

大数据可视化理论与案例分析| 青训营笔记
这是我参与「第四届青训营 」笔记创作活动的的第20天
定义(Definition)
什么是可视化(What is Visualization)
Visualization is any technique for creating images, diagrams, or animations to communicate a message
根据这个定义,我们可以理解为通过视觉元素(图像,图表,动画等等)来进行信息交流的方式都可以称之为可视化。比如下面的梵高的绘画,奥运会的ICon设计,一个具体的桑吉图都属于可视化。
这里应该还有一个更大的范畴定义,不仅局限于视觉,扩展到人类的整个感知系统。通过听觉、触觉或者味觉也是可以进行信息呈现和交流的。针对盲人,也是可以设计优秀的可视化作品的。
什么是数据可视化(What is Data Visualization)
Anything that converts data into a visual representation (like charts, graphs, maps, sometimes even just tables)
“数据可视化”和“可视化”的定义很相似,只是增加了一个关键词——“数据”。
下面是几个典型的应用场景。
在科学可视化领域,数据可视化的作用主要是形象化的呈现,方便人们理解和查看。比如医学领域的扫描成像,可以大大提高医生探寻病因的效率。下面是一个人体内细胞运动的可视化作品,以壮美的方式呈现了人体内的微观世界(www.youtube.com/watch?v=NTg…
呈现数据关系的信息可视化是我们见到最多的可视化方式,比如下图通过地理信息以及连线展现唐代人物的迁徙轨迹(cbdb-qvis.pkudh.org/part1_migra…
在计算机诞生之前,可视化都是静态作品,人们只能通过看来理解数据。随着计算机图形的发展,交互成为一个重要研究方向,可视化和图形交互的融合,产生了探索式数据分析。比如下面的数据分析工具Tableau的交互界面(www.tableau.com。
数据可视化作用(The role of data visualization)
直观展示
一图胜千言。数据可视化最直观的作用就是将数据要阐述的内容直观的展现出来,比如下面著名的“拿破仑东征图”。
Charles Joseph Minard,Map of Napolean's Russian Campaign of 1812
这个图表使用颜色标注了拿破仑进军莫斯科的路线图及败退路线,简单的可视化利用二维平面展现了包括空间、时间、气温、军队的人数等多个维度的信息,使得观察者可以通过一幅图了解整个历史事件的全貌。
数据探索
(Anscombe's quartet)是四组基本的统计特性一致的数据,但由它们绘制出的图表则截然不同。每一组数据都包括了11个(x,y)点。这四组数据由统计学家弗朗西斯·安斯库姆(Francis Anscombe)于1973年构造,他的目的是用来说明在分析数据前先绘制图表的重要性,以及离群值对统计的影响之大。
促进沟通与交流
由于可视化可以高效的阐释数据内含,合理的可视化设计可以更好的帮助作者表达其观点。比如下方的“南丁格玫瑰图((en.wikipedia.org/wiki/File:N…”,)
- 各色块圆饼区均由圆心往外的面积来表现数字
- 蓝色区域:死于原本可避免的感染的士兵数
- 红色区域:因受伤过重而死亡的士兵数
- 黑色区域:死于其它原因的士兵数
- 1854年10月、1855年4月的红黑区域恰好相等
- 1856年1月与2月的蓝、黑区域恰好相等
- 1854年11月红色区域中的黑线指出该月的黑色区域大小
出于对资料统计的结果会不受人重视的忧虑,弗洛伦斯· 南丁格尔 ****发展出一种色彩缤纷的图表形式,让数据能够更加让人印象深刻。这张图表用以表达军医院季节性的死亡率,从整体上来看: 这张图是用来说明、比较战地医院伤患因各种原因死亡的人数,每块扇形代表着各个月份中的死亡人数,面积越大代表死亡人数越多。这幅图让政府相关官员了解到:改善医院的医疗状况可以显著的降低英军的死亡率。南丁格尔的方法打动了当时的高层,包括军方人士和维多利亚女王本人,于是医事改良的提案才得到支持,甚至挽救了千万人的生命
随着可视化的发展,人们使用更多的应用形式来 传递信息,比如仪表盘,数据大屏等。
原理/Theory
数据可视化基本流程(Process)
一个可视化作品的诞生,要经历一系列流程,我们将其抽象成如下图所示的四个大的步骤。
(vis.stanford.edu/files/2005-…
第一步 : 数据处理( Abstract Data ) 只有满足特定结构的数据才能做对应的可视化展现,而且为了达到好的可视化效果也需要对数据进行清洗、转换等操作。
第二步 : 可视化设计与表达( Visualization Design) 根据数据特征选择合适的展现模式,在此基础上通过合理的使用视觉编码,来定义最终的可视化展现内容。
第三步:可视化渲染( Rendering and Display)
将定义好的图形转换成为图像,展现给观众。
第四步:可视化交互( Interactivity)
单一的可视化结果并不能满足用户的多方面诉求,用户往往借助交互方式,进一步了解细节或者对数据进行筛选、聚合、分面等,对数据进行多方面的探索。
下面我们详细的对第一、第二、第四步骤 进行讲解。
数据(Data)
Data is defined as a collection of meaningful facts which can be stored and processed by computers or humans.
能被存储和处理的信息,都可以被视为数据。我们日常接触到的文本、视频、图像、账单等等都是数据。每一个种类的数据都是一个大的集合,由多条小的数据条目组成,称之为数据集(DataSet)。
数据集分为结构化和非结构化(比如文字、图像),数据可视化只能对结构化数据进行呈现。非结构化数据经过处理之后,可以转换为结构化数据,进一步进行可视化展现。比如文本,我们可以通过自然语言处理、机器学习、文本挖掘等多种手段将其转化为结构化数据。
数据与数据集分类(Data and Dataset)
数据可以被分为以下五种类别:
-
Items:具体的每一条数据
-
Attributes:条目的每个字段的属性
-
Links:数据之间的关系
-
Positions:位置
-
Grids:网格
数据集被分为以下五种类别:
-
Tables:表格数据
-
Networks & Trees:层次结构数据
-
Fields:场数据
-
Geometry:几何数据
-
其他集合类型:Clusters,Sets,Lists
一个数据集可以由一种或者多种数据类型组成,包含关系如下表:
(Tamara Munzner 《Visualization Analysis & Design》)
下面我们对几种数据集做具体的解构分析。
表格(Tables)
表格是使用行、列和单元格的概念来存储数据的结构,每一行是一条数据,每一列都有一个统一的属性定义。以下面学生信息表为例:
该表格有三条数据,每一条数据都有5个属性(Attribute),ID、Name、Age、Shirt Size、Favorite Fruit。
行列交叉的单元格里面就是具体的值(Value)。
多维表格(Multidimensional Table)
多维表格数据和普通表格数据组织形式上最大的不同的点在于key 的数量。通常一个普通表格的key 就是行号,比如3.1.1 的 学生信息表为例,“第2行的年龄7”这样的描述,我们是可以明确的知道描述的对象的名字是Basil,而且Basil 最喜欢的水果是Pear。 但是对于多维表格数据则需要多个key才能确定一个value。
下图所示的一个多维表格数据,我们通过简单的行号或者选取一个键都没办法确定一个明确的数据条目,比如我们想得到一个销售值,那么应该描述成为“ Timeid 为1,pid 11 的销售值为25”,更复杂的数据需要更多的键来组合定位。
将两个维度的数据聚合在一起就是一个 “面” ,第三个维度方向上多个面就形成了一个 “体”, 如上图所示,这就是数据立方体基本概念 。
网络图和树图(Networks or Trees)
网络和树数据,核心概念就是“关系”。必须要显示的定义数据条目之间的关联关系才能绘制出网络图和树图。
上图是比较常见的图数据的配置结构,每一个 node 就是一个 data item,node中的属性就是 attributes。 Edges 中定义的就是节点的关系,对应于 Links 。
场(Fields)
场数据,用于描述磁场、电场、风场等数据,存储结构是网格(grid),每个网格中一般是向量、标量或者张量。
结合上图两侧对照,场数据以网格形式存储,右侧的“gridWidth”和“gridHeight”定义了网格的大小(行列数量),field 下面定义了各单元格的值(value)。下图显示了一个风场的可视化效果。
几何数据(Geometry (Spatial))集
几何数据集是几何图形数据的几何,通常用来描述地理信息。
如地图,由多个几何图形拼装而成,在定义地图的数据中会定义具体的几何图形类型及位置信息。
属性分类(Attribute Types)
数据集中的数据条目都会包含一个或者多个属性(Attribute),属性分为分类(Categorical)和排序(Ordered)属性。排序属性又分为顺序(Ordinal)和定量(Quantitative)两种类别。
结合上图中的学生信息表,我们具体分析一下。第一列的 ID 数值是序号,数字类型,属于Quantitative 字段。第二列 Name 属于 Categorical 字段。第三列 Favorite Fruit 属于 Categorical 字段。第四列 Age ,数字类型 属于 Quantitative 字段。第五列 Gender ,性别属于 Categorical 字段。第六列 Shirt Size ,衣服尺寸虽然不是数字,但是它可以进行大小排序,属于 Ordinal 字段。
上面我们已经了解了数据集类型,数据集类型决定我们选择什么样的可视化形式来展现数据,具体到展现的细节,则是由属性(Attribute)来决定。
编码/Encode
认知(Cognition)
关于进一步的知觉感知的研究总结,我们可以抽象人们识别可视化的三个步骤:
- Perception of raw visual signals,e.g. color, shape, etc. 原始信号感知
- Pattern recognition 模式识别
- Reasoning and Analysis 推理分析
图元/Marks
通道(Channels)
选取了Mark之后,需要进一步描述Mark的具体视觉特性,这些特性称之为视觉通道(Visual Channels)
A visual channel is a way to control the appearance of marks
视觉通道有很多,下图以6种通道和3种Mark相组合,可以很直观的体会二者之间的关系
编码(Encode)
从数据到视觉通道的转换过程,被称之为视觉编码(Visual Encoding)。
不同的数据属性需要用不同的通道来进行编码才能达到更好的效果,上图将通道分成两组,分别对应分类数据和可排序数据。下面我以一个简单柱形图为例,进行拆解:
编码有效性(Effectiveness)
由于人类感知系统的特点,在不同场景下需要设计不同的编码策略,来提升感知速度和准确性。以下几项研究,对当前可视化设计有着深远影响。
预感知图形
经过科学家的实验论证,部分图形可以被人类大脑在非常短的时间内识,比如形状、长短、大小等。
在可视化设计过程中,尽可能的使用具有预感知特性的图形,可以加速感知处理的第一个过程。
更多详细内容可以阅读 www.csc2.ncsu.edu/faculty/hea…
有效性排序
一些研究人员对不同的视觉通道对不同数据进行编码进行单变量效果对比,得出有效性排名,下图是研究之一。
Robert E. Roth《Visual Variables》www.researchgate.net/publication…
You must consider a continuum of potential interactions between channels for each pair,ranging from the orthogonal and independent separable channels to the inextricably combined integral channels.
--Tamara Munzner
但是在实际应用场景中,往往一个可视化作品需要组合多个通道,不同通道组合对读者的影响,实际研究不是很多,下图是其中之一。
格式塔理论
格式塔针对人类对特定视觉模式的识别给了很好的分类,该理论同样适用于数据可视化设计。下面我们举例介绍6种原则。
邻近原则(proximity)
空间中距离相近的元素有被看作一体的趋势。人们会很自然的根据距离来对视觉对象进行分组。上图的分组柱形图,我们会很自然的把临近的柱子分为一组,其次才是观察颜色分组。
相似原则(similarity)
刺激物的形状、大小、颜色、强度等物理属性方面比较相似时,这 些刺激物就容易被组织起来而构成一个整体。如下图中,根据颜色和形状,将数据分为两组。
连通性原则 (Element Connectedness)
如果一些元素与其他元素相连时,我们认为这些元素是统一体。如下面的箱型图,如果没有中间的线上线相连,上下两条线是不会被看做一个整体进行分析的。
连续性原则 (Good continuation)
如果一个图形的某些部分可以被看作是连接在一起的,那么这些部分就相对容易被我们视为一个整体。如下面的折线图的连线,虽然是断开的多段线,但是我们仍然视之为一条折线。
封闭的原则(closure)
有些图形是一个没有闭合的残缺的图形,但主体有一种使其闭合的倾向。如下面的形状词云。
共同命运原则(common fate)
如果一个对象中的一部分都向共同的方向去运动,那这些共同移动的部分就易被感知为一个整体。如下方左图,我们会按照相似原则把每行看作一个分组,但是右侧由于共同的运动方向,我们会把每列看作一个分组。
谎言因子
本小节内容主要参考《The Visual Display of Quantitavive Information》一书,图片也来源于此书。
谎言因子(Lie Factor, LF)的概念由德国慕尼黑工业大学Rüdiger Westermann教授提出,用于衡量可视化中所表达的数据量与数据之间的夸张程度的度量方法。
-
当LF=1时,我们认为图表没有对数据实时进行扭曲,是一个可信的可视化设计
-
在实际当中,应当确保各部分图形元素的 LF 在 [0.95, 1.05] 范围内,否则,所产生的图 表认为已经丧失了基本可信度
我们以下图为例做一个简单分析。
在上图中,1978年的长0.6英寸线条代表18 m/g,而1985年5.3英寸线条代表27.5 m/g,数字差异计算:
(27.5 – 18) / 18 = 0.53
图形差异计算:
(5.3 – 0.6) / 0.6 = 7.83
谎言因子计算:
LF = 7.83 / 0.53 =14.8
从结果看,大大夸大了数据事实。
下图是修正过的可视化设计。
数据-墨水比
可视化的核心是数据与信息,可视化作品的大部分笔墨应该集中在数据与信息的呈现上。为此,Tufte 提出了一个衡量标准 Data-ink ratio: Data-ink ratio 表示图表中不可删除的数据的部分占整个图表的比例,其定义如下: Data-ink ratio = data-ink / total ink used to print the graphic
在数据可视化中,数据的重要性高于一切。因此,在进行可视化设计时,应遵循以下两条原则: 1.在合理范围内,最大化 data-ink ration(Maximize the data-ink ration, within reason) 2.在合理范围内,去除冗余的 data-ink(Erase redundant data-ink ration, within reason)
下面是一张普通的散点图。图表中大部分的 data ink 用于数据的呈现(如点、label、坐标轴),剩余少部分的 non-data-ink 用于 ticks、边框 等,这张图表的 Data-ink-ratio 大概在 80% 左右。
极少图表的 Data-ink ratio 能够达到 1。如下面这张图表,所有的线条都是在展现数据,而且图表的坐标轴设计也十分简洁(如红框所示),也就是说,这张图表没有任何可以去除但不影响数据表达的部分了。
下面两个图表都是错误的设计。左图几乎所有的 data-ink 都用在了与数据表达无关的 网格 上;右图则忽略了数据的展示,它们的 Data-ink ratio 都约为 0。
下图是修正后的正确设计,这个图表的 Data-ink ratio 约为 0.7。
更多内容参考:zhuanlan.zhihu.com/p/524878535…
交互(Interaction)
静态的数据展示并不能满足用户需求,很多时候我们需要提供交互形式,使得用户可以对数据进行多维度的探索。《Visualization Analysis & Design》一书对交互进行了分类,分为以下9种。
- Change 改变
- Juxtapose 并列
- Filter 过滤
- Select 选择
- Partition 拆分
- Aggregate 聚合
- Navigate 导航
- Superimpose 叠加
- Embed 镶嵌
随着场景和技术的发展,更多样的交互形式也在不断的出现,但是目标都是为了进行更好的数据探索分析。下面我们看几个具体的例子。
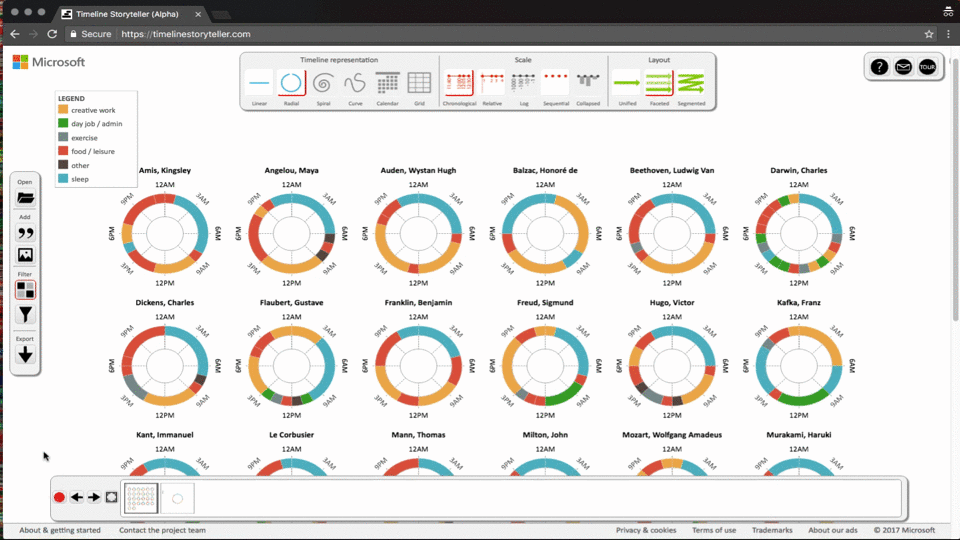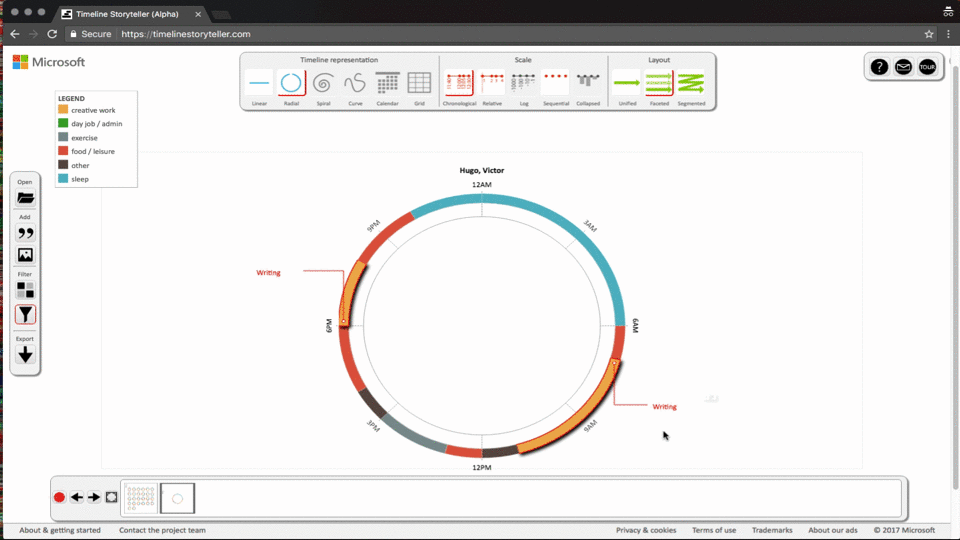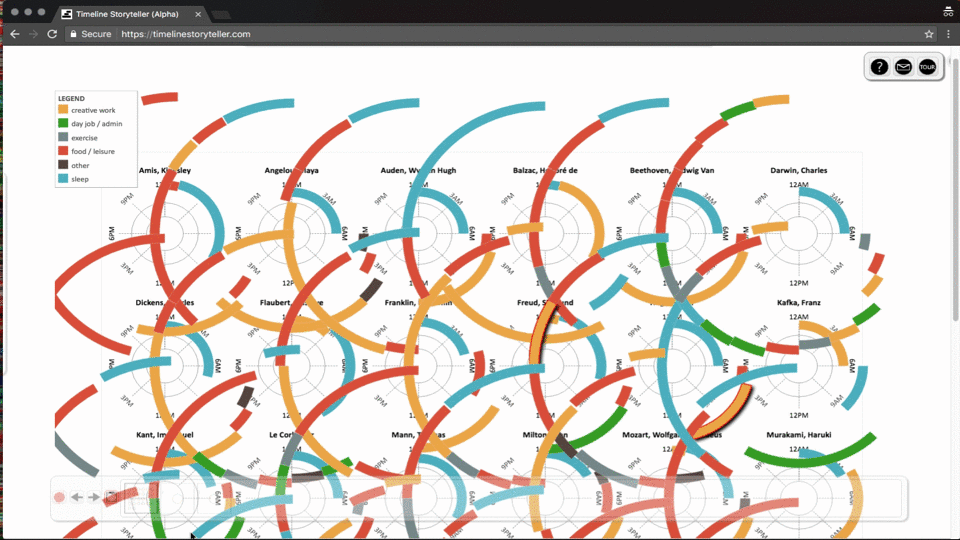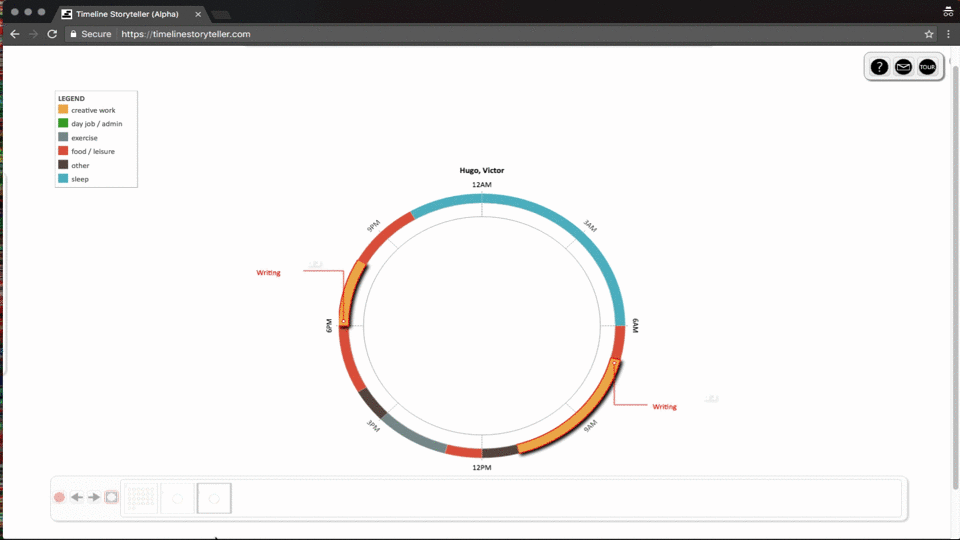
第一个例子应用导航功能来切换数据,结合地理位置的变换来讲述内容。
第二个例子是在图可视化中常见的交互场景,通过缩放对数据进行过滤,点击节点查看有关联的其他节点信息。
第三个例子展示的是数据分面,形式变换的例子。
实例(Cases)
过多的分类会使得饼图的视觉效果趋于混乱。 同样的数据,如果使用柱形图来显示,分类之间的对比就会明显很多
非0基线造成的数据扭曲
使用累积数据而不是年份数据,给观众造成逐年销量攀升的假象;
另外没有明显的比例尺,看不出数据之间的实际差异
工具体验
-
TimeStoryTeller:timelinestoryteller.com/
-
Facets:github.com/PAIR-code/f…
-
Tableau:www.tableau.com/
