训练神经网络时,尤其是深度神经网络所面临的一个重要问题就是梯度爆炸或梯度消失,也就是我们训练神经网络的时候,导数或梯度有时会变得非常大,或者非常小,甚至于以指数方式变小,这加大了训练的难度。接下来我们介绍一些什么是梯度爆炸和梯度消失。
为了方便演示,这里我们假设每一层神经网络只有两个神经元,每一层神经网络的参数为W[L],假设激活函数就是线性的g(z)=z,并且令b=0,每一层的输出结果为aL,做好上述假设后,我们可以得到下述关系:
a1=W1X,a2=W2a1,...,aL=WLaL−1,进一步可以导入计算y
y=WLWL−1...W1X
此时相当于有很多层权重矩阵乘积在一起,假设所有的矩阵都是1.5倍的单位矩阵,那么当层数很多时1.5L将会很大,意味着y会以指数爆炸增长,同样意味着梯度也会很大。相反,假设矩阵是0.5倍的单位矩阵,那么y会以指数趋于0.同样意味着梯度也会消失。假设有50层:
1.550=637621500,0.550=8.88×10−16
可以看出,在深度神经网络中,如果不进行相应的处理设置,很容易出现梯度爆炸或梯度消失
1.梯度消失
我们在之前介绍了sigmoid激活函数,但是它现在不常用了,因为他就是导致梯度消失的一个常见的情况。现在我们来看看sigmoid的梯度情况
%matplotlib inline
import torch
import matplotlib.pyplot as plt
from torch import nn
x = torch.arange(-8.0, 8.0, 0.1, requires_grad=True)
y = torch.sigmoid(x)
y.backward(torch.ones_like(x))
plt.plot(x.detach().numpy(), y.detach().numpy(),'--',label='sigmoid')
plt.plot(x.detach().numpy(), x.grad.numpy(),'r--',label='gradient')
plt.legend(loc = 'best')
plt.grid(True)
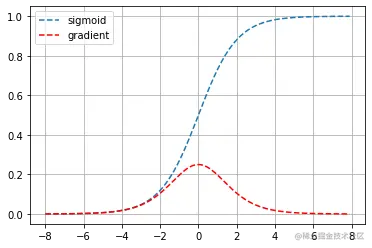
可以看出,当sigmoid函数的输入很大或是很小时,它的梯度都会消失。 此外,当反向传播通过许多层时, 这些地方sigmoid函数的输入接近于零,可能导致整个乘积的梯度可能会消失。因此,ReLU激活函数成为了大家默认的选择
2.梯度爆炸
同样的,梯度爆炸也是一个非常严重的问题,它会让导致梯度下降很难收敛。下面我们举一个简单的例子,来看看梯度爆炸的情况,我们定义一个4×4的随机矩阵,满足标准正态分布,观察乘以50次之后的结果
M = torch.normal(0, 1, size=(4,4))
print('一个矩阵 \n',M)
for i in range(50):
M = torch.mm(M,torch.normal(0, 1, size=(4, 4)))
print('乘以50个矩阵后\n', M)
一个矩阵
tensor([[ 1.2106, -1.2478, 0.9032, 0.1750],
[-0.4060, 0.7475, -2.2134, -2.1323],
[-1.0121, 0.1883, 1.7743, -0.6649],
[ 0.1302, 0.2794, 0.0039, -0.2880]])
乘以50个矩阵后
tensor([[-6.4536e+12, 2.9500e+11, -3.1643e+12, 3.2686e+12],
[ 4.9242e+12, -2.2509e+11, 2.4144e+12, -2.4940e+12],
[-1.8533e+12, 8.4715e+10, -9.0872e+11, 9.3866e+11],
[-6.2537e+11, 2.8586e+10, -3.0663e+11, 3.1674e+11]])
可以看出经过五十次矩阵相乘之后,数值达到了1011−1012
在很长一段时间内,梯度爆炸和梯度消失曾是训练深度神经网络的阻力,但是选择初始化权重是解决该问题的有用的方法。
3.初始化权重
正如我们刚刚所说的,sigmoid激活函数容易导致梯度消失,因此,一个比较常用的方法是使用ReLU函数来当做激活函数,降低了梯度消失和爆炸问题。解决上述问题的另一种常用的方法是进行参数初始化。一个比较常用的方法就是Xavier初始化。它假定方差为:n[l−1]+nl2,还有人用tanh函数,使用nl−11,如果使用ReLu激活函数,有些作者建议使用 nl−12.实际上,我觉得所有这些公式只是一个调整的选择,它们给出初始化权重矩阵的方差的默认值,如果想添加方差,方差参数则是另一个我们需要调整的超参数。下面我们来看看如何实现初始化权重
"""定义一个神经网络"""
net = nn.Sequential(nn.Linear(4, 8), nn.ReLU(), nn.Linear(8, 1))
"""正态分布初始化"""
def norm(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, mean=0, std=0.01)
"""Xavier初始化"""
def Xavier(m):
if type(m) == nn.Linear:
nn.init.xavier_uniform_(n.weight)
net[0].apply(norm)
print(net[0].weight)
net[2].apply(Xavier)
print(net[2].weight)
Parameter containing:
tensor([[ 2.6455e-03, -9.4835e-03, -2.3148e-03, 7.3588e-03],
[ 8.4367e-03, -6.8525e-03, 4.5711e-03, 6.6946e-04],
[-1.7318e-03, -2.4081e-03, -5.8394e-03, 4.2219e-03],
[-8.6585e-03, 1.5090e-02, 1.2062e-02, 4.7167e-03],
[ 8.8256e-03, -7.8020e-05, -1.7378e-03, -2.5176e-02],
[-1.1565e-02, 1.7698e-03, -1.8693e-02, 8.1501e-05],
[-1.3891e-02, -6.1892e-03, -4.7369e-03, 9.8099e-03],
[ 3.5225e-04, 4.4494e-03, -2.1365e-03, 4.0189e-03]],
requires_grad=True)
Parameter containing:
tensor([[ 0.1272, 0.1947, -0.1398, -0.0676, 0.1016, -0.2671, -0.1270, -0.3072]],
requires_grad=True)
4.梯度的数值计算
在实施backprop时,有一个测试叫做梯度检验,它的作用是确保backprop正确实施。因为有时候,我们不能保证我们写的程序是完全正确的。为了实现梯度检验,我们首先说说如何计算梯度的数值逼近。假设给定一个函数f(x)=x3,根据数学分析中的知识,它的导数为f′(x)=3x2。根据微积分的知识,我们可以通过以下方式来逼近梯度,给定一个任意小的ϵ,有:
f′(x)approx2ϵf(x+ϵ)−f(x−ϵ)
假设x=1,ϵ=0.01,则有:f′(x)=3,f′(x)approx=2×0.011.013−0.993=3.0001,可以看出误差为0.0001,实际上,对于给定的一个ϵ,导数的逼近误差是O(ϵ2).有了这个基础,我们下面来看看如何进行梯度检验
5.梯度检验
梯度检验可以帮我们节省很多时间,接下来,我们看看如何利用它来调试或检验backprop的实施是否正确。假设网络中含有下列参数,W[1]和b[1]……W[l]和b[l],为了执行梯度检验,首先要做的就是,把所有参数转换成一个巨大的向量数据,我们要做的就是把矩阵W转换成一个向量,把所有W矩阵转换成向量之后,做连接运算,得到一个向量参数族θ,该向量表示为参数θ,损失函数J是所有W和b的函数,现在我们得到了一个θ的损失函数J(即J(θ))。接着,得到与W和b顺序相同的数据,同样可以把dW[1]和db[1]……dW[l]和db[l]转换成一个新的向量。
接下来对每个参数也就是对每个θ组成元素计算dθapprox[i]的值,使用刚刚介绍的梯度逼近。
dθapprox[i]=2εJ(θ1,θ2,…θi+ε,…)−J(θ1,θ2,…θi−ε,…)
根据上文的介绍我们知道(dθapprox[i])应该逼近dθ[i]=∂θi∂J,dθ[i]是代价函数的偏导数,然后我们需要对i的每个值都执行这个运算,最后得到两个向量,得到dθ的逼近值dθapprox,它与dθ具有相同维度,它们两个与θ具有相同维度,我们实际要做的就是验证这些向量是否彼此接近。具体计算公式如下:
check=∣∣dθ∣∣2+∣∣dθapprox∣∣2∣∣dθapprox−dθ∣∣2
具体怎么判断是否足够接近呢,这里要取决于我们选取的ϵ,假设选取的ϵ=10−5,如果上述得到的值为10−5或者更小,那么结果很好,如果为10−3,那么需要注意,可能这个值有问题。如果更大的话我们要考虑是否程序存在问题,需要检查一下。
本章的介绍到此介绍,如果文章对你有帮助,请多多点赞、收藏、评论、关注支持!!


