

写在前面:
不知道网上这个解决方案是谁抄的谁的,千篇一律的答案,而且答案让人看得找不到北。网上的答案见下面.
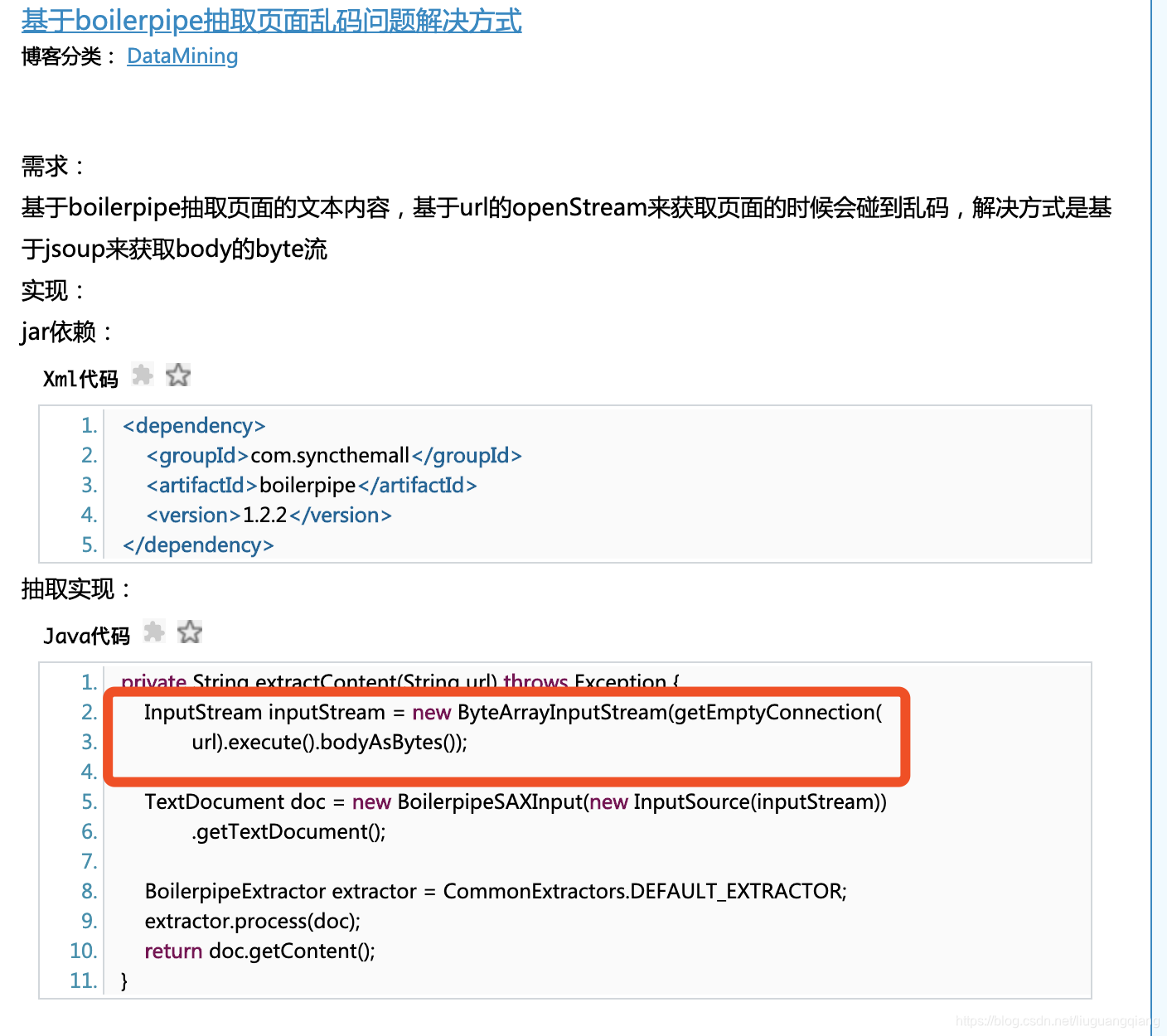 谁能告诉我,getEmptyConnection 是什么鬼。
谁能告诉我,getEmptyConnection 是什么鬼。
下面给出正确的方案:
URL url = new URL(getUrl());
URLConnection connection = url.openConnection();
connection.setRequestProperty("Cookie", cookies);
connection.connect();
InputSource inputSource = new InputSource(connection.getInputStream());
inputSource.setEncoding("UTF-8"); // 在这里设置你的文本的正确格式
doc = new BoilerpipeSAXInput(inputSource).getTextDocument();
BoilerpipeExtractor extractor = CommonExtractors.CANOLA_EXTRACTOR;
extractor.process(doc);
System.out.println("title:" + doc.getTitle());
System.out.println("content:" + doc.getContent());
通过指定 InputSource 的 编码格式就可以解决BoilerpipeExtractor process后的doc乱码问题
