携手创作,共同成长!这是我参与「掘金日新计划 · 8 月更文挑战」的第14天,点击查看活动详情
⭐️前面的话⭐️
✉️坚持和努力一定能换来诗与远方!
💭推荐书籍:📚《王道408》,📚《深入理解 Java 虚拟机-周志明》,📚《Java 核心技术卷》
💬算法刷题:✅力扣🌐牛客网
🎈Github
🎈码云Gitee
大数据概论
概念
大数据(Big Data):指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。
大数据主要解决,海量数据的采集、存储和分析计算问题。
特点 4V
-
大量 Volume
- 截至目前,人类生产的所有印刷材料的数据量是200PB,而历史上全人类总共说过的话的数据量大约是5EB。当前,典型个人计算机硬盘的容量为TB量级,而一些大企业的数据量已经接近EB量级。
-
高速 Velocity
- 大数据区分于传统数据挖掘的最显著特征。海量数据面前,处理数据的效率就是企业的生命。
-
多样 Variety
- 分为结构化数据和非结构化数据。
- 非结构化数据越来越多,包括日志、音频、视频、图片、地理位置信息等,多类型的数据对数据的处理能力提出了更高要求。
-
低价值密度 Value
- 价值密度的高低与数据总量的大小成反比。
- 如何快速对有价值数据”提纯“成为目前大数据背景下待解决的难题。
应用场景
- 抖音:推荐你喜欢的视频
- 电商:广告推荐,给用户推荐可能喜欢的产品
- 零售:分析用户消费习惯,为用户购买商品提供方便,从而提升商品销量。经典案例,纸尿布 + 啤酒。
- 物流仓储:京东物流
- 保险:海量数据挖掘及风险预测,精准营销,提升精细化定价能力。
- 金融:帮助金融机构推荐优质客户
- 房产:精准推测与营销
- 人工智能 + 5G + 物联网 + 虚拟与现实
发展前景
大数据部门间业务流程分析
大数据部门内组织架构
Hadoop入门
-
课程升级内容
- yarn
- 生产调优手册
- 源码
-
课程特色
- 新 hadoop 3.1.3
- 细 从搭建集群开始 每一个配置 每一行代码都有注释
- 真 20+企业案例 30+企业调优 从百万代码中阅读源码
- 全 全套资料
-
技术基础要求
- JavaSE
- maven
- Idea
- Linux常用命令
1 概述
1.1 是什么
- 分布式系统基础结构
- 主要解决,海量数据的存储和海量数据的分析计算问题
- 广义上讲,指一个更广泛的概念——Hadoop生态圈
1.2 发展历史(了解)
-
可以说Google是Hadoop的思想之源(Google在大数据方面的三篇论文)
- GFS--->HDFS
- Map-Reduce --->MR
- BigTable--->HBase
1.3 发行版本(了解)
- Apache
- Cloudera
- Hortonworks
1.4 优势(4高)
- 高可靠性:底层维护多个数据副本
- 高扩展性:在集群间分配任务数据,可方便地扩展数以千计的结点
- 高效性:并行工作的,以加快任务处理速度
- 高容错性:能够自动将失败的任务重试
1.5 组成(面试重点)
1.x、2.x、3.x区别
HDFS 架构概述(分布式文件系统)(存储)
- Hadoop Distributed File System
- 解决存储问题
YARN(资源管理器)
- Yet Another Resource Negotiator
- Hadoop的资源管理器,主要管理CPU和内存
MapReduce 架构概述(计算)
MapReduce将计算过程分为两个阶段:Map 和 Reduce
- 1)Map 阶段并行处理输入数据
- 2)Reduce 阶段对Map 结果进行汇总
三者关系
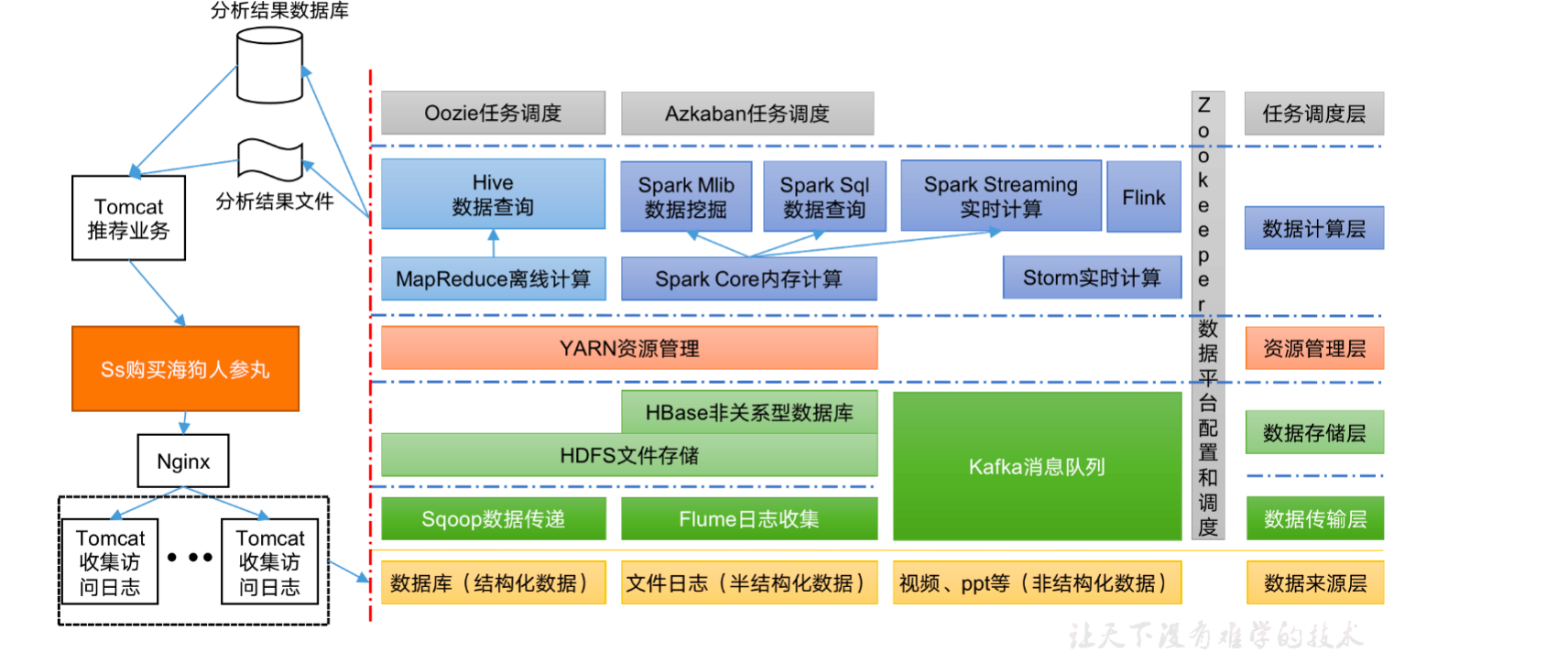
1.6 大数据技术生态体系
图中涉及的技术名词解释如下:🎈
1)Sqoop:Sqoo是一款开源的工具,主要用于在Hadoop、Hive 与传统的数据库 (MySQL) 间进行数据的传递,可以将一个关系型数据库(例如 : MySQL, Oracle 等)中的数据导进到 Hadoop 的 HDFS中,也可以将HDFS的数据导进到关系型数据库中。
2)Flume.:Flllm 是一个高可用的、高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume 支持在日志系统中定制各类数据发送方,用于收集数据;
3)Kafka:Kafka是一种高吞吐量的分布式发布订阅消息系统;
4)Spark:Spark 是当前最流行的开源大数据内存计算框架。可以基于Hadoop上存储的大数据进行计算。
5)Flink:是当前最流行的开源大数据内存计算框架。用于实时计算的场景比较多。
6)Oozie:Oozie是一个管理 Hadoop 作业 (job) 的工作流程调度管理系统。
7)Hbase: HBase是一个分布式的、面向列的开源数据库。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。
8)Hive:Hive 是基于 Hadoop 的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的SQL查询功能,可以将SQL语句转换为 MapReduce 任务进行运行。其优点是学习成本低,可以通过类SQL语句快速实现简单的 MapReduce 统计,不必开发专门的 MapReduce 应用,十分适合数据仓库的统计分析。
9)ZooKeeper:它是一个针对大型分布式系统的可靠协调系统,提供的功能包括:配置维护、名字服务、分布式同步、组服务等。
1.7 推荐系统框架图