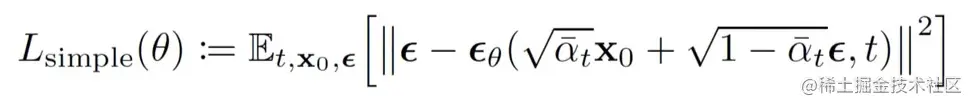前面推导了一些铺垫知识,现在正式来看diffusion Model。
3 diffusion models

我们说的扩散过程,就是从x0到xT的过程,也就是墒增的过程,从有序到无序。反过来是叫做逆扩散过程。
所以可以看到,q模型是一个加噪音的模型,p模型是一个去噪音的过程。
3.1 扩散过程
- 给定初始数据分布x0∼q(x),可以不断向分布中添加高斯噪音,该噪音的标准差是以固定值βt而确定的,而均值是以固定值βt和当前t时刻的xt决定的。这个过程是一个马尔可夫链过程。
- 随着t不断增大,最终数据分布xT变成了一个各向独立的高斯分布。
q(xt∣xt−1)=N(xt;1−βtxt−1,βtI)
q(x1:T∣x0)=∏t=1Tq(xt∣xt−1)
- 这里会用到参数重整化的技巧,我们知道xt服从这个正态分布,所以我们从标准正态分布中采样出z,然后与1−βtxt−1均值相加,与βt标准差相乘。
这里βt>βt−1
这里推导一下,我们的xt可以表示为xt−1的函数,也可以表示为x0的函数。我们这里设定αt=1−βt
xt=αtxt−1+1−αt∗z
上面公式中z为正态高斯分布,且利用了参数重整化的技巧。(reparameterization trick)
xt=αt(αt−1xt−2+1−αt−1∗z)+1−αt∗z
=αtαt−1xt−2+αt(1−αt−1)z+1−αtz
两个高斯分布相加a+b,那么新分布的方差是a2+b2.所以上面公式可以化简成:
=αtαt−1xt−2+1−αtαt−1z
所以我们继续递归上面公式,可以得到:
xt=∏i=1tαix0+1−∏i=1tαiz
设置αtˉ=∏i=1tαi
则q(xt∣x0)=N(xt;αtˉx0,(1−αtˉ)I)
所以我们大概可以计算出来,当t需要多大的时候,αtˉ是接近0的,就是独立同分布。
这里就可以看出来扩散模型和VAE的区别,从x到z的过程,vae是一个网络预测出来的z,而且并不能保证z和x是无关的;而扩散模型的扩散过程是一个无参的过程,并且z是一个各项同分布的一个分布,与x完全不相关。此外扩散模型的z和x是同尺寸的,而vae没有这个需求
当样本有着越来越多噪音的时候,可以采用更大的update step:
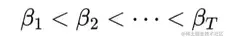
3.2 逆扩散过程
pθ(xt−1∣xt)=N(xt−1;μθ(xt,t),Σθ(xt,t))
现在我们需要推导一下后验扩散条件概率q(xt−1∣xt,x0)。
q(xt−1∣xt,x0)=q(xt,x0)q(xt−1,xt,x0)
=q(xt∣x0)q(x0)q(xt∣xt−1,x0)q(xt−1∣x0)q(x0)=q(xt∣xt−1,x0)q(xt∣x0)q(xt−1∣x0)
因为这是马尔可夫过程,所以q(xt∣xt−1,x0)=q(xt∣xt−1)
现在我们要重点考虑这个部分:
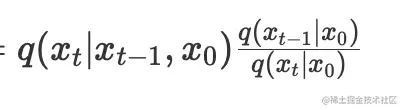
前者是:
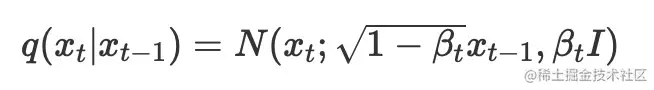
后者是:
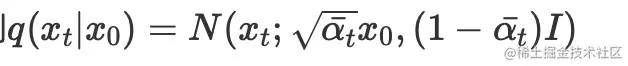
我们只考虑指数部分,因为系数部分一定是正数,所以成正比关系。
q(xt∣xt−1,x0)q(xt∣x0)q(xt−1∣x0)
∝exp(−21(βt(xt−αtxt−1)2+1−αˉt−1(xt−1−αˉt−1x0)2−1−αˉt(xt−αˉtx0)2))
我们要求解xt−1,所以将上面公式整理一下形式:
exp(−21((βtαt+1−αˉt−11)xt−12+(βt−2αtxt+1−αˉt−1−2αˉt−1x0)xt−1+C(xt,x0))
后面顶不住了。。先歇着吧