

如何有效管理大型数据库
Paul Namuag 【hudson 译】
2021年5月19日

在处理和管理数据库时,最大的问题之一是其数据和大小的复杂性。通常由于数据库管理失败,企业会担心如何处理增长和管理增长影响。复杂性带来的问题最初没有得到解决,也没有被发现,或者可能被忽略,因为当前使用的技术应该能够自行处理。必须相应地计划管理复杂的大型数据库,尤其是当您正在管理或处理的数据类型预计会以预期或不可预测的方式大量增长时。计划的主要目标是避免不必要的灾难,或者我们应该说不要吸烟!在这个博客中,我们将介绍如何有效地管理大型数据库。
数据大小很重要
数据库的大小很重要,因为它会影响性能及其管理方法。如何处理和存储数据将有助于如何管理数据库,这适用于传输中的数据和静态数据。对于许多大型组织来说,数据是黄金,数据的增长可能会在这一过程中发生巨大变化。因此,事先制定计划来处理数据库中不断增长的数据至关重要。
在我处理数据库的经验中,我目睹了客户在处理性能损失和管理极端数据增长方面遇到的问题。出现的问题是,是规范化表还是非规范化表。
规范化表
规范化表可以维护数据完整性,减少冗余,并可以轻松地将数据组织为更有效的方式来管理、分析和提取。使用规范化的表可以提高效率,尤其是在通过SQL语句分析数据流和检索数据时,或者在使用编程语言(如C/C++、Java、Go、Ruby、PHP或带有MySQL Connectors的Python接口)时。
尽管对规范化表的关注会带来性能损失,并且在检索数据时会由于一系列连接而减慢查询速度。与非规范化的表相比,您需要考虑的所有优化都依赖于索引或主键将数据存储到缓冲区中,以便比执行多个磁盘查找更快地检索。非规范化的表不需要连接,但它牺牲了数据完整性,数据库的大小往往越来越大。
当数据库较大时,请考虑在MySQL/MariaDB中为数据库表使用DDL(数据定义语言)。为表添加主键或唯一键需要重新生成表。更改列数据类型还需要重建表,因为适用的算法仅为 algorithm=COPY。
如果您在生产环境中这样做,可能会有挑战性。如果你的表巨大,挑战加倍。想象一下一百万或十亿行。不能将ALTER TABLE语句直接应用于表。对当前表应用DDL语句会阻止所有需要访问该表的进入流量。然而,这可以通过使用pt在线模式更改 或者非常棒的工具 gh-ost . 来缓解。尽管如此,在执行DDL过程时,它需要监控和维护。
分片和分区 (Sharding and Partitioning)
分片和分区有助于根据数据的逻辑标识来隔离或分割数据。例如,通过基于给定范围的日期、字母顺序、国家/地区、州或基于主键的范围进行隔离。这有助于管理数据库大小。将数据库大小保持在您的组织和团队可以管理的范围内。必要时易于扩展或易于管理,尤其是在发生灾难时。
当我们说可管理时,还要考虑服务器和工程团队的容量资源。你不能用很少的工程师来处理大数据。使用大数据(如1000个数据库和大量数据集)需要大量的时间。必须具备技能和专业知识。如果成本是一个问题,那么您可以利用第三方服务。
##字符集和排序规则
字符集和排序规则会影响数据存储和性能,尤其是在给定字符集和选定的排序规则上。每个字符集和排序规则都有其用途,通常需要不同的长度。如果您的表由于字符编码而需要其他字符集和排序规则,则需要为数据库和表甚至列存储和处理数据。 这会影响如何有效地管理数据库。如前所述,它会影响您的数据存储和性能。如果您了解应用程序要处理的字符类型,请记下要使用的字符集和排序规则。LATIN类型的字符集应主要满足要存储和处理的字母数字类型的字符。
如果不可避免,分片和分区至少有助于减少和限制数据,以避免数据库服务器中的数据膨胀过多。在单个数据库服务器上管理非常大的数据可能会影响效率,特别是用于备份、灾难和恢复,或者在数据损坏或数据丢失的情况下进行的数据恢复。
数据库复杂性影响性能
当涉及到性能损失时,大型复杂数据库往往有一个因素。 复杂,在这种情况下意味着数据库的内容由数学方程、坐标或数字和财务记录组成。现在,将这些记录与使用数据库内建的数学函数的查询混合在一起。看看下面的示例SQL(MySQL/MariaDB兼容)查询,
SELECT
ATAN2( PI(),
SQRT(
pow(`a`.`col1`-`a`.`col2`,`a`.`powcol`) +
pow(`b`.`col1`-`b`.`col2`,`b`.`powcol`) +
pow(`c`.`col1`-`c`.`col2`,`c`.`powcol`)
)
) a,
ATAN2( PI(),
SQRT(
pow(`b`.`col1`-`b`.`col2`,`b`.`powcol`) -
pow(`c`.`col1`-`c`.`col2`,`c`.`powcol`) -
pow(`a`.`col1`-`a`.`col2`,`a`.`powcol`)
)
) b,
ATAN2( PI(),
SQRT(
pow(`c`.`col1`-`c`.`col2`,`c`.`powcol`) *
pow(`b`.`col1`-`b`.`col2`,`b`.`powcol`) /
pow(`a`.`col1`-`a`.`col2`,`a`.`powcol`)
)
) c
FROM
a
LEFT JOIN `a`.`pk`=`b`.`pk`
LEFT JOIN `a`.`pk`=`c`.`pk`
WHERE
((`a`.`col1` * `c`.`col1` + `a`.`col1` * `b`.`col1`)/ (`a`.`col2`))
between 0 and 100
AND
SQRT(((
(0 + (
(((`a`.`col3` * `a`.`col4` + `b`.`col3` * `b`.`col4` + `c`.`col3` + `c`.`col4`)-(PI()))/(`a`.`col2`)) *
`b`.`col2`)) -
`c`.`col2) *
((0 + (
((( `a`.`col5`* `b`.`col3`+ `b`.`col4` * `b`.`col5` + `c`.`col2` `c`.`col3`)-(0))/( `c`.`col5`)) *
`b`.`col3`)) -
`a`.`col5`)) +
((
(0 + (((( `a`.`col5`* `b`.`col3` + `b`.`col5` * PI() + `c`.`col2` / `c`.`col3`)-(0))/( `c`.`col5`)) * `b`.`col5`)) -
`b`.`col5` ) *
((0 + (((( `a`.`col5`* `b`.`col3` + `b`.`col5` * `c`.`col2` + `b`.`col2` / `c`.`col3`)-(0))/( `c`.`col5`)) * -20.90625)) - `b`.`col5`)) +
(((0 + (((( `a`.`col5`* `b`.`col3` + `b`.`col5` * `b`.`col2` +`a`.`col2` / `c`.`col3`)-(0))/( `c`.`col5`)) * `c`.`col3`)) - `b`.`col5`) *
((0 + (((( `a`.`col5`* `b`.`col3` + `b`.`col5` * `b`.`col2`5 + `c`.`col3` / `c`.`col2`)-(0))/( `c`.`col5`)) * `c`.`col3`)) - `b`.`col5`
))) <=600
ORDER BY
ATAN2( PI(),
SQRT(
pow(`a`.`col1`-`a`.`col2`,`a`.`powcol`) +
pow(`b`.`col1`-`b`.`col2`,`b`.`powcol`) +
pow(`c`.`col1`-`c`.`col2`,`c`.`powcol`)
)
) DESC
考虑一下,这个查询应用于一百万行的表。这极有可能使服务器停止运行,并且可能会占用大量资源,从而危及生产数据库集群的稳定性。所涉及的列往往会被索引,以优化并提高查询性能。然而,为优化性能而向引用列添加索引并不能保证管理大型数据库的效率。 在处理复杂性时,更有效的方法是避免严格使用复杂的数学方程,并避免过度使用这种内置的复杂计算能力。这可以通过使用后端编程语言而不是使用数据库的复杂计算进行操作和传输。如果您有复杂的计算,那么为什么不将这些公式存储在数据库中,检索查询,并在需要时将其组织为更易于分析或调试的内容。
您是否使用了正确的数据库引擎?
根据给定的查询和从表中读取或检索的记录的组合,数据结构会影响数据库服务器的性能 。MySQL/MariaDB中的数据库引擎支持使用B-Trees的InnoDB和MyISAM,而NDB或内存数据库引擎使用Hash Mapping。这些数据结构有其渐近符号,后者表示这些数据结构使用的算法的性能。在计算机科学中,我们称之为“O”符号,它描述了算法的性能或复杂性。考虑到InnoDB和MyISAM使用B-Trees,它使用O(log n)进行搜索。然而,哈希表或哈希映射使用O(0)。 两者都有其表现的平均值和最差情况。
现在回到具体的引擎,考虑到引擎的数据结构,基于要检索的目标数据应用的查询当然会影响数据库服务器的性能。哈希表不能进行范围检索,而B-Trees在执行这些类型的搜索时非常有效,并且可以处理大量数据。 对存储的数据使用正确的引擎,您需要确定对这些存储的特定数据应用的查询类型。当数据转换为业务逻辑时,这些数据应形成什么类型的逻辑。 处理1000个或数千个数据库,结合您想要检索和存储的查询和数据使用正确的引擎,将提供良好的性能。假设您已经预先确定并分析了针对正确数据库环境的需求。
管理大型数据库的合适工具
如果没有一个可靠的平台,就很难管理一个非常大的数据库。即使有优秀且熟练的数据库工程师,从技术上讲,您使用的数据库服务器也很容易出现人为错误。对配置参数和变量的任何更改都可能导致(数据库服务)剧烈变化,从而降低服务器的性能。
在非常大的数据库上执行数据库备份有时可能很困难。有时备份可能会因某些奇怪的原因而失败。通常,可能使运行备份的服务器停止运行的查询会导致失败。否则,您必须调查其原因。
使用自动化工具,如Chef、Puppet、Ansible、Terraform或SaltStack,可以用作您的IaC,以提供更快的任务执行。同时使用其他第三方工具来帮助您监控和提供高质量的图形图像。告警通知系统也非常重要,可以获得从警告到严重状态不同级别的问题。 ClusterControl 在这种情况下可以大显身手。
ClusterControl可以轻松管理大量数据库,甚至可以管理分片类型的环境。它已经测试和安装了数千次,并已投入生产,为操作数据库环境的DBA、工程师或DevOps人员提供 警报和通知 。范围从临时环境或开发环境、QA到生产环境。 ClusterControl还可以执行备份和恢复 。 即使使用大型数据库,它非常高效且易于管理,因为UI提供了调度,并且还可以选择上载到云(AWS、Google cloud和Azure)。
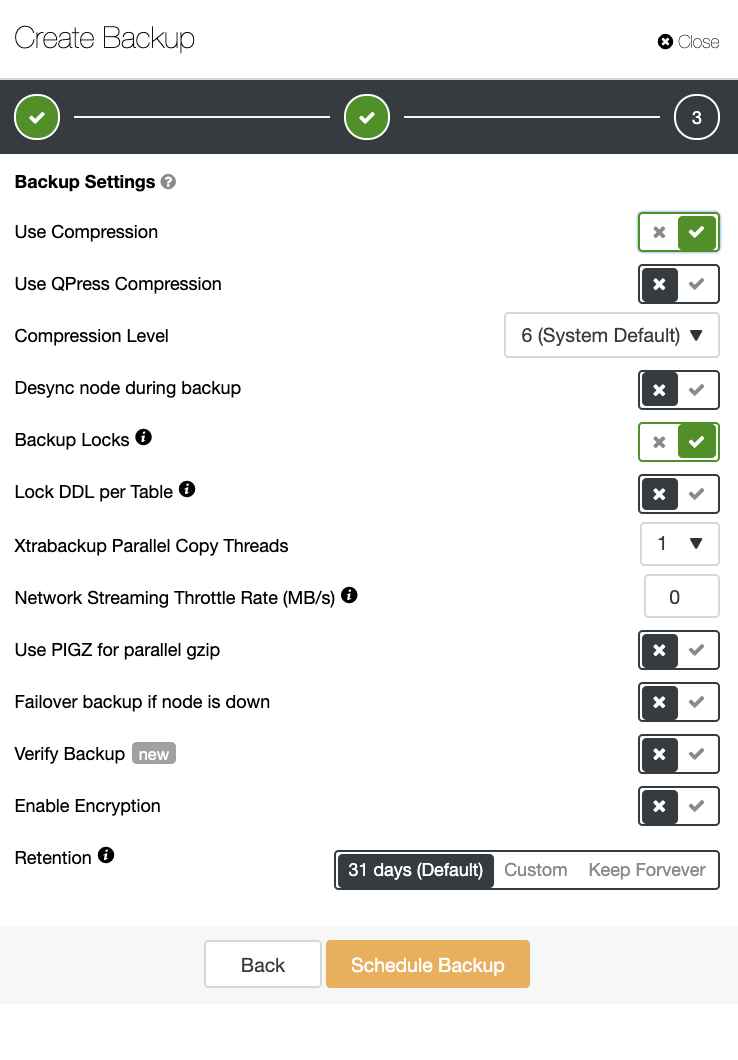
另外还有备份验证和许多其他选项,如 加密 和压缩。例如,请参见下面的屏幕截图(使用Xtrabackup 创建MySQL备份):
结论
管理大型数据库(如1000个或更多)可以有效地完成,但必须事先确定和准备。使用正确的工具,例如自动化,甚至订阅托管服务,都会大有帮助。尽管这会产生成本,但只要有合适的工具可用,就可以减少服务周期和大量预算。
