聚合
一、概念
- ES除提供搜索功能外,还提供了针对ES数据进行统计分析的功能,这个功能就是聚合;
- 通过聚合,我们会得到一个数据的概览,对全套数据进行分析和总结;
- 高性能,实时性高,只需要一条语句,就可以从ES获取分析结果,无需客户端实现分析逻辑;
二、Bucket Aggregation — 一些列满足特定条件的文档的集合
- 类似于sql中的group by 分组功能;
- 常见Bucket类型
- terms,根据字段进行常规分组,适用于keyword数据类型;
- Data Range,指定数据范围内分组,适用于数字类型数据;
- Data Histogram,固定间隔范围内分组,适用于数字类型数据;
- 允许通过添加子聚合,支持Bucket和Metric子聚合;
- Terms聚合
- 适用于keyword数据类型,如果需要text类型字段分组,则需要通过设置mapping打开分组字段的fielddata,才能terms分组;
- Terms聚合性能优化:对分组字段设置mapping字段属性"eager_global_ordinals"为true,新数据写入Term就会被加载到Cache中;
- Demo
#bucket例子
GET kibana_sample_data_flights/_search
{
"size": 0,
"aggs": {
"flight_dest": {
"terms": {
"field": "DestCountry",
"size": 5
}
}
}
}
- Demo
GET employees/_search
{
"size": 0,
"aggs": {
"salary_range": {
//设置聚合类型为range
"range": {
"field": "salary",
"ranges": [
{
//to设置的是最大值
"to": 10000
},
{
//from设置的是最小值
"from": 10000,
"to": 20000
},
{
//可以自定义返回的key值,不设置的话,es会提供默认的返回key
"key": ">20000",
"from": 20000
}
]
}
}
}
}
- Demo
GET employees/_search
{
"size": 0,
"aggs": {
"salary_histogram": {
"histogram": {
"field": "salary",
"interval": 5000,
"extended_bounds": {
"min": 0,
"max": 100000
}
}
}
}
}
三、Metric Aggregation — 一些数学运算,可以对文档字段进行统计分析
- 类似于sql中的 count,max,min等数据函数等实现的数字统计功能;
- 基于数据集计算结果,除了支持在字段上进行计算,同样也支持在脚本产生的结果之上进行计算;
- 大多数Metric是数学计算仅输出一个值,min/max/sum/avg/cardinality(类似distinct Count);
- 部分Metric支持输出多个值,stats/percentiles/percentile_ranks/top hits(排在前面的示例);
- 单值输出Demo
#bucket并加入metrics例子
GET kibana_sample_data_flights/_search
{
"size": 0,
"aggs": {
"flight_dest": {
"terms": {
"field": "DestCountry"
},
"aggs": {
"avg_price": {
"avg": {
"field": "AvgTicketPrice"
}
},
"max_price": {
"max": {
"field": "AvgTicketPrice"
}
},
"min_price": {
"min": {
"field": "AvgTicketPrice"
}
}
}
"DestCountryCount": {
"cardinality": {
"field": "DestCountry"
}
}
}
}
}
#嵌套聚合
GET kibana_sample_data_flights/_search
{
"size": 0,
"aggs": {
"flight_dest": {
"terms": {
"field": "DestCountry"
},
"aggs": {
"avg_price": {
"avg": {
"field": "AvgTicketPrice"
}
},
"weather":{
"terms": {
"field": "DestWeather"
}
}
}
}
}
}
- 多值输出(top_hits)Demo
POST employees/_search
{
"size": 0,
"aggs": {
"jobs": {
"terms": {
"field":"job.keyword"
},
"aggs":{
"old_employee":{
"top_hits":{
"size":3,
"sort":[
{
"age":{
"order":"desc"
}
}
]
}
}
}
}
}
}
四、Pipeline Aggregation — 对其他的聚合结果进行二次聚合分析
- Pipeline 分析结果会输出到原结果中,根据位置不同,分为以下两类:
- Sibling-结果和现有分析结果同级,max/min/avg/sun/stats/percentiles;
GET employees/_search
{
"size": 0,
"aggs": {
"jobs": {
"terms": {
"field": "job.keyword",
"size": 10
},
"aggs": {
"avg_salary": {
"avg": {
"field": "salary"
}
}
}
},
"stats_salary_by_job": {
"stats_bucket": {
"buckets_path": "jobs>avg_salary"
}
}
}
}
- Parent-结果内嵌到现有聚合分析结果之中,derivative(求导)/cumultive sum(累计求和)/moving function(滑动窗口);
GET employees/_search
{
"size": 0,
"aggs": {
"age": {
"histogram": {
"field": "age",
"interval": 1,
"min_doc_count": 0
},
"aggs": {
"avg_salary": {
"avg": {
"field": "salary"
}
},
"cumulative_salary": {
"cumulative_sum": {
"buckets_path": "avg_salary"
}
}
}
}
}
}
五、Matrix Aggregation — 支持对多个字段的操作并提供一个结果矩阵
六、聚合的作用范围与排序
- ES聚合分析默认作用范围是query的查询结果集;
- ES还支持以下方式改变聚合的作用范围:
- Filter(在聚合内部对数据进行筛选后再分桶,该筛选不会对其他同级聚合起作用);
POST employees/_search
{
"size": 0,
"aggs": {
"older_person": {
"filter":{
"range":{
"age":{
"from":35
}
}
},
"aggs":{
"jobs":{
"terms": {
"field":"job.keyword"
}
}
}},
"all_jobs": {
"terms": {
"field":"job.keyword"
}
}
}
}
- Post Filter(通过对分桶后的数据进行筛选查询,获取分桶中满足条件的文档详情);
POST employees/_search
{
"aggs": {
"jobs": {
"terms": {
"field": "job.keyword"
}
}
},
"post_filter": {
"match": {
"job.keyword": "Dev Manager"
}
}
}
- Global(对指定的global聚合执行筛选豁免,即聚合不参与外部的条件的筛选);
POST employees/_search
{
"size": 0,
"query": {
"range": {
"age": {
"gte": 40
}
}
},
"aggs": {
"jobs": {
"terms": {
"field":"job.keyword"
}
},
"all":{
"global":{},
"aggs":{
"salary_avg":{
"avg":{
"field":"salary"
}
}
}
}
}
}
七、聚合的排序
- ES默认是对聚合的count值做降序排序;
- ES也支持自定义对聚合后的数据进行排序;
//1.普通指定桶排序
POST employees/_search
{
"size": 0,
"query": {
"range": {
"age": {
"gte": 20
}
}
},
"aggs": {
"jobs": {
"terms": {
"field":"job.keyword",
//通过在聚合中加入order字段,来指定排序方式
"order":[
{"_count":"asc"},
{"_key":"desc"}
]
}
}
}
}
//2.通过子聚合的数据进行桶排序
POST employees/_search
{
"size": 0,
"aggs": {
"jobs": {
"terms": {
"field":"job.keyword",
//指定子聚合的名称,通过子聚合的数据进行排序
"order":[ {
"avg_salary":"desc"
}]
},
"aggs": {
"avg_salary": {
"avg": {
"field":"salary"
}
}
}
}
}
}
//3.通过多值子聚合数据进行桶排序
POST employees/_search
{
"size": 0,
"aggs": {
"jobs": {
"terms": {
"field":"job.keyword",
"order":[ {
//对于多值聚合,指定排序=多值子聚合名称+".某个值"
"stats_salary.min":"desc"
}]
},
//子聚合
"aggs": {
"stats_salary": {
//stats是多值聚合
"stats": {
"field":"salary"
}
}
}
}
}
}
八、聚合原理及精准度问题
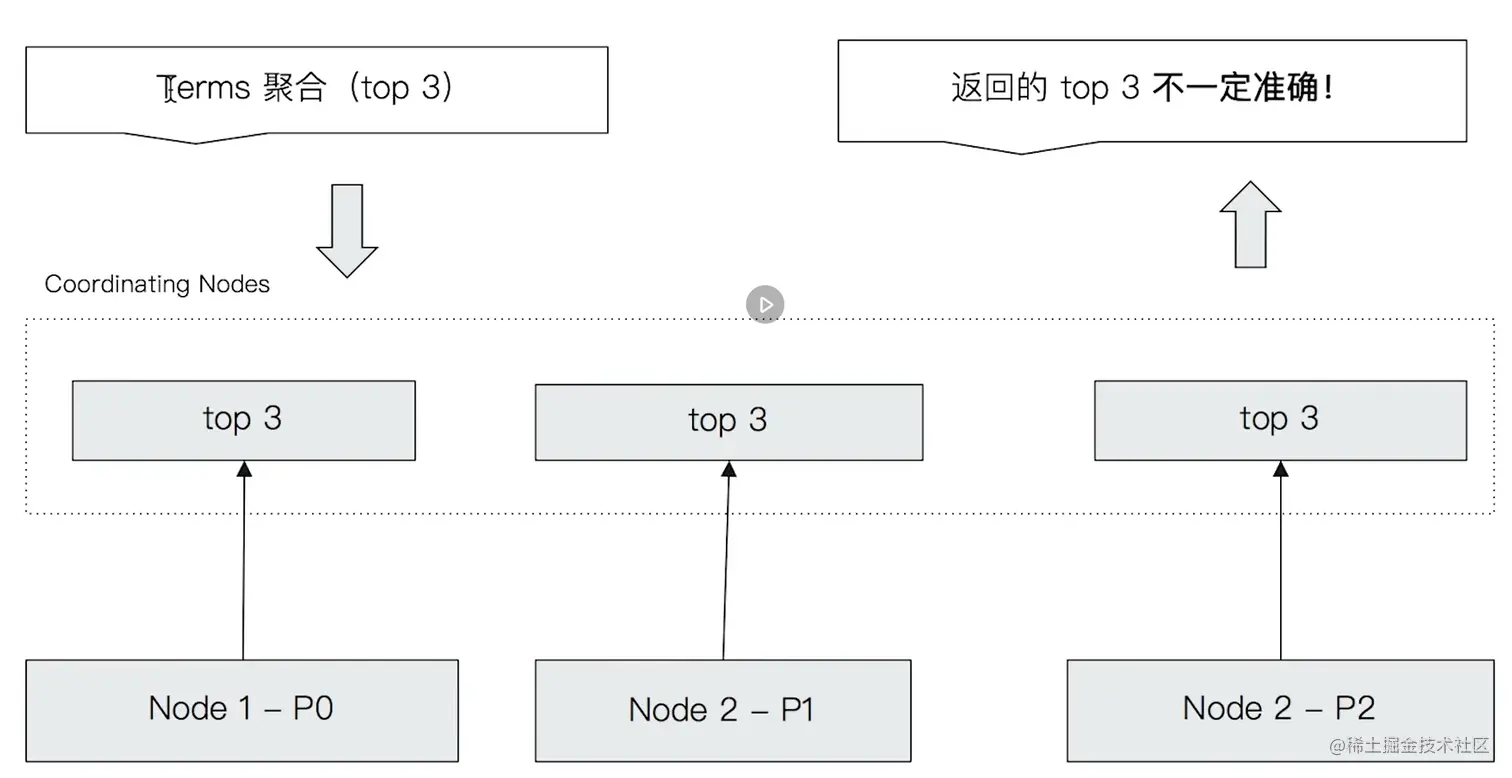
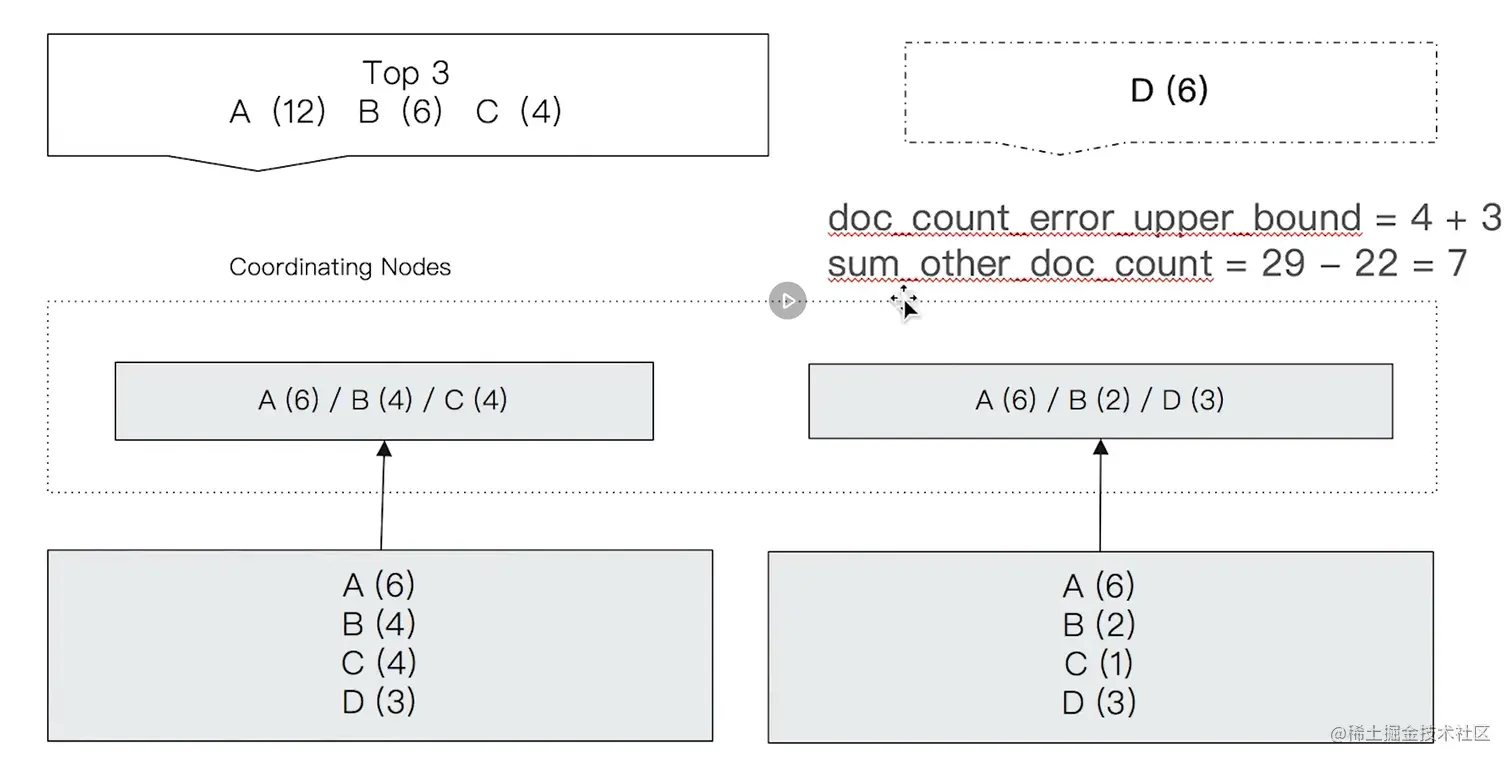
- Terms聚合分析会出现不准确的原因,数据分散多个分片上,Coordinating Node无法获取数据全貌;
- 解决方案:
- 数据量小时,可以设置主分片数为1,这样就能保证数据的准确性;
- 分布式数据上,设置shard_size参数,该参数每次从分片上额外多获取数据,提升准确率,会降低响应时间;ES默认设定该值=size*1.5+10;
GET my_flights/_search
{
"size": 0,
"aggs": {
"weather": {
"terms": {
"field":"OriginWeather",
"size":1,
"shard_size":1,
"show_term_doc_count_error":true
}
}
}
}
{
"took" : 8,
"timed_out" : false,
"_shards" : {
"total" : 20,
"successful" : 20,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 10000,
"relation" : "gte"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"weather" : {
"doc_count_error_upper_bound" : 2495,
"sum_other_doc_count" : 12189,
"buckets" : [
{
"key" : "Cloudy",
"doc_count" : 870,
"doc_count_error_upper_bound" : 1625
}
]
}
}
}


