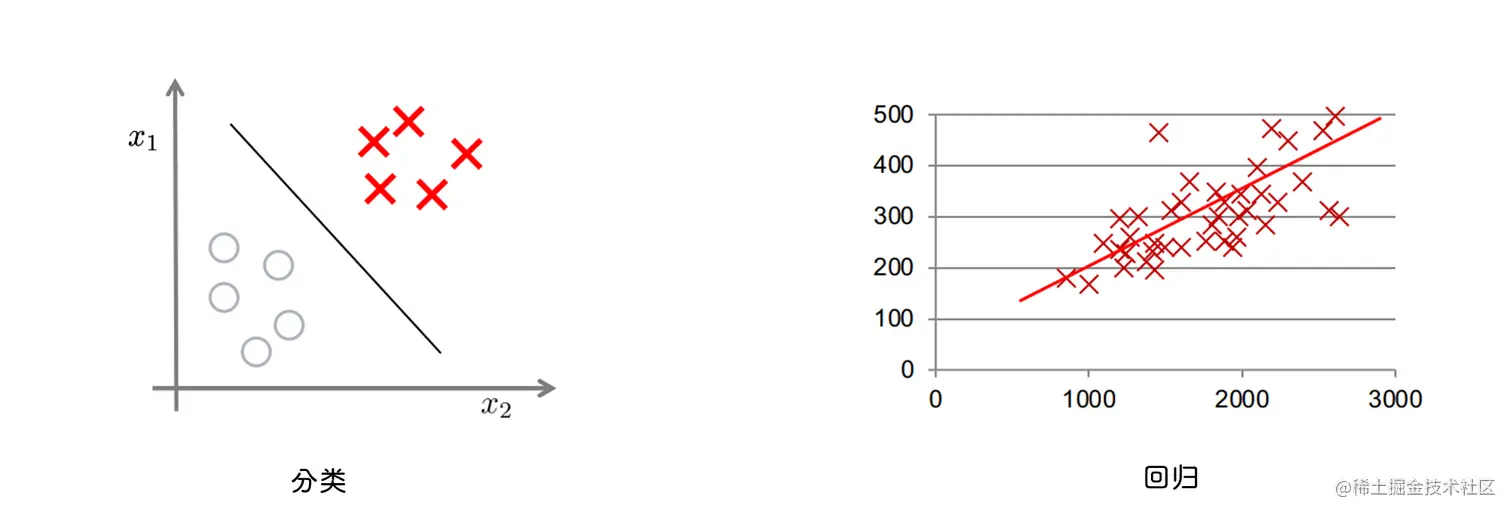
sigmoid 函数
将输出变到 0 或 1 附近
S(x)=1+e−x1
S′(x)=(1+e−x)2e−x=S(x)⋅(1−S(x))
function g = sigmoid(z)
g = 1 ./ (1 + exp(-z));
end
判决函数
hθ(x)=S(θx)=S(θ0+θ1x1+⋯)=(1+e−θx)−1
- 对于正例, 有 hθ(x)≥0.5 , θx≥0
- 对于负例, 有 hθ(x)<0.5 , θx<0
根据已知的正负例计算出 θ
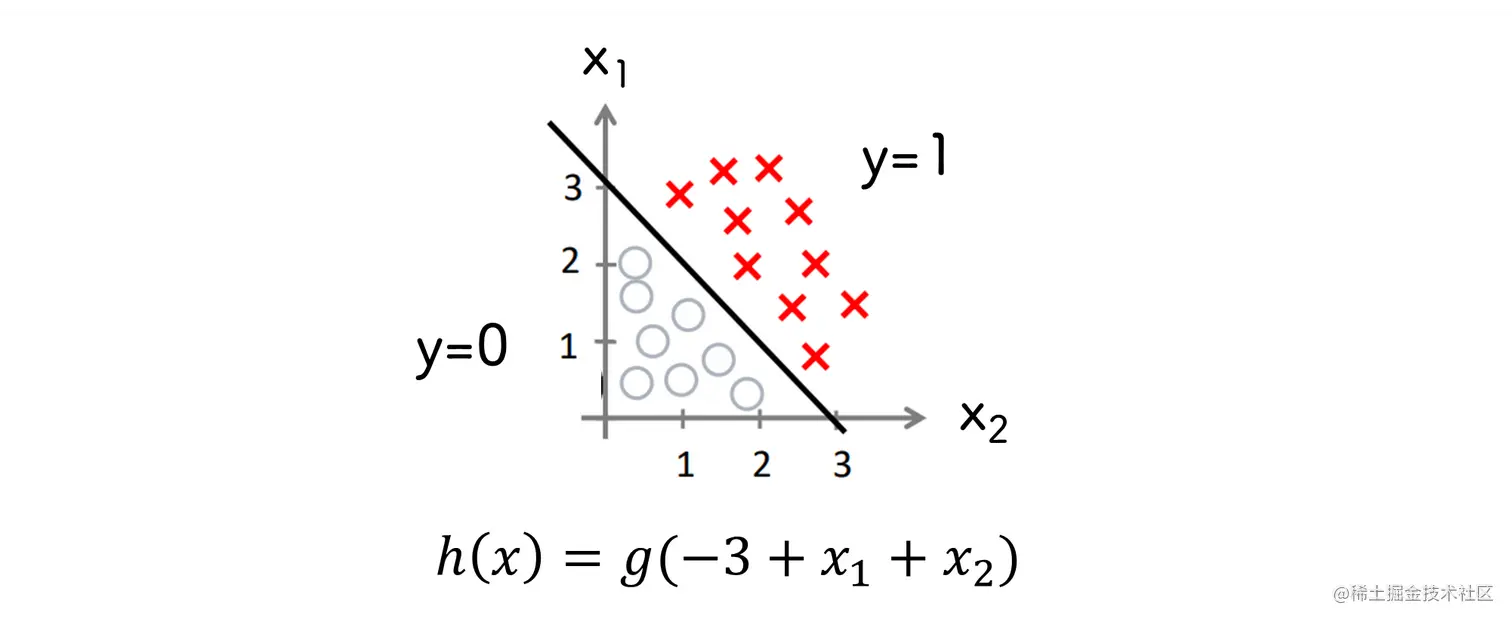
上图中
- 正例 −3+x1+x2≥0
- 负例 −3+x1+x2<0
代价函数
cost(hθ(x),y)={−log(hθ(x))−log(1−hθ(x))y=1y=0
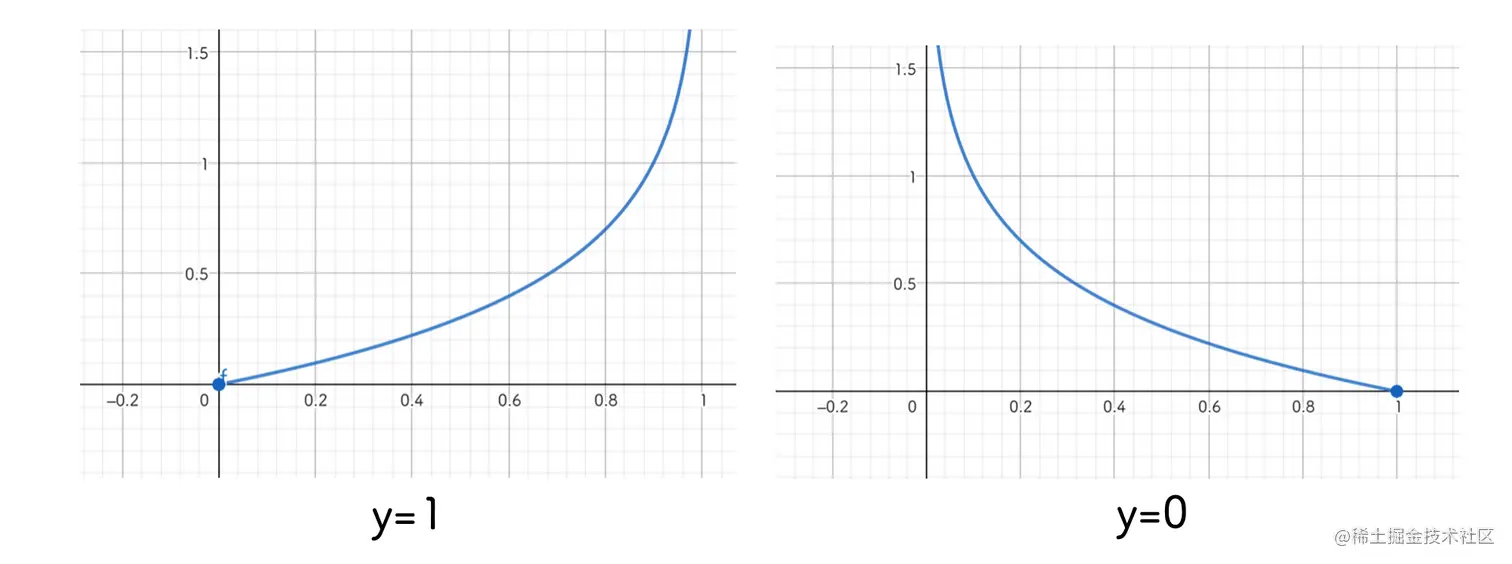
J(θ)=m1i=1∑mcost(hθ(xi),yi)=−m1i=1∑m[yi1log(hθ(xi1))+(1−yi1)log(1−hθ(xi1))]
h = sigmoid(X * theta);
J = - (y' * log(h) + (1 - y)' * log(1 - h)) / m;
精度评估
使用获得的拟合参数计算分类值, 与真实的分类值做比较
p = zeros(m, 1);
t = sigmoid(X * theta);
for i = 1:m
if t(i) >= 0.5
p(i) = 1;
else p(i) = 0;
end
end
p = predict(theta, X);
fprintf('训练精度: %f\n', mean(double(p == y)) * 100);
最小化代价函数
解析求导法
∂θ∂hθ(x)=∂θ∂(1+e−θx1)=hθ(x)⋅(1−hθ(x))⋅x
初始梯度为
∂θi∂J(θ)=m1i=1∑m(h(xi1)−yi1)⋅xi1=0
这个公式和一元线性回归的代价函数导数一模一样, 只是判决函数 h(x) 不一样
grad = X' * (h - y) / m;
梯度下降
θi=θi−αi=1∑m(hθ(xi1)−yi1)⋅xi1
正规化 logistic 回归
特征映射
为了更好的拟合, 使用变量多项式的特征来拟合
mapFeature=⎣⎡1x1x2x12x1x2x22x13⋮x1x25x26⎦⎤
degree = 6;
row = length(X1);
col = (degree + 2) * (degree + 1) / 2;
out = ones(row, col);
c = 2;
for i = 1:degree
for j = 0:i
out(:, c) = (X1.^(i-j)).*(X2.^j);
c = c + 1;
end
end
代价函数
J(θ)=−m1i=1∑m[yi1log(hθ(xi1))+(1−yi1)log(1−hθ(xi1))]+2mλj=1∑mθj.2
∂θj∂(J(θ))={m1∑i=1m(h(xi1)−yi1)⋅xi1m1∑i=1m(h(xi1)−yi1)⋅xi1+mλθjj=0j≥1
h = sigmoid(X * theta);
unreg_cost = - (y' * log(h) + (1 - y)' * log(1 - h)) / m;
theta(1) = 0;
reg_cost = lambda / 2 / m * (theta' * theta);
J = unreg_cost + reg_cost;
grad = (X' * (h - y) + lambda * theta) / m;
线性判别分析
使用一个超平面切分两类样本, 使两类样本 内间距 最小, 类间距 最大
将样本投影到分割面法线上, 使法线上同类样本的投影尽可能近, 非同类样本尽可能远
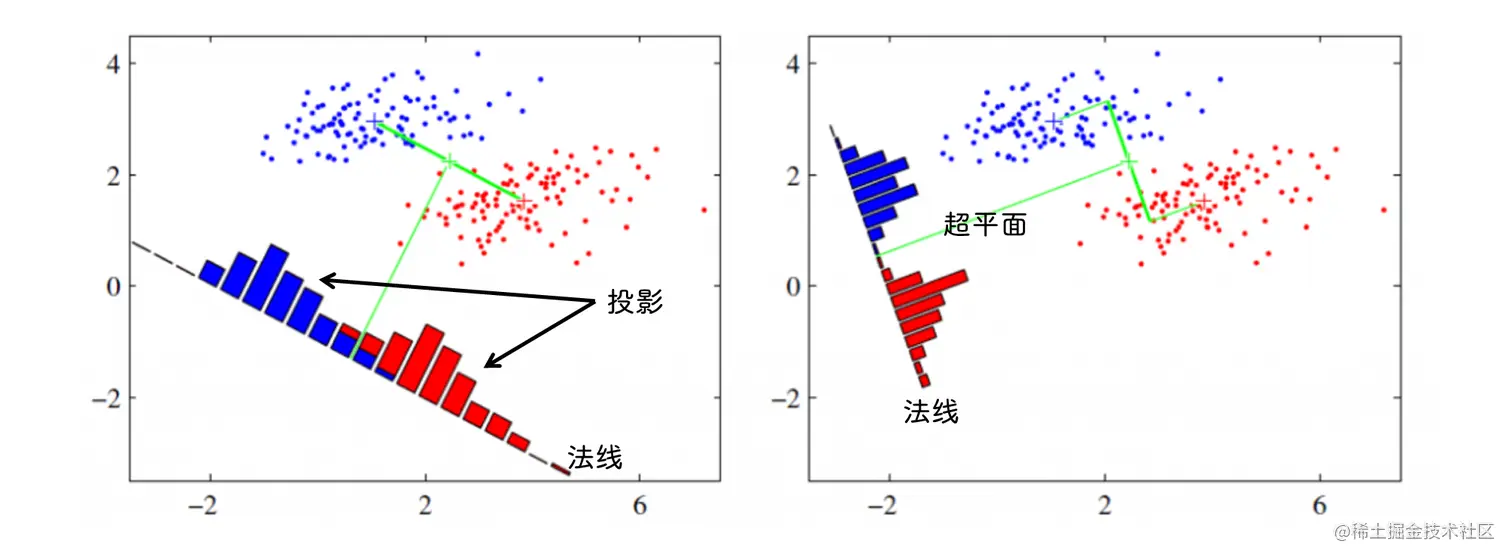
投影
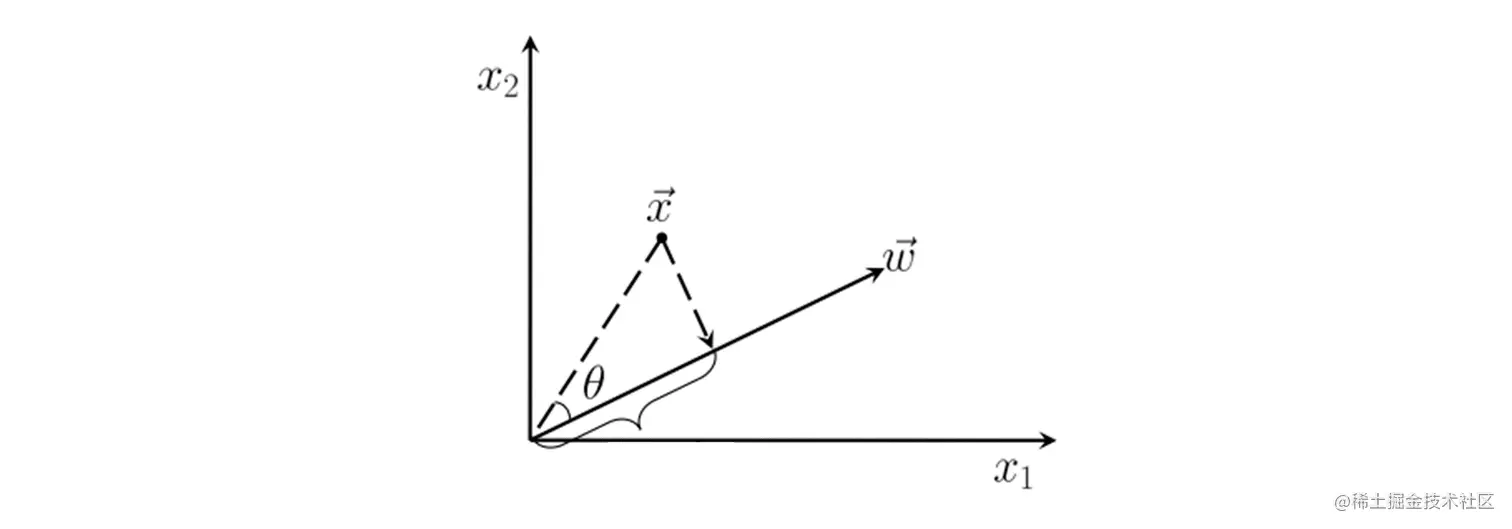
∣x∣⋅cosθ=∣ω∣x⋅ω
样本中心在 ω 上的投影
样本中心在 ω 上投影的协方差
ωTΣω
代价函数
最大化类间距
max((ωTμ0−ωTμ1)2)
最小化类内距
min(ωTΣ0ω+ωTΣ1ω)
代价函数
J=ωTΣ0ω+ωTΣ1ω(ωTμ0−ωTμ1)2=ωTSωωωTSbω
类间散度矩阵
Sb=(μ0−μ1)(μ0−μ1)T
类内散度矩阵
Sω=Σ0+Σ1=∑(x−μ0)(x−μ0)T+∑(x−μ1)(x−μ1)T
最大化代价函数
如果 ω 是一个解, 则 cω 也是一个解, 因此可以令 ωTSωω=1
最大化代价函数等价于求解
min(−ωTSbω)
利用拉格朗日函数求解最小值
L(ω,λ)=−ωTSbω+λ(ωTSωω−1)
令导数等于零
ω∂L(ω,λ)=−Sbω+λSωω=0
展开后得到
Sbω=(μ0−μ1)(μ0−μ1)Tω=R(μ0−μ1)=λSωω
解得判决模型参数
ω=λRSω−1(μ0−μ1)
判决模型阈值
y0=21ωT(μ0+μ1)
计算样本的投影
根据投影获得分类
{y≥y0y<y010 

