

这是我对部署在Kubernetes集群上的应用程序的故障排除指南。它是基于我在2017年初从Docker切换到该技术后的经验。
有许多第三方工具和技术可用,但我想把重点放在你已经拥有的东西上,或者你可以快速下载MacOS、Windows或Linux的CLI。
如果你是Kubernetes专家怎么办?
如果你已经在为客户支持集群,或者在开发软件,你可能知道其中的一些内容。所以,也许你会发现这些内容对你自己的客户和同事很有用。
在任何情况下,请与我保持联系,看看是否有新的旗帜或技术可以让你捡到。你也可能喜欢我包括的一些更高级的补充材料。
有什么意见、问题或建议?在Twitter上发表评论
它在那里吗?
当你的应用程序不工作时,你可能想检查它的所有资源是否已经被创建。
你学会的第一个命令可能是 "kubectl get pods"
但请记住,Kubernetes支持各种命名空间来隔离和组织工作负载。
所以你可能需要改变这个命令中的命名空间,例如查询 "kube-system "或 "openfaas-fn"。
kubectl get pods --namespace kube-system
kubectl get pods -n openfaas
你可以通过以下方式查询所有可用的命名空间。
kubectl get pods --all-namespaces
kubectl get pods -A
-A 标志是在2-3年内添加到kubectl的,这意味着你可以节省打字的时间。
当然,现在Pod只是我们关心的事情之一。上述命令也可以接受其他对象,如Service,Deployment,Ingress 等。
为什么不工作了?
当你运行 "kubectl get "时,你可能看到你的资源显示为0/1 ,甚至显示为1/1 ,但处于崩溃或Errored状态。
我们怎样才能找出问题所在呢?
你可能会想去找 "kubectl logs",但这只显示已经启动的应用程序的日志,如果你的pod没有启动,那么你需要找出阻止它的原因。
你可能遇到了下列情况之一:
- 镜像不能被提取
- 缺少卷或秘密
- 集群中没有工作负载的空间
- 污点或亲和力规则阻止了pod被调度
现在,kubectl get events ,它本身并不是很有用,因为所有的行都是以看似随机的顺序出现的。修复方法是你必须在某个突出的地方进行纹身,因为现在还没有速记的方法。
kubectl get events \
--sort-by=.metadata.creationTimestamp
这将打印出默认命名空间中的事件,但你很可能是在一个特定的命名空间中工作,所以要确保包括--namespace 或--all-namespaces 标志。
kubectl get events \
--sort-by=.metadata.creationTimestamp \
-A
事件不仅对找出某些东西不工作的原因很有用,它们还能向你展示pod是如何在集群上被拉动、安排和启动的。
例如,在命令中加入"--watch "或"-w "来观察OpenFaaS功能的创建。
kubectl get events \
--sort-by=.metadata.creationTimestamp \
-n openfaas-fn
kubectl get events \
--sort-by=.metadata.creationTimestamp \
-n openfaas-fn \
--watch
LAST SEEN TYPE REASON OBJECT MESSAGE
0s Normal Synced function/figlet Function synced successfully
0s Normal ScalingReplicaSet deployment/figlet Scaled up replica set figlet-5485896b55 to 1
1s Normal SuccessfulCreate replicaset/figlet-5485896b55 Created pod: figlet-5485896b55-j9mbd
0s Normal Scheduled pod/figlet-5485896b55-j9mbd Successfully assigned openfaas-fn/figlet-5485896b55-j9mbd to k3s-pi
0s Normal Pulling pod/figlet-5485896b55-j9mbd Pulling image "ghcr.io/openfaas/figlet:latest"
0s Normal Pulled pod/figlet-5485896b55-j9mbd Successfully pulled image "ghcr.io/openfaas/figlet:latest" in 632.059147ms
0s Normal Created pod/figlet-5485896b55-j9mbd Created container figlet
0s Normal Started pod/figlet-5485896b55-j9mbd Started container figlet
实际上,在上述事件中,有很多事情正在发生。然后,你可以运行像kubectl scale -n openfaas-fn deploy/figlet --replicas=0 这样的东西来缩小它的规模,并观察更多的事件在pod被移除时产生。
现在,有一个新的命令叫kubectl events ,你可能也想看看,但是我的kubectl版本太旧了,而且它目前只是一个alpha功能。
无论你是在Windows、MacOS还是Linux上,你都可以使用arkade升级kubectl。
arkade get kubectl@v1.24.0
/home/alex/.arkade/bin/kubectl alpha events -n openfaas-fn
现在按照我的理解,这个新命令确实是在对事件进行排序,以关注它的进展情况,看看Kubernetes社区是否将其推广到普遍可用(GA)状态。
它启动了,但没有工作
因此,应用程序启动时只有1/1的pod,或者启动后一直崩溃,所以当你输入时,你会看到很多重启的情况。
kubectl get pod
NAME READY STATUS RESTARTS AGE
ingress-nginx-controller-54d8b558d4-59lj2 1/1 Running 5 114d
这可能是古老的最受欢迎的 "kubectl logs "的地方。
大多数人并不直接使用Pod,而是创建一个部署,而部署又会根据复制领域创建一些Pod。我安装ingress-nginx的方式就是如此,你可以看到它已经重启了5次。它现在已经运行了114天,即近4个月。
kubectl logs ingress-nginx-controller-54d8b558d4-59lj2|wc -l
哇。我刚刚看到328行过去了,那是太多的信息。
让我们过滤一下,只看过去的10行,谁还需要输入pod的名字呢?这在Kubernetes中已经没有必要了。
找到部署名称并使用它来代替。
kubectl get deploy
NAME READY UP-TO-DATE AVAILABLE AGE
ingress-nginx-controller 1/1 1 1 114d
kubectl logs deploy/ingress-nginx-controller \
--tail 10
这就好了,只显示过去10行。但如果我想在应用程序运行时监控日志怎么办?
好吧,kubectl logs 没有一个--watch 标志,但它有一个--follow (-f) 标志,我们可以用它代替。
kubectl logs deploy/ingress-nginx-controller \
--tail 10 \
--follow
Pod可以有一个以上的容器,当他们这样做时,意味着更多的打字,因为我们必须在其中挑选一个。
你注意到我在这里添加了一个额外的标志吗?--container
kubectl logs -n openfaas deploy/gateway
error: a container name must be specified for pod gateway-7c96d7cbc4-d47wh, choose one of: [gateway operator]
我们还可以过滤到特定时间段内发出的日志。
kubectl logs -n openfaas deploy/gateway \
--container gateway \
--since 30s
你也可以通过使用--since-time 标志来输入RFC3339格式的特定日期。
有太多的豆荚了!
当你的部署有一个以上的副本时,那么kubectl logs 命令将只选择其中一个,而你将错过潜在的重要信息。
kubectl logs -n openfaas deploy/queue-worker
Found 2 pods, using pod/queue-worker-755598f7fb-h2cfx
2022/05/23 15:24:32 Loading basic authentication credentials
2022/05/23 15:24:32 Starting Pro queue-worker. Version: 0.1.5 Git Commit: 8dd99d2dc1749cfcf1e828b13fe5fda9c1c921b6 Ack wait: 60s Max inflight: 25
2022/05/23 15:24:32 Initial retry delay: 100ms Max retry delay: 10s Max retries: 100
我们可以看到,有两个pod。
kubectl get pods -n openfaas|grep queue
queue-worker-755598f7fb-h2cfx 1/1 Running 1 28d
queue-worker-755598f7fb-ggkn9 1/1 Running 0 161m
所以kubectl只把我们连接到最老的pod,而不是2个多小时前创建的新pod。
这里的解决方法是,要么使用标签选择器,在两个pod之间匹配共同的标签,要么使用第三方工具。
kubectl logs -n openfaas --l app=queue-worker
使用标签选择器意味着我们不会得到新的豆荚,因为我们统计了这个命令,所以第三方工具对于任何可以自动扩展或崩溃和重启的东西来说会更好。
最近,我本来想推荐kail,但在与一个OpenFaaS客户合作时,我们发现维护者并不满足于Window用户。
取而代之的是,我们改用了一个非常类似的工具,叫做stern。
你可以用arkade把这个工具安装到Windows、MacOS和Linux上。
arkade get stern
但你能curl 吗?
虽然Kubernetes可以运行批处理作业和后台任务,但大多数时候,你会看到团队部署网站、微服务、API和其他具有HTTP或TCP端点的应用程序。
所以要问的一个好问题是 "我可以卷曲它吗?"
访问服务需要有自己的文章,所以我在几周前写了这篇文章。初级:访问Kubernetes中的服务
为什么我们的内存已经用完了?
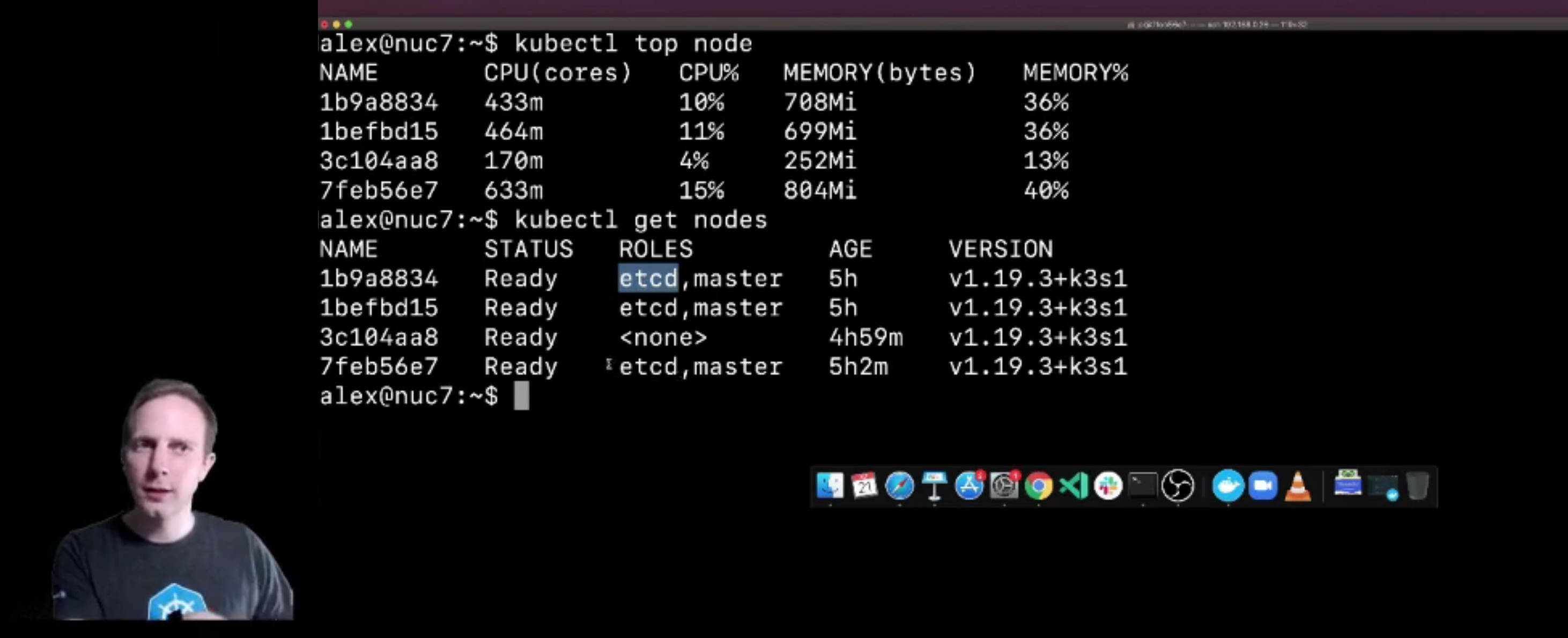
metrics-server项目是Kubernetes的一个插件,可以快速显示整个集群的Pod使用了多少内存和CPU。它还会告诉你各节点的工作负载有多平衡。
下面是OpenFaaS在2个节点的Raspberry Pi集群上的完整安装。它还包括一堆额外的东西,如OpenFaaS Pro、Grafana、用于连接的inlets隧道、新的UI仪表板和度量服务器本身。我也在运行一些服务的多个副本,比如有两个独立pod的queue-worker。
kubectl top pod -A
NAMESPACE NAME CPU(cores) MEMORY(bytes)
default ingress-nginx-controller-54d8b558d4-59lj2 4m 96Mi
grafana grafana-5bcd5dbf74-rcx2d 1m 22Mi
kube-system coredns-6c46d74d64-d8k2z 5m 10Mi
kube-system local-path-provisioner-84bb864455-wn6v5 1m 6Mi
kube-system metrics-server-ff9dbcb6c-8jqp6 36m 13Mi
openfaas alertmanager-5df966b478-rvjxc 2m 6Mi
openfaas autoscaler-6548c6b58-9qtbw 2m 4Mi
openfaas basic-auth-plugin-78bb844486-gjwl6 4m 3Mi
openfaas dashboard-56789dd8d-dlp67 0m 3Mi
openfaas gateway-7c96d7cbc4-d47wh 12m 24Mi
openfaas inlets-portal-client-5d64668c8d-8f85d 1m 5Mi
openfaas nats-675f8bcb59-cndw8 2m 12Mi
openfaas pro-builder-6ff7bd4985-fxswm 1m 117Mi
openfaas prometheus-56b84ccf6c-x4vr2 10m 28Mi
openfaas queue-worker-6d4756d8d9-km8g2 1m 2Mi
openfaas queue-worker-6d4756d8d9-xgl8w 1m 2Mi
openfaas-fn bcrypt-7d69d458b7-7zr94 12m 16Mi
openfaas-fn chaos-fn-c7b647c99-f9wz7 2m 5Mi
openfaas-fn cows-594d9df8bc-zl5rr 2m 12Mi
openfaas-fn shasum-5c6cc9c56c-x5v2c 1m 3Mi
现在我们可以看到pod在机器上的平衡情况。
kubectl top node
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
k3s-agent-1 236m 5% 908Mi 23%
k3s-pi 528m 13% 1120Mi 14%
所以我们实际上有足够的空间来部署更多的工作负载。
现在你不能给这个命令添加任何类型的"--观察 "或"--跟随 "标志,所以如果你想在扩展一些功能或部署一堆新的pod时观察它,你需要使用一个像 "观察 "这样的bash工具。
试试这个例子。
# Terminal 1
watch "kubectl top pod -A"
# Terminal 2
watch "kubectl top node"
metrics-server是一个可选的附加组件,你可以用arkade或helm来安装它。
arkade install metrics-server
你有没有把它关了又开?
这是个悲剧,但却是事实,把东西关掉再打开可以解决我们每天遇到的许多错误。
重启Kubernetes中的部署可能会修复由于迫使你的代码重新连接到服务,拉下一个更新的镜像,或者只是释放内存和数据库连接而产生的问题。
你要找的命令是kubectl rollout restart 。
让我们重新启动2个OpenFaaS队列工作器,同时用stern观察日志,并在另一个窗口观察命名空间的事件。
# Terminal 1
kubectl get events \
-n openfaas
--sort-by=.metadata.creationTimestamp \
--watch
# Terminal 2
stern -n openfaas queue-worker.* --since 5s
# Terminal 3
kubectl rollout restart \
-n openfaas deploy/queue-worker
因此,我们看到我们的两个新豆荚出现在stern中,这是kubectl logs 无法为我们做到的。
queue-worker-6d4756d8d9-km8g2 queue-worker 2022/06/01 10:47:27 Connect: nats://nats.openfaas.svc.cluster.local:4222
queue-worker-6d4756d8d9-xgl8w queue-worker 2022/06/01 10:47:30 Connect: nats://nats.openfaas.svc.cluster.local:4222
而队列工作者的事件显示新的pod被创建,旧的pod被从集群中移除。
LAST SEEN TYPE REASON OBJECT MESSAGE
69s Normal Pulling pod/queue-worker-6d4756d8d9-xgl8w Pulling image "ghcr.io/openfaasltd/queue-worker:0.1.5"
68s Normal Pulled pod/queue-worker-6d4756d8d9-xgl8w Successfully pulled image "ghcr.io/openfaasltd/queue-worker:0.1.5" in 597.180284ms
68s Normal Created pod/queue-worker-6d4756d8d9-xgl8w Created container queue-worker
68s Normal Started pod/queue-worker-6d4756d8d9-xgl8w Started container queue-worker
67s Normal ScalingReplicaSet deployment/queue-worker Scaled down replica set queue-worker-755598f7fb to 0
67s Normal SuccessfulDelete replicaset/queue-worker-755598f7fb Deleted pod: queue-worker-755598f7fb-h2cfx
67s Normal Killing pod/queue-worker-755598f7fb-h2cfx Stopping container queue-worker
我们没有谈到的是
我需要对应用程序进行检查,原因有二。第一个原因是,我实际上是为Kubernetes写软件,如openfaas和inlets-operator--在开发过程中,我需要上面的大部分命令来检查何时出错。第二个原因是,我的公司支持用户。支持用户可能是一个挑战,尤其是当他们不习惯在Kubernetes上排除应用程序的故障时。
在一个分布式系统中,有很多东西需要检查,所以对于OpenFaaS的用户来说,我们把它们都写在了故障排除指南中,你会看到我们今天谈到的一些内容都在那里。
根据我的经验,应用层面的指标对于评估一个服务的性能如何至关重要。只需很少的工作,你就可以为你的服务记录速率、错误和持续时间,这样,当错误比较隐蔽时,你就可以开始了解可能发生的情况。
指标超出了本文的范围,但是如果你想获得一些经验,在我的电子书Everyday Go中,我向你展示了如何向Go HTTP服务器添加指标,并开始用Prometheus监控它。
