

分布式SQL分片:有多少个tablet,每个大小如何?
Franck Pachot 【hudson译】
2022年6月17日
这个问题的第一个答案是通常是“看情况”。第二个答案,感谢YugabyteDB的自动拆分功能和分布式SQL分片原则:“别担心,这是自动管理的。”
然而,了解分片的工作原理、如何正确处理边界情况以及如何拆分tablets以节省资源仍然很重要。在这篇文章中,我们将通过定义tablet的初始数量和大小来探索分片在YugabyteDB中的工作方式。
什么是分布式SQL分片?
不同的数据库使用术语“分片”:从手动将数据隔离到几个单体数据库,到在多个服务器上分发小块数据。YugabyteDB通过将表的行和索引项拆分为tablet来分发数据。
在分布式SQL数据库中,分片是自动的。您可以根据访问模式选择分片方法:范围或散列。然后,您可以定义tablet的初始数量,然后手动拆分。或者让数据库自动拆分它们以跟踪数据的增长。
但是,即使在完全自动化的情况下,您也可能需要调整控制拆分算法的旋钮。或者,至少要理解它们,这样您的手动操作就不会适得其反。默认设置适合一般情况。但即使如此,数据库也可能具有不同的表数量、大小和工作负载。
什么是tablet?
在查看这些旋钮之前,您应该先了解它们控制的是什么:每台服务器的tablet数量及其大小。从YugabyteDB的yb master web控制台查看这些数字很容易。
/table 端点显示表的总大小:

/tablet 端点显示所有tablet,包括其状态和对应的成员(领导者和追随者):
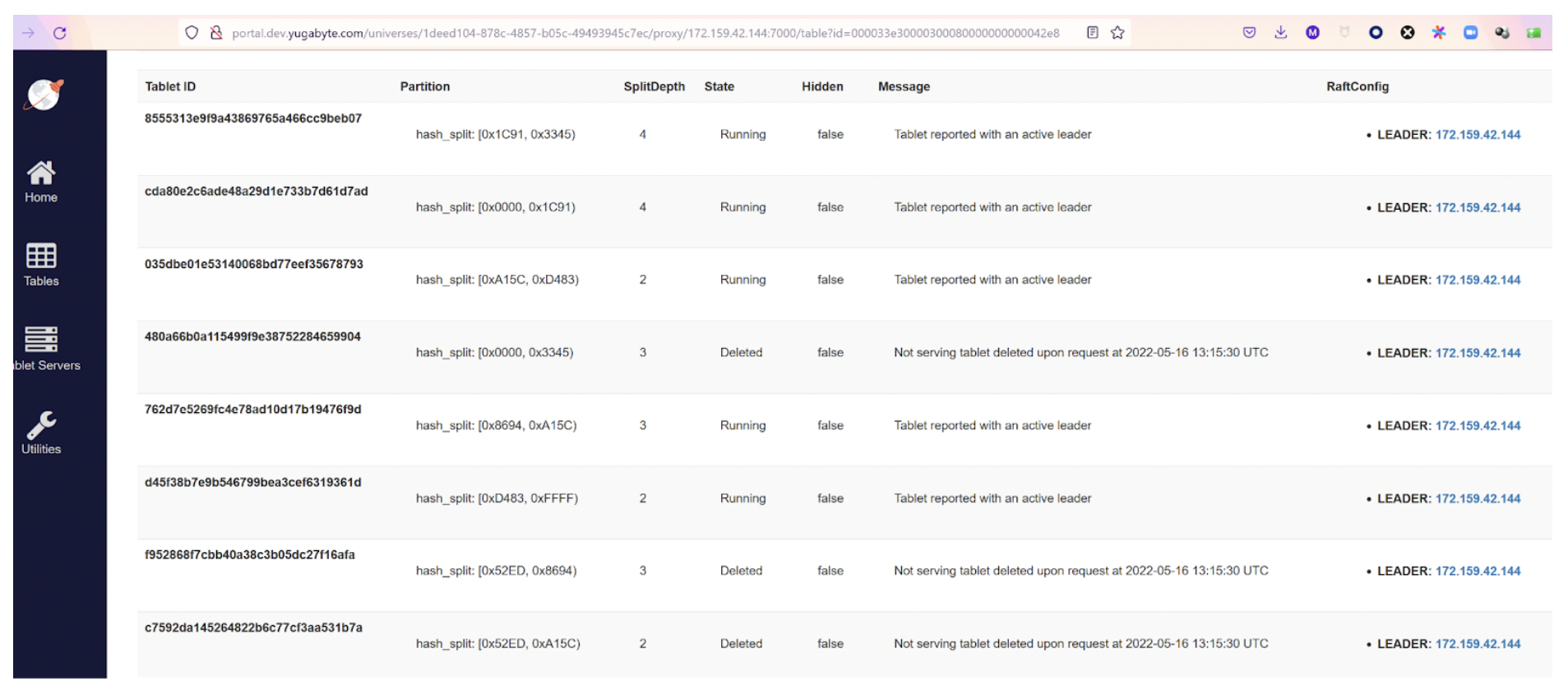
上面的屏幕截图显示了单节点集群(RF=1)上35GB的表,其中自动拆分创建了8个tablet。在自动拆分的“低阶段”,它们将分别增长到10GB。但这是在进入“高阶段”之前,在该阶段,自动拆分不会很积极。
我们没有显示所有这些,我们可以看到一些“已删除”的前一个拆分。每次拆分都会增加拆分深度,对于创建表(或索引或分区)时创建的tablet,拆分深度为1。拆分实际上是一个在线复制,元数据标记了新的边界。稍后,压缩操作将清除每个新tablet边界外的数据。
你对此有何看法?tablet的正确数量和正确尺寸是多少? 每个tablet 成员是一个基于RocksDB的轻量级数据库,通过tablet raft组进行更新。因为是“轻量级”,每个节点可以有数百个tablet,这取决于计算实例的大小、vCPU、RAM和连接到它的存储。当然,他们的活动也很重要。即使目标是避免热点,但并非所有表都具有恒定的活动。
多个tablet和弹性
在云原生环境中,拥有多个tablet是分布式数据库弹性的必要条件。添加新节点时tablet可以自动重新分配。限制tablet的大小对于初始化一个新tablet成员非常重要,可避免大量文件传输。
然而,每个tablet都不仅仅是一小块数据。即使它们共享一些线程和内存,tablet也是独立的,因为它们有自己的raft组。它们发送自己的心跳,并有自己的WAL(提前写入日志)保护。他们也有自己的LSM树数据存储:内存中的memtable和磁盘上的许多SST文件。
一个tablet成员的存储实际上是一组两个增强的RocksDB数据库。一个是常规数据库,存放提交数据。一个是意向数据库,保存临时记录和锁,直到多分片事务结束。服务器为每个数据库都分配了一些内存。此外,服务器还需要为文件缓冲区保留大量可用内存。
寻找理想的 tablet 尺寸
限制tablet尺寸至关重要。但我们也不希望每台服务器有太多的tablet。这意味着理想尺寸的答案不止一个数字。这就是为什么控制自动拆分的旋钮定义了tablet数量和最大尺寸的阈值。大致来说,理想的最大tablet尺寸是几十到几百GB。并且一个节点每个vCPU可以容纳数十个tablet。当然,这取决于内存以及有多少活动的tablet。但在了解这一点之前,了解SQL数据库中表的数量和大小是很重要的。
当您构建一个新的现代应用程序时,您将使用应用自己的模式和有限数量的表来开发微服务。但YugabyteDB与PostgreSQL兼容,还用于将现有应用程序迁移到云原生基础设施。
遗留应用程序充满了极端。我见过有60000个表和未分区的表的模式,其中包含数十亿行和TB的数据。我还看见到每个表有多达30个索引。然而,有一个共同的模式。表被分解为几种类型:小的静态表、中等缓慢增长表和非常大的表。
分布式SQL分片中的小型静态表
一个关系模式有很多很少改变的小表,它们不会增长。这些是查找表或引用表。它们将成为数据仓库模式中的小维度。此外,它们通常位于多对一关系的末尾,有时处于多级层次结构中。例如,订单输入应用程序中的一些表可能是国家、城市和货币汇率。
小并不意味着您不想分发它们,因为它们经常通过表连接访问,并且您不希望所有查询都从同一个节点读取。然而,由于它们很少更新,因此最好广播它们而不是拆分它们。为此,您可能只将表存储在一个tablet中,并且在低于所有自动拆分阈值的情况下,它们将保持为一个tablet,覆盖整个值范围。但要分发它们,您将创建重复覆盖索引。
覆盖意味着索引将存储所有列,或者存储在索引键中或者存储在索引的“include”列表中,以便永远不会读取表。重复意味着您需要在每个云区域、地理区域或数据中心创建相同的索引,并通过表空间放置策略从任何连接获得低延迟。写操作将更新所有索引,但这对于不频繁的小更新不是问题。您仍然具有强大的一致性和在更新时完全事务性的优势。
在自动拆分默认配置中(我这篇文章基于2.13.3创作) ,这些表的所有tablet领导者都小于
tablet_split_low_phase_size_threshold_byte
其默认设置为512MB,低于该值后不会再拆分tablet,即使
enable_automatic_tablet_splitting
也设置为true,这是此预览版本中的默认值。
分布式SQL分片中的中等缓慢增长表
有些表具有频繁的读写活动,最初是中等规模,然后缓慢增长,通常是1GB到10GB 的表,这时需要考虑其大小。但在一个单体数据库中,它们通常不值得进行复杂的分区。在订单输入应用程序示例中,客户和产品表属于在此类别。你需要将它们分布以增加可伸缩性,即使它们不是很大。
进入自动拆分“低阶段”
这是当tablet超过如下阈值时,表和索引的自动拆分进入“低阶段”
tablet_split_low_phase_size_threshold_byte
,默认设置为512MB,以tablet领导者中SST文件的大小衡量。目标是积极地分发(数据),获得可伸缩性,特别是在初始加载期间,即使它们远未达到所需的tablet大小。然而,我们也不需要太多的tablet,因此,在表的(tablet)达到下面阈值时,(自动拆分)会停止
tablet_split_low_phase_shard_count_per_node
平均来说,每个服务器的每个表的默认值是8个tablet。
表、索引或分区将停留在这个“低阶段”,平均每个服务器有8个tablet(计算为tablet总数除以容纳tablet服务器数量)。这些tablet会一直生长直到它们达到
tablet_split_high_phase_size_threshold_bytes
,默认为10GB。这将使表切换到“高阶段”。这意味着,在再次自动拆分之前,表可能会达到每个节点8x10GB=80GB左右。在RF=3的情况下,有3个节点,这意味着当我们包括其他节点中的领导者的追随者时,该表(或索引或分区)将在每个节点的磁盘上占用240GB的空间来存储其SST文件。
因此,最后,对于集群中占用720GB的表来说,仍然是低阶段。在更大的集群上,该大小将平衡到更多节点,并且在达到每个节点的tablet数量限制之前,表将增长更多。您可以看到,我称之为“中等”的表处于自动拆分的低阶段,在具有多个节点的集群中可能是一个大表。这就是为什么我们将下一类称为“非常大的表”。但在此之前,让我解释一下“表”在存储级别是什么。
分布式SQL分片中的表、索引或分区
让我澄清我所说的“表”是什么意思。DocDB中的“表”,YugabyteDB中分布式事务和存储层,存储tablet,可以是YSQL(PostgreSQL接口)中的任何持久“关系”:
- 非分区表
- 非分区索引
- 表的分区(由PostgreSQL声明性分区创建)
- 分区表的本地索引
- 物化视图
如果您曾经使用过Oracle数据库,您将其称为“段”——持久数据库对象的存储部分。但YugabyteDB分布节点,以便在无共享基础设施上实施扩展。
YugabyteDB使用分片分发来自表和二级索引的数据。在此之上,PostgreSQL声明性分区(按范围或列表)控制了这种分布。例如,出于延迟或法律目的,你可以将分区的分布限制为本地区域。关于自动拆分和tablet大小的话题,我们讨论的是分布,或DocDB中的tablet。在这里,未分区的表和索引或表和索引分区是类似的:表的主键或二级索引的索引列按哈希或范围进行拆分。
分布式SQL分片中的超大表
根据集群的大小,自动拆分的“低阶段”对数百GB的表自动拆分,每个节点最多8个tablet,以便从所有CPU能力中获益。但是,对于更大的表,当这些tablet的尺寸太大而无法轻松移动数据时,它们会增长并分裂。这是“高阶段”将再次分裂的地方,但阈值较高:
tablet_split_high_phase_size_threshold_bytes
其默认值为10GB。
当(tablet个数)达到下面阈值时,高阶段分裂停止
tablet_split_high_phase_shard_count_per_node
默认值是每节点24个。同样,将该“分片计数”阈值和表的tablet数量除以容纳领导者的服务器数量后进行比较,以确定高阶段何时结束。 将“大小阈值”和tablet与领导者的SST文件(用于常规RocksDB)的总和进行比较,以确定要拆分哪些tablet 。
控制大型表的自动拆分
此阶段控制大型表的自动拆分,因为它们平均每个节点可以达到24x10GB=240GB,在大型集群中可能是TB,在复制时可能更多。听起来非常大吗?不要忘记分区。这些非常大的表可能是分区的,这里提到的大小是每个分区。
此类别中的表是系统中不断增长的表,如订单输入系统中的订单和订单项。设想一下,这些将成为数据仓库中的事实表。但是,即使在OLTP中,如果由于法律原因(例如,按国家/地区)未对它们进行列表分区,则它们可能按日期进行范围分区。因为数据库系统保留了不太频繁使用的冷数据,所以您可以按月份或年份进行分区,以保持本地索引较小。总有一天,您会想归档或清除旧数据,您可以通过删除旧分区来高效地做到这一点。然后,上面提到的TB是每个分区的,对于数百TB的表。
分布式SQL分片中的巨大表
我们不希望tablet无限增长,以至于它们变得太大,无法在新节点上操作如启动等。因此,在“高阶段”达到每个节点每个表24片之后,仍然存在一些拆分活动。但该限制很高:
tablet_force_split_threshold_bytes
默认设置为100GB。
对于数百TB的数据库,您应该花时间考虑一下,并检查您的系统,以了解大量tablet的后果。是否要继续拆分使每台服务器超过24个tablet?或者,可能与不断增长的系统最相关的是:您会扩展集群吗?这将重新平衡tablet,减少每台服务器上每个表的tablet数量,然后允许在高阶段继续自动拆分。这也取决于整个模式:在这个巨大的表类别中有多少表?它们都是活动的,还是旧分区中有冷数据?你把它们分开了吗?
不要忘记,这些阈值是针对每个数据库节点的,因此它们仍然适用于大型集群。它们是基于每个表,这意味着每个节点上会有更多的tablet。当您通过添加新节点进行扩展时,达到低或高阶段阈值的tablet将重新平衡并再次拆分。
结论
在使用分布式SQL分片将遗留应用程序移植到YugabyteDB时,最好按照以下类别来限定表及其索引:
- 许多小表,无需分发:使用单个tablet创建它们,或者,如果在一个小集群中有许多表,则考虑共同定位或表分组
- 小型参考表经常读取阅,很少更新:使用重复的覆盖索引广播它们,再次使用单个tablet
- 中大型表,缓慢增长:定义散列或范围分片,并在加载后立即自动拆分和分发,以便有足够的tablet最大限度地利用集群资源
- 随着业务活动而增长非常大的表:考虑分区,目标是将来存档或清除,每个分区将遵循大表建议
可以更改默认阈值。然而,归档旧数据或扩展集群是正确的方法。当您已经知道未来的容量时,您可以通过在CREATE语句中定义tablet的初始数量来节省时间和资源。现在你知道了自动拆分何时启动和停止,知道如何直接到达“高阶段”。这是通过将服务器数量乘以
tablet_split_high_phase_shard_count_per_node
并定义tablet的数量。
当您有许多不在同一位置或表组中的小表时,不要为它们创建许多tablet。这是通过以下方式实现的:
SPLIT INTO 1 TABLETS
或设置群集标志
ysql_num_tables=1
作为默认值,或者仅通过启用自动拆分,而不使用拆分子句,它们从1开始。
所有数据库都是不同的,所以如果你需要针对你的环境建议,请不要犹豫伸出双手提。来自社区的反馈有助于适应用户案例的多样性。
