本文已参与「新人创作礼」活动,一起开启掘金创作之路。
分类问题 (一) : 基本定义
本节主要介绍三个部分,第一部分讲解分类问题中的三个主要任务的定义,第二部分讲解交叉熵的基本概念为后面博文做铺垫,第三部分从最大似然角度来对交叉熵进行解读
任务类别
分类问题中有多个任务,例如二分类,多分类以及多标签等,这里分别介绍下基本概念
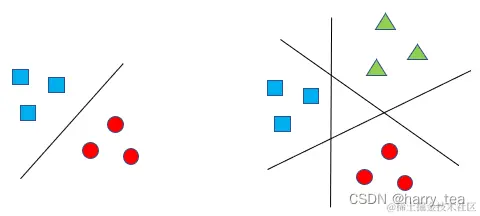
- 二分类:分类任务中只有两个类别,比如我们的任务是判断一个动物是不是猫,或者是猫还是狗。我们输入一张图到分类器中,用特征向量x表示,通过分类器输出得到0或1,其中0表示一个类别,1代表另一个类别。每个样本有且仅有一个标签
- 多分类:分类任务中有多个类别,比如判断一个动物是猫、狗还是猪等。我们输入一张图到分类其中,通过分类器输出得到几个概率,分类最大的概率对应相应的动物。每个样本有且仅有一个标签
- 多标签分类:多标签分类是给一个物体多个属性,比如我们一个动物如果是猫,那就不能是狗,但是一个动物比如猫他可以有多个标签,例如宠物,可爱等。每个样本可以有多个标签
在第二篇博文介绍损失函数之前,这里先介绍熵特别是交叉熵的概念,在分类任务中,我们更多地是使用交叉熵损失而非均方差损失
交叉熵
首先介绍信息量的概念,然后进而到熵,相对熵和交叉熵
信息量
定义:假设X是一个离散型随机变量,取值为集合X=x0,x1,...,xn,其概率分布函数为p(x)=P(X=x),x∈X,定义事件X=x0的信息量为
I(x0)=−log(p(x0))
其中当p(x0)=1时, 事情必然发生,信息量为0
信息量是用来衡量一个事情含有的信息量的多少(一个事件的不确定性),一件事情发生的概率越大,不确定性越小,含有的信息量就越小
信息熵
定义:信息量是衡量某个事件的不确定性,而信息熵是衡量一个系统(所有事件的不确定性)
H(x)=−i=1∑np(xi)log(p(xi))
其中p(xi)为事件X=xi的概率,log(p(xi))为事件X=xi的信息量
对于一个事件或者一个系统,也可以理解为一个随机变量,具有不确定性。香农指出“信息使用来消除随机不确定的东西”,并就此提出了信息熵的概念,也就是说当我们对某个事件不清楚的时候,他的信息熵是最大的,比如今年LOL全球总决赛的冠军是谁?这个事情就有很大的信息熵,根据香农所指出的,当我们提供更多的信息的时候,他的熵就会变小,比如今年LPL的冠军是EDG,那么我们猜测全球总决赛冠军的时候就会有所倾向的猜测EDG,而不是其他队伍,“EDG在LPL夺冠”这件事情就给我们带来了很多的信息,让“LOL全球总决赛的冠军是谁”这个不确定事件的信息熵变小了
信息熵是衡量一个系统的混乱程度,代表系统中信息量的总和,信息熵越大,表明这个系统的不确定性就越大.通过和信息量的对比发现,信息熵是信息量的期望值,是一个随机变量(一个系统,事件所有可能性)不确定性的度量,熵值越大,随机变量的取值就越难确定,系统就越不稳定;熵值越小,随机变量的取值也就越容易确定,系统越稳定
相对熵
定义:假设p(x),q(x)分别是离散随机变量X的两个概率分布,则p对q的相对熵是
DKL(p∣∣q)=i∑p(xi)log(q(xi)p(xi))
相对熵有一些性质
- 如果p(x)和q(x)的分布相同,则其相对熵等于0
- DKL(p∣∣q)=DKL(q∣∣p),相对熵不满足对称性
- DKL(p∣∣q)≥0
相对熵也被称为KL散度,表示同一个随机变量的两个不同分布间的距离(这句话是否有些熟悉?在机器学习或者深度学习的实验中,数据的真实分布为p(x),这个分布我们是不知道的,但是他真实存在,比如我们有一些猫的图片,他一定是服从某个分布的,只不过我们不知道这个分布具体是啥。随后我们需要设计一个模型算法来估计这个分布,假设我们的模型估计的分布为q(x),我们的最终目的就是让q(x)去无限的接近p(x)。为了让着两个分布尽可能得相同,就需要最小化KL散度)
交叉熵
定义:假设p(x),q(x)分别是离散随机变量X的两个概率分布,其中p(x)是目标分布,p和q的交叉熵可以看作是,使用分布q(x)表示目标分布p(x)的困难程度
H(p,q)=i∑p(xi)logq(xi)1=−i∑p(xi)logq(xi)
这里我们将三个熵放在一起
H(x)=−i=1∑np(xi)log(p(xi))DKL(p∣∣q)=i∑p(xi)log(q(xi)p(xi))=i=1∑np(xi)log(p(xi))−i=1∑np(xi)log(q(xi))H(p,q)=i∑p(xi)logq(xi)1=−i∑p(xi)logq(xi)
整理得到三者关系
DKL(p,q)=H(p,q)−H(p)
p(x)是真实分布,因此H(p)就是一个常量,所以最小化相对熵DKL(p,q)等价于最小化交叉熵H(p,q)
最大似然与交叉熵
在介绍完交叉熵之后,我们从最大似然的角度来看待交叉熵,首先是最大似然的基本概念
定义:设有一组训练样本X=x1,x2,...,xm,设该样本的分布为p(x)。假设模型的初始化参数为θ,由此得到模型的概率分布q(x;θ),得到似然函数
L(θ)=q(X;θ)=i∏mq(xi,θ)
最大似然就是寻找一个参数θ使得L(θ)最大,即
θML=argθmaxi∏mq(xi,θ)
对上式两边同时取log,等价优化log的最大似然估计,即log-likelyhood,最大似然估计,同时对左右两边进行缩放并不会影响最终解
θML=argθmaxi∑mlogq(xi,θ)→argθmaxm1i∑mlogq(xi,θ)
注意上式的m1∑imlogq(xi,θ),我们在求解参数θ时需要通过已知分布p(x)来求解,p(x)就是我们已知样本的概率分布。但是上式的θ没有p(x)参与,因此我们需要想办法将p(x)加入上式,注意到m1∑imlogq(xi,θ)其实就是随机变量X的概率函数log(X;θ)的均值,根据大数定理,随着样本容量的增加,样本的算术平均值将趋近于随机变量的期望,即
m1i∑mlogq(xi,θ)=Ex∼Q(logq(xi,θ))→Ex∼P(logq(xi,θ))
其中Ex∼P表示符合样本分布P的数学期望,这样就将最大似然估计使用真实样本的期望来表示,即
θML=argθmaxEx∼Plog(q(xi,θ))=argθminEx∼Plog(−q(xi,θ))
到此为止我们就将最大似然估计转换为最小化−Ex∼Plog(q(xi,θ))问题
与交叉熵关系
交叉熵公式如下
H(p,q)=i∑p(xi)logq(xi)1=i∑p(xi)log(−q(xi))=Ex∼Plog(−q(xi))
可以发现最小化交叉熵就是极大似然,从而预测的分布q(x)和样本的真实分布p(x)接近
最小化交叉熵和最大似然等价


