价值学习与策略学习(Value-Based and Policy-Based)
1. 价值学习
review:
Discounted return
Ut=Rt+γRt+1+γ2Rt+2+γ3Rt+3+⋯
Action-value function
Qπ(st,at)=E[Ut∣St=st,At=at]
Optimal acition-value function
Q⋆(st,at)=maxπQπ(st,at)
1.1 DQN
概念:deep Q-network, 就是用神经网络近似Q∗。
理解:
-
目标:最大化奖励
-
问题:假设知道了Q∗(s,a),哪个是最好的动作? a⋆=aargmaxQ⋆(s,a)
-
挑战:如何求出Q∗(s,a)
-
方法:DQN:使用神经网络近似Q∗(s,a)
举例:
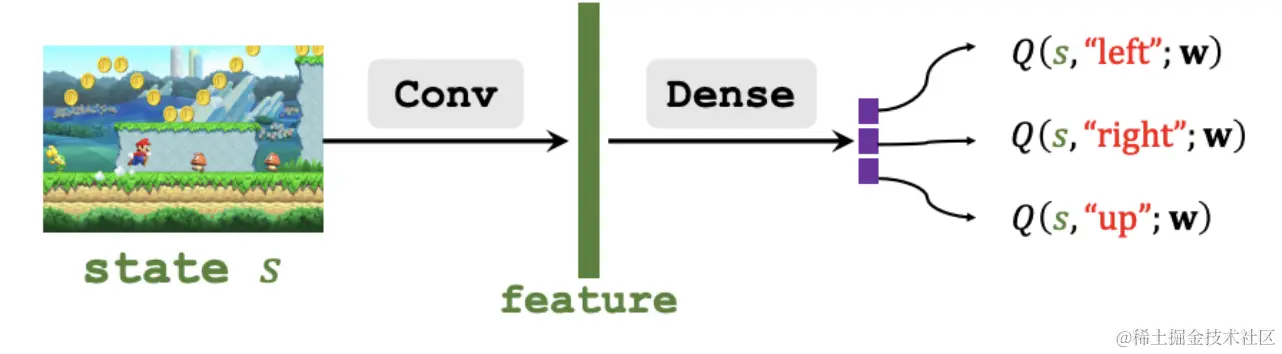
上图中,神经网络接收画面作为输入,通过卷积转换为特征向量,输出对动作的打分。
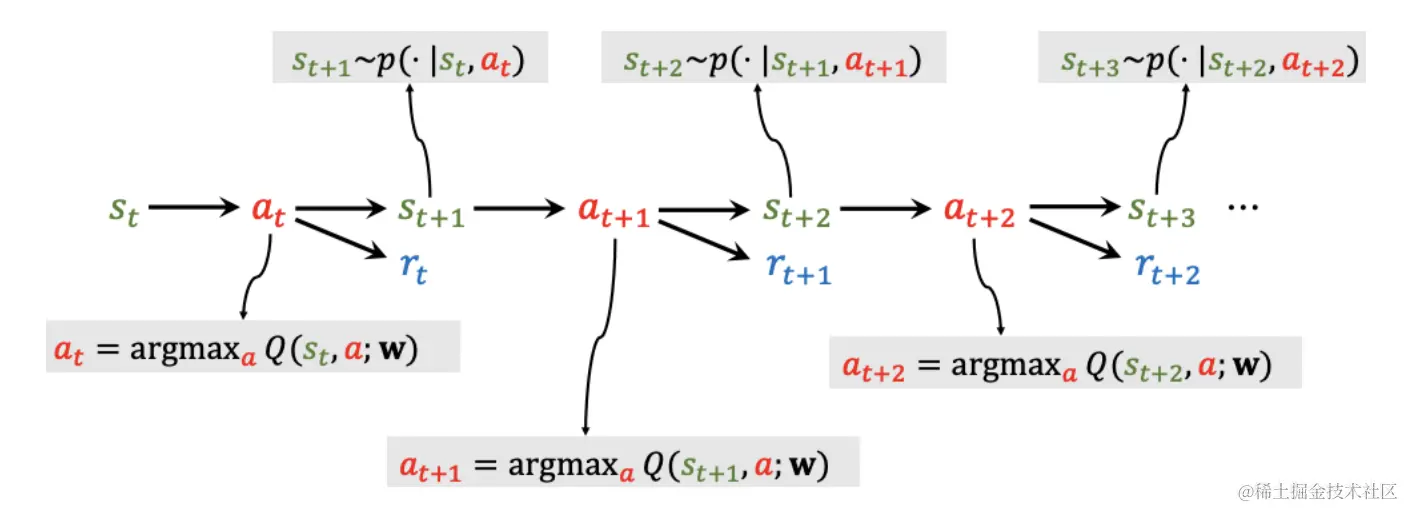
在下图中,观测中环境状态st,用DQN at⋆=aargmaxQ⋆(s,a),输入状态st,输出所有动作得分,得出最高分的动作at。执行动作后,环境会发生变化,用状态转移函数p(⋅∣s∗t,a∗t)随机抽样得到一个新状态st+1,这时会得到这一步的奖励rt,奖励是强化学习中的监督信号,DQN靠这些奖励来训练。如此循环。
1.2 TD学习
如何训练DQN,最常用的是Temporal Difference Learning
Q(st,at;w)=rt+γ⋅Q(st+1,at+1;w)
左边是DQN在t时刻做的估计,这是未来奖励总和的期望,右边是在t+1时刻做的估计,其中rt是真实观测到的奖励。
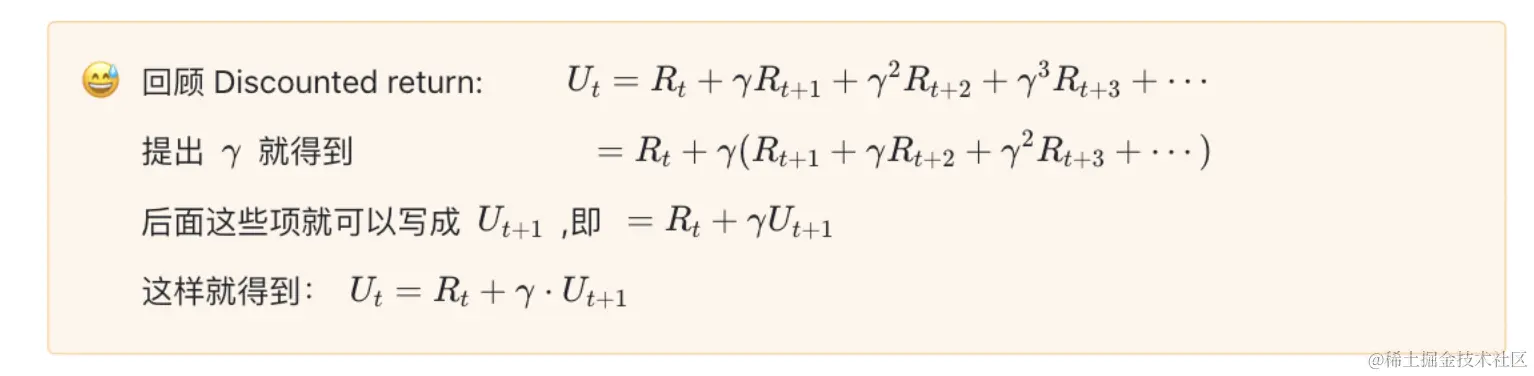

训练过程:
-
t时刻模型做出预测Q(st,at;w)
-
t+1时刻,观测到了rt,采样出新的状态st+1,然后计算出新的动作at+1(这个也是通过Q函数计算的分数最高的动作)
-
可以计算TD target记作yt,其中yt=rt+γ⋅Q(st+1,at+1;w)
-
我们希望Q(st,at;w)尽可能接近TD target,从此计算Loss:Lt=21[Q(st,at;w)−yt]2
-
梯度下降:wt+1=wt−α⋅∂w∂L∣∣w=wt
1.3 总结
-
通过最优价值函数Q∗(st,at)=E[Ut∣St=st,At=at],对Ut求期望,就能对每个动作打分,反应每个动作的好坏程度,用这个函数来控制agent。
-
DQN是一个深度神经网络,Q(s,a;w),来近似Q∗(s,a)
-
DQN的训练需要用TD算法求解。
2. 策略学习
review:
策略函数π(a∣s)输入的状态s,输出的是一个概率分布,给每一个动作附上一个概率值。
折扣回报函数:
Ut=Rt+γRt+1+γ2Rt+2+γ3Rt+3+⋯
动作价值函数:
Qπ(st,at)=E[Ut∣St=st,At=at]
状态价值函数:
Vπ(st)=EA[Qπ(st,A)]消掉的动作A,这样Vπ只和状态s和策略函数π有关了。可以评价当前状态的好坏。
-
Vπ(st)=EA[Qπ(st,A)]=∑aπ(a∣st)⋅Qπ(st,a) 这里的动作是离散的
-
Vπ(st)=EA[Qπ(st,A)]=∫π(a∣st)⋅Qπ(st,a)da 这里的动作是连续的
2.1 策略网络
用神经网络π(a∣s;θ)来近似策略函数 π(a∣s)
举例:
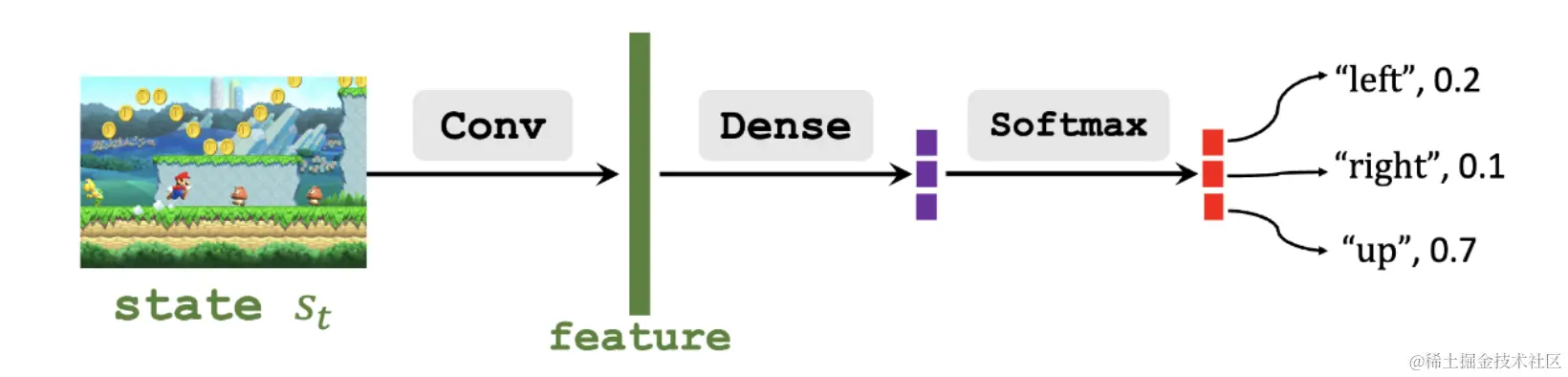
状态画面经过卷积提取特征,特征经过全连接层再通过softmax层得到一个动作的概率分布,动作的概率集合全部加起来要等于1。
2.2 策略学习


2.2.1 策略梯度


综上,推导出了策略梯度两种形式
Form1:∂θ∂V(s;θ)=a∑∂θ∂π(a∣s;θ)⋅Qπ(s,a)
Form2:∂θ∂V(s;θ)=EA∼π(∣∣s;θ)[∂θ∂logπ(A∣s;θ)⋅Qπ(s,A)]
2.2.2 计算随机梯度


2.3 策略梯度算法过程
-
观测到状态st,接下来用蒙特卡洛近似来计算梯度
-
把策略网络π(⋅∣s;θ)作为概率密度函数随机采样动作at
-
计算价值函数的值,记作qt≈Qπ(st,at)
-
对策略网络进行求导,得到向量矩阵或张量:dθ,t=∂θ∂logπ(at∣st,θ)∣θ=θt
-
近似计算策略梯度:g(at,θt)=qt⋅dθ,t
-
更新策略网络:θt+1=θt+β⋅g(at,θt)



