

html下载下来后,如何去解析提取里面的元素
一.BeautifulSoup
BeautifulSoup只是一个壳,他可以封装了很多解析引擎,使得这些引擎的接口变得简单,实际上的解析是由解析引擎来处理的.
使用的时候查询文档即可,bs官方文档:
https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html
二.xpath(重点)
scrapy的Selector类,是对lxml的封装,使用起来更顺手
可以将Selector理解成一个解析库,用于对数据的提取
xpath是Selector对象的方法,是使用路径表达式在xml和html中进行导航,给出一个路径(path)就可以定位到元素
from scrapy import Selector
sel = Selector(text='要解析的文本')
tag_list = sel.xpath('路径').extract() # extract:提取;提取出来的是列表
if tag_list:
text = tag_list[0] # xpath可以直接获取到文本值
#其他方法陈列:
title_list = sel.xpath('//a[contains(@class,"link-title")]')
sel.xpath('//a[contains(@class,"link-title")]/text()').extract() # 取文本
sel.xpath('//a[contains(@class,"link-title")]/@href').extract() #取属性
xpath可以使得我们的解析变成可以配置的解析
name_xpath = '...' # 数据库中取,只需配置这个就可以
name = ''
tag_list = sel.xpath(name_xpath).extract()
if tag_list:
name = tag_list[0]
xpath提供了很多内置方法,可以在这个网址下面查询
https://developer.mozilla.org/en-US/docs/Web/XPath/Functions
 图中的article指html中的标签
图中的article指html中的标签

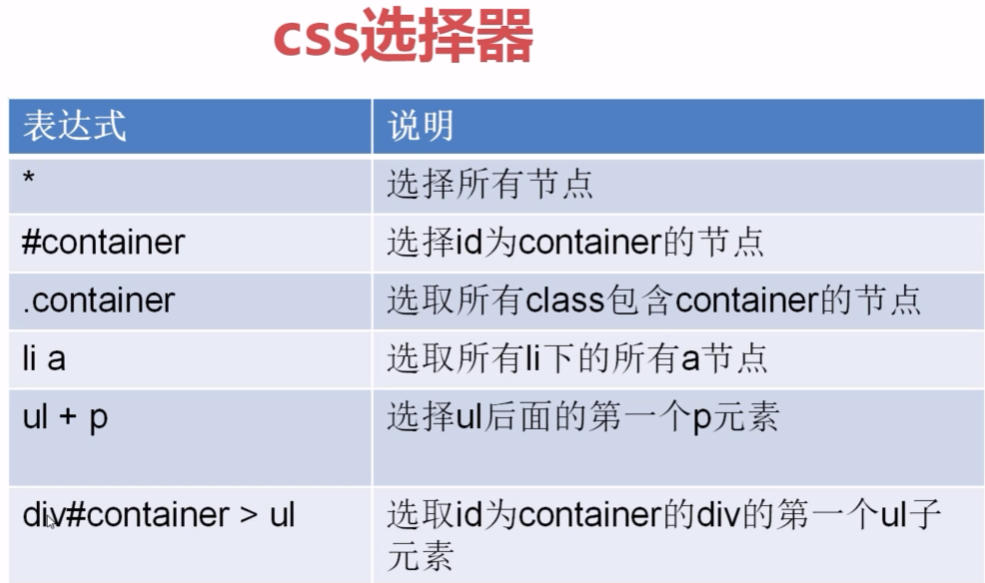
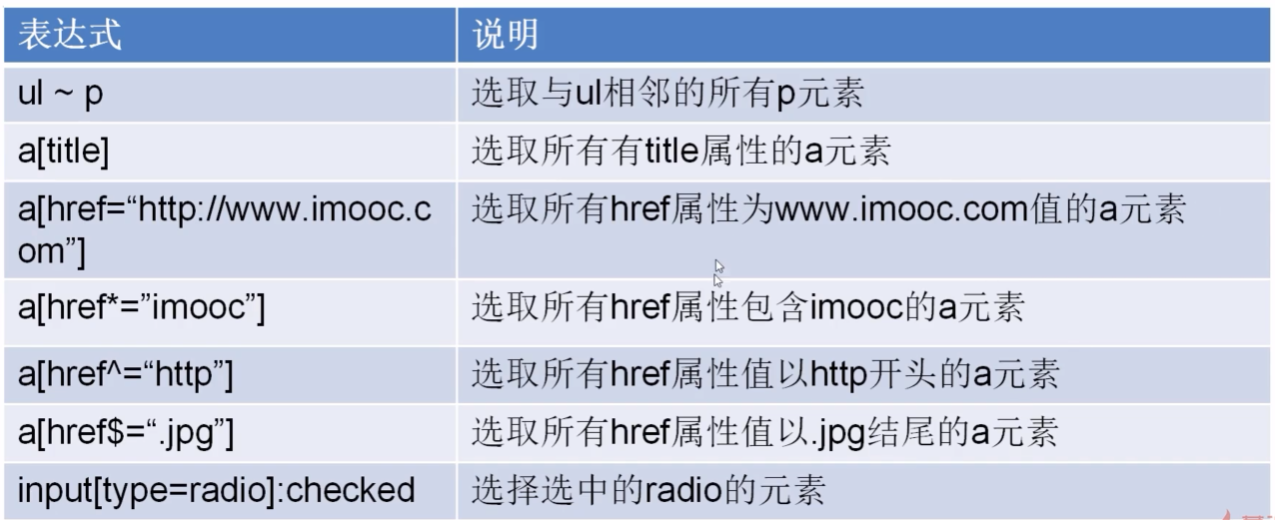
三.css选择器
from scrapy import Selector
sel = Selector(text='要解析的文本')
info_tag = sel.css("#id");
course_url = sel.css("a[href*='imooc']::text").extract() #属性href包含imooc
css选择器也是Selector对象的方法,也可以跟xpath一样,做成可以配置的解析
总结:推荐使用xpath/css,主要看喜好与熟练程度
本文由mdnice多平台发布
