

分布式 SQL必知必会:YugabyteDB中的分片和分区
Franck Pachot 【hudson译】
2021 11月19日
分布式SQL数据库提供了一种服务,您可以查询全局数据库,而不知道行在哪里。您可以连接到任何节点,而不必知道集群拓扑。您查询表,数据库将确定对您的数据的最佳访问,无论您的客户是近在迟尺,还是远在天涯。
数据的组织,无论是位于同一位置还是分区,都是高性能、高可用性和地理分布的最重要考虑因素。YugabyteDB有几个功能特征在这里小试牛刀。这些特征可分为三个物理组织层次:
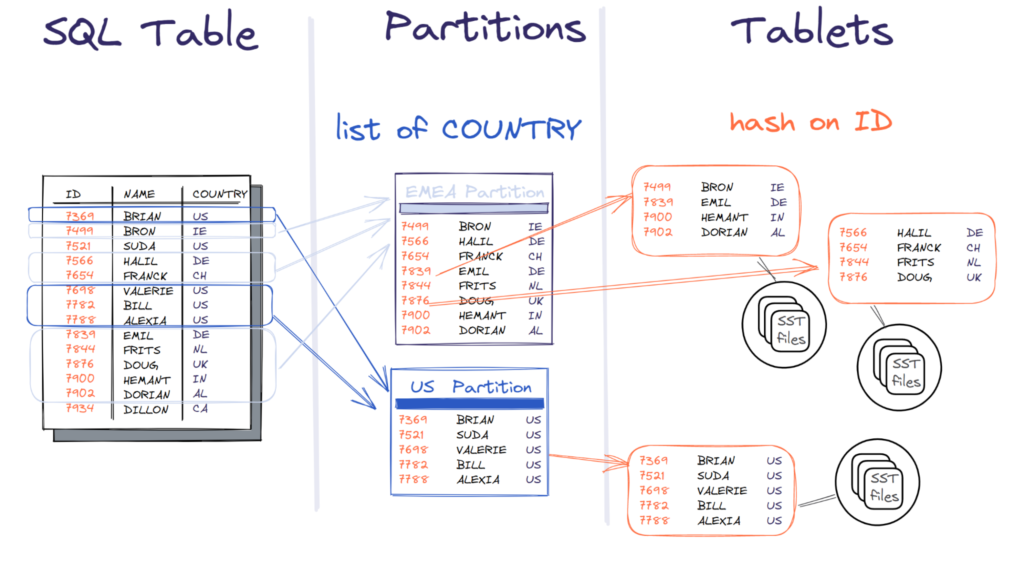
- 在查询级别(YSQL),使用PostgreSQL语法,用户根据列值将逻辑表划分为多个表。这称为表分区。
- 在存储层(DocDB),使用主键和索引列定义,我们将行分发到多个tablet中。我们称之为数据库分片
- 在文件级别,行或索引项存储在每个排序序列表(SST)中的键上。
在这篇博客文章中,我们将讨论YugabyteDB中分片和分区背后的相关术语和定义,并向您展示如何正确使用这两个术语和定义。
数据库分片与分布式
分区是一个通用术语,分片通常用于水平分区,以在无共享架构中扩展数据库。但这些术语用于不同的架构概念。但是,由于YugabyteDB同时提供了这两种功能,因此使用正确的术语非常重要。
在我们深入讨论YugabyteDB体系结构之前,这里是三个通用定义。
分片的应用
如果您将数据拆分为多个数据库,这可以称为分片。例如,假设您有一个EMEA客户数据库:一个用于美国,一个用于亚洲。应用程序根据用户的国家代码连接到一个或另一个。这称为应用程序分片,但不是分布式数据库。您不需要任何特殊的数据库,只需要一些自动化来管理它。您还可以使用单体数据库的多个实例。但这需要应用程序和操作中的大量代码来管理它。
分片数据库
如果您添加中间件来处理这部分附加代码,那么您将拥有一个分片数据库。例如,CitusDB运行多个PostgreSQL数据库,并添加一个主节点。您必须连接到主节点或聚合器,它们把查询或部分查询重定向到工作节点。Oracle分片与此类似,也使用分片控制器和连接池来协调卸载到许多数据库的工作。这种技术在数据仓库中大量使用,您可以将查询拆分并并行处理。但关系表上的OLTP事务必须跨多个分片维护索引和引用完整性。
分布式SQL数据库
在分布式SQL数据库中,没有主数据库或控制器。所有节点都是相等的。用户可以连接到任何想要的地方,并从那里查询整个数据库。每个节点都知道集群的拓扑结构、数据和元数据的位置、事务状态和序列下一个值(带有缓存),因为它是单个数据库。在不放弃最先进的关系数据库的SQL特性的情况下,还具有灵活性。
Yugabyte分布式SQL
既然我们已经定义了这些技术,让我们从存储层开始,深入了解YugabyteDB中的所有级别的数据组织。
“SST文件”
在较低级别,行和索引项的组织在Linux文件系统上的排序序列表(SST)中。这是在写入和压缩期间自动完成的,以便读取可以轻松找到行。每个SST存储按键和版本排序的行,并使用附加索引和b布隆过滤器来定位。就相同位置而言,具有相同散列值的键的行或索引条目以及在窄范围内的值存储在每个SST文件中。SST文件的数量受压缩限制。在这个级别上,YugabyteDB中的一切都是自动化的。用户只提供文件系统路径。
tablet分片
SST文件存储表和索引的键值对。分片在这里是正确的术语,因为每个tablet都是一个数据库(基于RocksDB ),具有 自身保护 。 这看起来像是分片。
SST文件存储表和索引的键值对。切分在这里是正确的术语,因为每个平板电脑都是一个数据库(基于RocksDB),具有 自身保护 . 除了它们不是SQL数据库,而是键值文档存储之外,这看起来像我们上面描述的分片数据库。它们具有可靠数据存储所需的所有功能,具有事务和强一致性。但是,由于SQL层位于上面,因此它们不需要将它们作为多个数据库进行管理。表连接和二级索引不在此级别处理,因为这会防止跨分片事务。
根据SQL数据模型选项,分片是自动的:
-
colocated属性或tablegroup定义了哪些SQL表(即索引或分区,我们将在后面看到)被分片为多个专用tablet,哪些表。是相同位置、哪些是复制而不是分片。
-
主键或索引列定义分片方法,哈希或范围(ASC或DESC)方法。在列上应用哈希方法分发数据可以实现负载平衡和避免热点 ,在升序或降序的列上使用范围方法可以保持行在一起(如“<”、“>”、“BETWEEN”谓词)
-
可选地,在系统级使用“--ysql_num_tablets”或在索引级 SPLIT AT/INTO 这些附加信息中设置tablet数量。
通过分片,我们在元数据级别定义了数据模型的分布方法。但在数据级别,这是自动完成的:分布式存储层管理必须写入或读取行或索引项的位置。这种方法足以满足许多应用:
- 将小表放在同一地方以减少内存占用。
- 将大型和不断增长的表切分为多个tablet,每个节点一个(或多个),以便在添加更多节点时能够重新平衡和扩展。
- 对于分片表,当使用范围谓词查询在一起的行时,考虑范围扫描将访问哪些列。
表分区
前面讨论的分片方法认为所有节点都是相等的,无论它们位于同一数据中心还是多个可用性区域(AZ)。您需要跨所有计算和存储实例进行负载平衡,并根据需要进行扩展。数据的组织在表和索引层面决定。但是,您可能希望进一步根据行的值对行进行更多控制。SQL层面的三种表分区,HASH,RANGE和 LIST COLUMN在此派上用场。这是一个PostgreSQL特性,称为声明性分区,可以与YugabyteDB一起使用,因为它与PostgreSQL完全代码兼容。
除了分区修剪之外,分区的主要原因是信息生命周期管理。如果您按月份或年份进行分区,清除旧数据就像删除分区一样简单。这是唯一可扩展的方法。
在分布式SQL数据库中在这个级别进行分区的另一个原因是,您希望将某些数据限制到特定位置,例如:
- 出于法律原因,当您被要求存储特定地区某些国家的数据时。
- 因为数据接近用户,确保可预测的响应时间。
- 出于成本原因,降低跨AZ、跨地区或跨云提供商网络流量。
对于最后一个选项,分区映射到表空间。表空间在PostgreSQL中用于将分区存储在特定的文件系统中。使用YugabyteDB 创建表时指定位置属性如云区域、区域和 云提供商等可将表空间映射到集群拓扑。
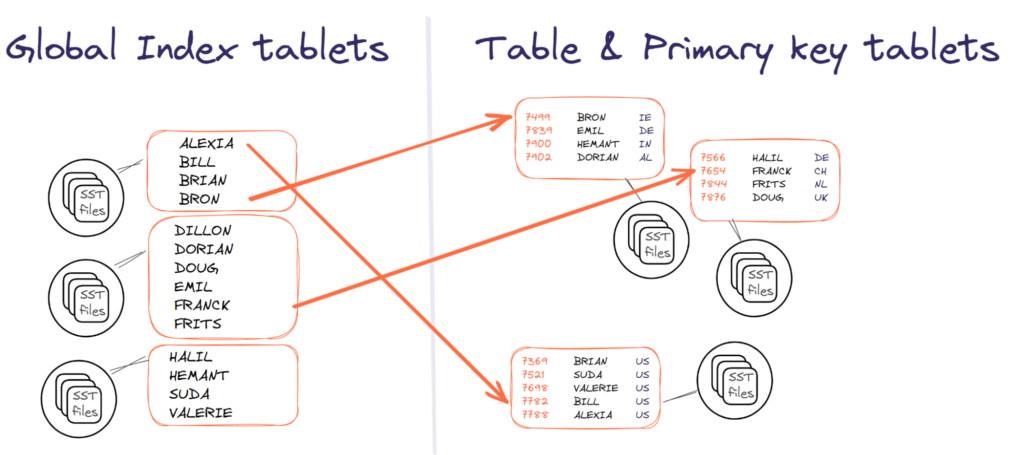
全局索引
在描述了数据分布的级别之后,让我们解释为什么我们需要所有这些级别。SQL,特别是OLTP,非常复杂。您有多个键,通常是一个代理键和一个或多个自然键。它们都需要由一个唯一索引来保证。由于表只能在一个键上进行分区,所以其他表需要全局索引。全局索引可以分区,但不能与表位于同一个键上。
使用YugabyteDB,上述tablet将表的行和索引项存储为键值对。这是为了实现行分布的高性能和同步复制的高可用性。如前所述,当分片数据库在这个级别添加SQL时,会有严重的限制:SQL特性仅限于单个分片。这意味着索引仅是本地的,外键只能在交错表上得到保证,事务不能触及多个分片中的行。我们回到了一个层次型数据库,只能通过主键访问表。
在OLTP应用程序中,有一个主键,它是从序列或uuid生成的代理键,用于获得不可的变标识符。但还有一些自然的键,需要用一个唯一约束保证。这就是为什么我们使用SQL数据库:多访问路径和完整性约束,以较少的应用程序代码保护数据。数据仓库可以接受非事务性全局索引,但这对于OLTP是不可取的。为避免数据损坏也需要保证唯一约束,如故障后的双重写入或逻辑复制。
让我们举一个简单的例子:一个国家的公民表,其中自然键是社会保障号码,用唯一约束来保证。主键是一个生成的数字,是不可变的,然后可以被外键引用。
对于像CitusDB这样的分片数据库或任何其他基于外部数据包装器的数据库,不可能做到这样。因为每个分片都是一个整体数据库,所以不能跨多个数据库保证唯一性。如果在代理主键上按哈希进行分片,则可以保证其唯一性,外键可能从同一分片中获得。但无法保证自然键的唯一性=。每个分片中都有SQL特性,但不是全局的。
对于该表,您需要的是在主键上对表进行分片,通过外键进行连接,并在自然键上对索引进行分片以按业务值进行查询。这就是需要全局索引的地方。在上面,表可以按国家划分,以将每个大陆隔离为一个物理区域。在这里,本地索引是足够的,因为目标是分区放置,而不是数据分布。
总结
对于像YugabyteDB这样的分布式SQL数据库,分片到tablet的目的是在行级别扩展。除此之外,还可以创建唯一约束、二级索引、外键约束和事务。分区和表空间提供了对物理位置的更多控制。分布式SQL数据库需要将两者结合起来,然后作为一个数据库应用程序公开,可以透明地连接到任何节点。tablet上的分片(对行和全局索引条目应用散列或范围函数)操作用于数据分发, 分区在表分区(定义表时应用范围或列表策略)上进行数据放置,并使用本地索引。tablet切分适用于YCQL和YSQL,但分区是YSQL的特性。
YSQL的概念和语法是PostgreSQL CREATE TABLE和CREATE INDEX语句的扩展。在YCQL中,您可能会看到用于tablet自动分片的一般术语“分区”。这是它在Cassandra中的名称,在YCQL中没有表级声明性分区。
