

这是我参与「第四届青训营 」笔记创作活动的的第22天
一、本课堂重点内容
机器学习——聚类算法
二、详细知识点介绍:
01.聚类算法
1.1 概览简介
聚类算法是机器学习中涉及对数据进行分组的一种算法。在给定的数据集中,我们可以通过聚类算法将其分成一些不同的组。在理论上,相同的组的数据之间有相似的属性或者是特征,不同组数据之间的属性或者特征相差就会比较大。聚类算法是一种非监督学习算法,并且作为一种常用的数据分析算法在很多领域上得到应用。
- 常用的聚类方法:
-
- K-means(具体计算)
- DBSCAN(基于密度)
- 层次聚类(基于树)
这些常用聚类方法所依赖的常用聚类特征较为偏向统计学类特征。
常用聚类特征:
- 人口属性:性别、年龄、地域等等;
- 常用指标:活跃度、时长、消费次数等等;
- 消费偏好:用户使用不同功能的时长占比、点击占比,每天进入该app的启动方式等等。
聚类所使用的统计特征无法反应用户的行为细节。因此,我们也就需要比统计特征更具有区分客户特性的特征。
常用聚类方法各自的优点和缺点:
| 聚类算法 | 优点 | 缺点 |
|---|---|---|
| 基于距离——K-means | 实现简单快速、聚出的类别相对均匀 | 受初始点选择影响较大、无法自定义距离、无法识别离群点、需要事先确定簇的数量 |
| 基于密度——DBSCAN | 可以识别离群点、对特殊分布效果好 | 聚出的类别欠均匀、受密度定义影响较大、不擅长处理密度不均的数据 |
| 层次聚类 | 对特殊分布效果好、类的层次关系具有一定价值 | 有时聚出的类别欠均匀、内存不友好 |
1.2 应用场景
- 指标波动场景。举例:某个重要的KPI发生变化时,我们会思考是不是某个特定人群导致了这个波动,然后针对这样的波动找到应对的办法;
- 精细化运营。举例:在做某个业务的增长,我们会思考哪些是潜力用户,在定位到潜力用户后进一步思考如何更好地承接他们;
- PMF(Product-Market Fit)。即研究给什么样的细分人群提供什么样的内容才能达到最好的匹配效果。
1.3 K-Means
概览
K-means 聚类算法可能是大家最为熟悉的聚类算法。它在许多的工业级数据科学和机器学习课程中都有被讲解。并且容易理解和实现相应功能的代码 。
k-means聚类
- 首先,我们确定要聚类的数量,并随机初始化它们各自的中心点。为了确定要聚类的数量,最好快速查看数据并尝试识别任何不同的分组。中心点是与每个数据点向量长度相同的向量,是上图中的“x”。
- 通过计算当前点与每个组中心之间的距离,对每个数据点进行分类,然后归到与距离最近的中心的组中。
- 基于迭代后的结果,计算每一类内,所有点的平均值,作为新簇中心。
- 迭代重复这些步骤,或者直到组中心在迭代之间变化不大。您还可以选择随机初始化组中心几次,然后选择看起来提供最佳结果。
k-means的优点是速度非常快,因为我们真正要做的就是计算点和组中心之间的距离;计算量少!因此,它具有线性复杂性o(n)。
另一方面,k-means有两个缺点。首先,您必须先确定聚类的簇数量。理想情况下,对于一个聚类算法,我们希望它能帮我们解决这些问题,因为它的目的是从数据中获得一些洞察力。k-means也从随机选择聚类中心开始,因此它可能在算法的不同运行中产生不同的聚类结果。因此,结果可能不可重复,缺乏一致性。
K值选择
关于聚类的簇数量最优选择,可参考此文章**www.biaodianfu.com/k-means-cho…** ,常用肘部法和轮廓系数法。
模型评估
模型评估方法可参考此文章 juejin.cn/post/699791…
02.聚类画像分析工具
2.1 概览简介
一个基于聚类的用户画像分析工具,以对用户群体进行标注及定位,(1)帮助运营分析师PM等洞察群体用户在站内的消费、投稿内容生态情况;(2)研究用户与内容的关系和演变,理解业务增长的变化,制定用户与内容的增长策略,以使得用户分析更简便、更灵活、更快获取数据背后所隐藏的价值。
2.2 流程
2.3 分析过程
| # | 环节 | 目的 | 详情 | 示意截图 |
|---|---|---|---|---|
| 1 | 样本选定 | 确定聚类分析的样本范围 | 一共提供三种方式圈选人群1. 定义条件筛选样本,条件都是比较通用的,比如年龄、性别、vv_finish_1w(过去一周用户的完播次数,用来保证用户兴趣的显著性),缺点是条件比较少。2. 上传圈选ID列表,主要服务于用户所需的条件并不在第一种方式里,可以直接离线圈选好用户,然后通过上传csv文件即可。这种方式更多的是用于一次性实验分析,**如果设置成周期调度,但由于已是上传固定的用户,没法根据你离线选好条件随时间动态变化用户,所以就成了固定用户的周期任务。**3. 输入hive表名称,也是服务于用户所需的条件并不在第一种方式里,但是你需要有hive表的写权限,调度频次可设置成一次性实验分析,也可周期调度。如果需要周期调度,请将hive表对应的任务设置成天级调度(由表里的数据来决定哪些用户需要参与聚类) 。平台会在周期调度时间到来时读取表里的数据,完成任务的执行。相比第二种,用户可随时间动态变化,但需要hive表写权限。 | |
| 2 | 向量获取 | 获取选定样本中用户在短视频内的行为向量(64维) | 行为向量是一种描述用户在短视频内行为的特征向量。可以粗略理解为,倾向于消费/点赞/收藏/分享同一类视频或倾向于与同一类创作者互动的用户,将会拥有相似的特征向量。**选择Embedding作为模型特征的依据:**1. 用户行为的语义特征2. 线下分析反映线上效果 | |
| 3 | 算法聚类 | 基于64维用户推荐向量,通过k-means算法,将相似的用户分成一组,不相似用户分成不同组。 | **选择k-means算法的依据:**1. 用户64维推荐向量在空间中的分布是球状分布且凸集的数据,k-means所求的目标函数是所有点到距离其最近的中心点的距离平方和最小,这样我们就要求解一个凸优化问题。 |
1. 需要对满足不同条件的人群进行聚类,所以人群数据量存在着量级差异,量级可达千万级甚至亿级,而且每一个用户的向量是64维。
1. 系统上每天有很多聚类任务需要执行
1. 综上,所以算法复杂度不能过高,不然算法需要花很多时间去训练,且机器资源紧张,进而影响整体任务的执行效率。3. 可理解性和算法稳定性
1. **可理解性:** 设定人群的业务方有过对人群进行探查,从而有一定的认知,了解用户群体大概可分为哪些群体,所以可直接指定群体的数量,并不太强需要由算法的其他参数形式去发现群体应该分为多少个。**当然系统也提供了自动发现人群数的功能,方便对未知群体通过算法来发现最优的分群数量。**
1. **算法稳定性:** 当前任务中cluster_id所表示的含义,在下一个调度周期时,需要使得对应的cluster_id保持同一个含义,即**基于上一周期的聚类结果初始化本周期的聚类任务的cluster中心点**,这样能保证算法中cluster含义的稳定性,从而帮助业务方快速review cluster的内容,以确认内容与之前对比是否发生变化。综上三个要素的考量,选择K-Means算法,该算法简单易懂,适合大数据量且复杂度低。同时能设定所需要分群的数量,以及群体中心点的初始化数据。当然在初次对用户群体进行聚类的时候,选用了K-Means++算法的思想,这样能尽可能消除随机选择初始点带来的结果差异的问题。同时选用MiniBatchKMeans <https://scikit-learn.org/stable/modules/clustering.html#mini-batch-k-means>的思想,以小批量的随机数据进行训练,减少运算时间,且效果并没有变差很多,反而增加了泛化能力。**算法工具包:**- **Python** **Sklearn:** 利用python的sklearn机器学习package里的clustering算法,选择KMeans或者MiniBatchKMeans,来进行聚类。单机本地执行机制,执行速率快,准确度不受影响,但是受本地内存资源的限制,如果本地内存资源足够大,完全可以run。- **Spark** **Scala Mllib:** 利用Spark scala的Mllib机器学习package里的clustering算法,选择KMeans,来进行聚类。Spark yarn 分布式执行机制,执行速率不稳定,时快时慢,受yarn 队列资源此刻资源的限制,如果yarn队列资源充足,执行效率会大大加快,且相对稳定。 | 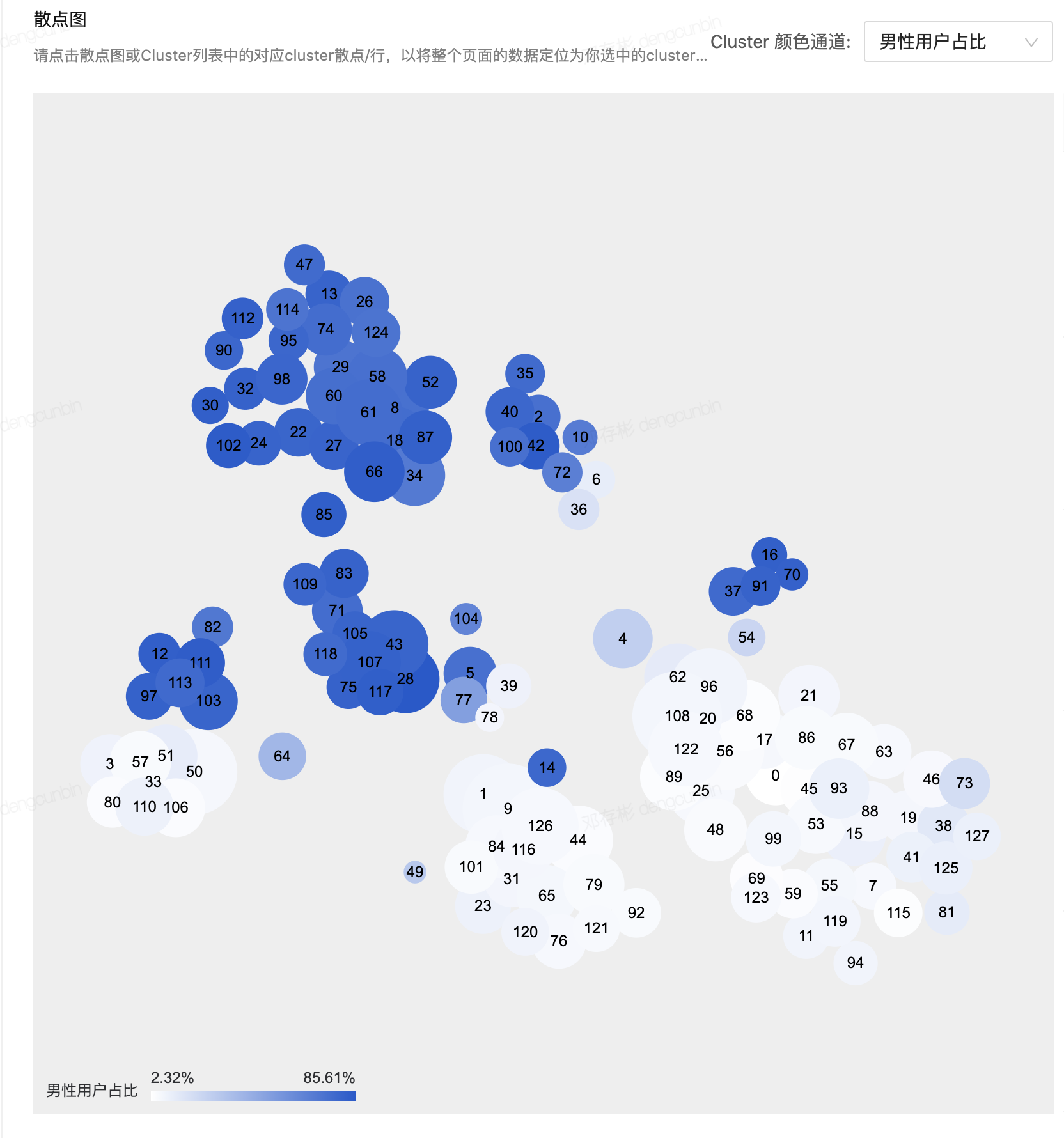 |
复制代码
| 4 | Cluster Level 可视化分析 | 通过为用户提供各种各样的可视化数据,辅助用户得出以下结论:- cluster的定性分析
- cluster代表什么类型的用户- cluster的定量分析
- cluster的核心指标,对比分析及变动趋势- cluster的指标趋势变化分析
- cluster任务周期运行,可发现指标随时间的变化趋势。- cluster之间指标相对关系,发现North Star cluster
- cluster指标在二维坐标系里的相对关系,发现北极星cluster
- > 北极星指标(North Star Metric),也叫作第一关键指标(One Metric That Matters),是指在产品的当前阶段与业务/战略相关的绝对核心指标。它一旦确立就像北极星一样,指引团队向同一个方向迈进(去提升这一指标)。在数据监测中,北极星指标指决定性意义的数据监测指标。 | - 右侧为通过[t-SNE](https://distill.pub/2016/misread-tsne/)算法将64维的cluster中心向量降维到2维的示意图,可以粗略理解为:
- 拥有相似行为的用户被聚类进了各自的cluster中
- cluster间的相似程度与分布存在相关关系。cluster与cluster之间在空间距离越接近,那么它们的画像越相似- cluster的定性指标
- Top Unique Videos
- **基于****TF-IDF****思想**,构造cluster与cluster之间具有区分性偏好的top播放视频
- Random Publish Vidoes
- 随机抽样投稿
- Top Favorite Videos
- 视频收藏次数
- Word Cloud
- 词云分布
- Top Unique Words
- **基于****TF-IDF****思想**,构造cluster与cluster之间具有区分性偏好的top播放视频
- Random Avatars
- 随机抽样头像
- ......- cluster的定量分析
- Age/ Gender/OS Breakdown
- 年龄/性别/操作系统的分布
- VV(video view)
- 视频播放次数
- VVed
- 视频被播放次数
- Publish/Share/Like/Comment
- 投稿/分享/点赞/评论
- Active Days
- 活跃天数
- Retention Rate 2d/7d
- 2d/7d 留存率
- ......- cluster 稳定性分析
- cluster中心点漂移diff
- 表示两次聚类任务实例cluster中心点向量的漂移距离,用来判断群体兴趣偏好是否整体发生变化;该值持续保持在0.5以下的某个水平线上下浮动就是群体偏好没改变。
- 相邻两个周期同一个cluster的用户占比
- 表示上次聚类任务的用户所属cluster与本次聚类任务的用户所属cluster是一致的比例,该值越大,cluster越稳定,用于观察cluster群体用户变化情况。
- 直接review cluster的定性与定量指标,发现偏好内容及指标是否有变化。 | - **定性指标**- **定量指标**- **趋势图**
- 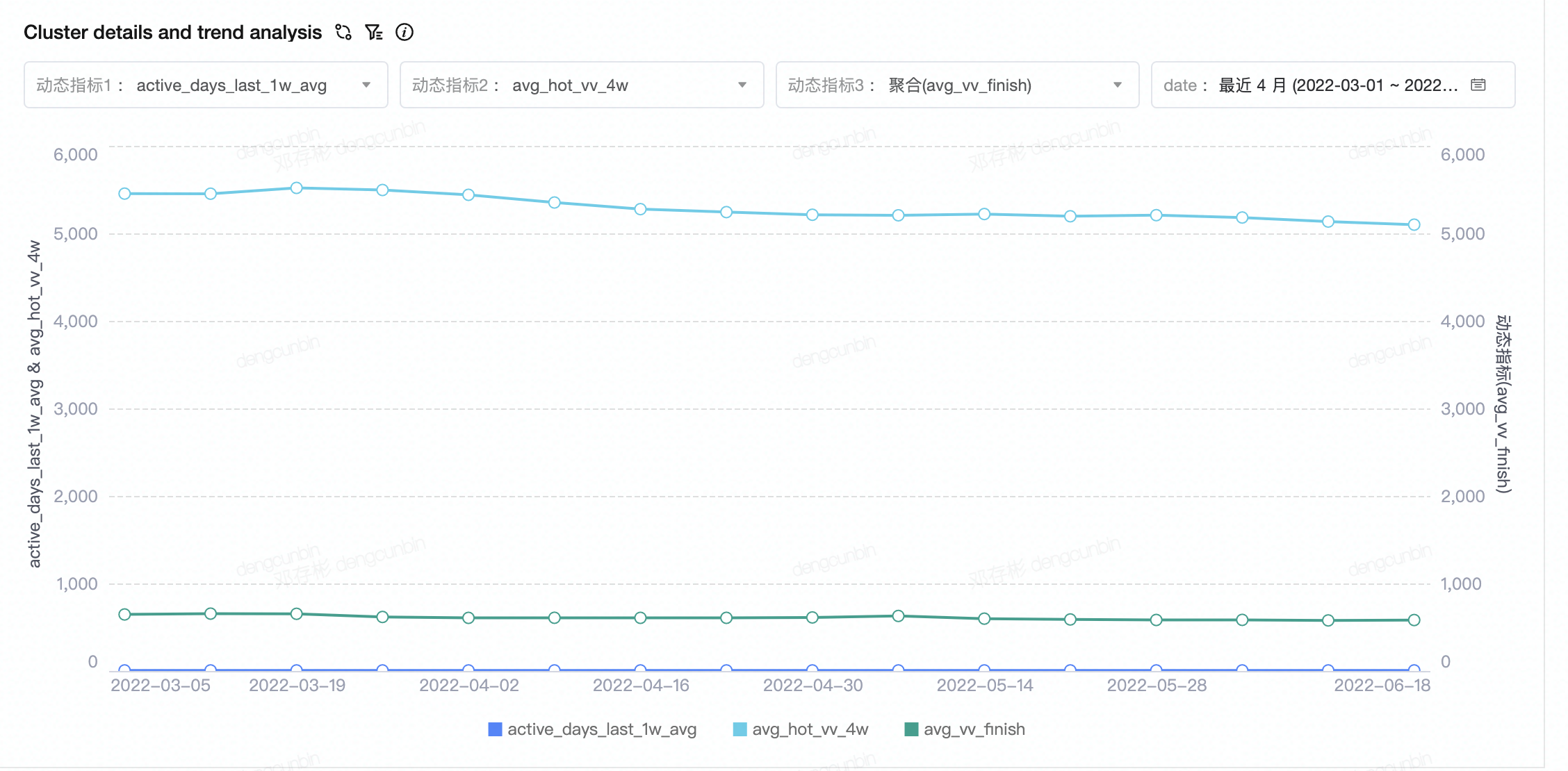- **North Star**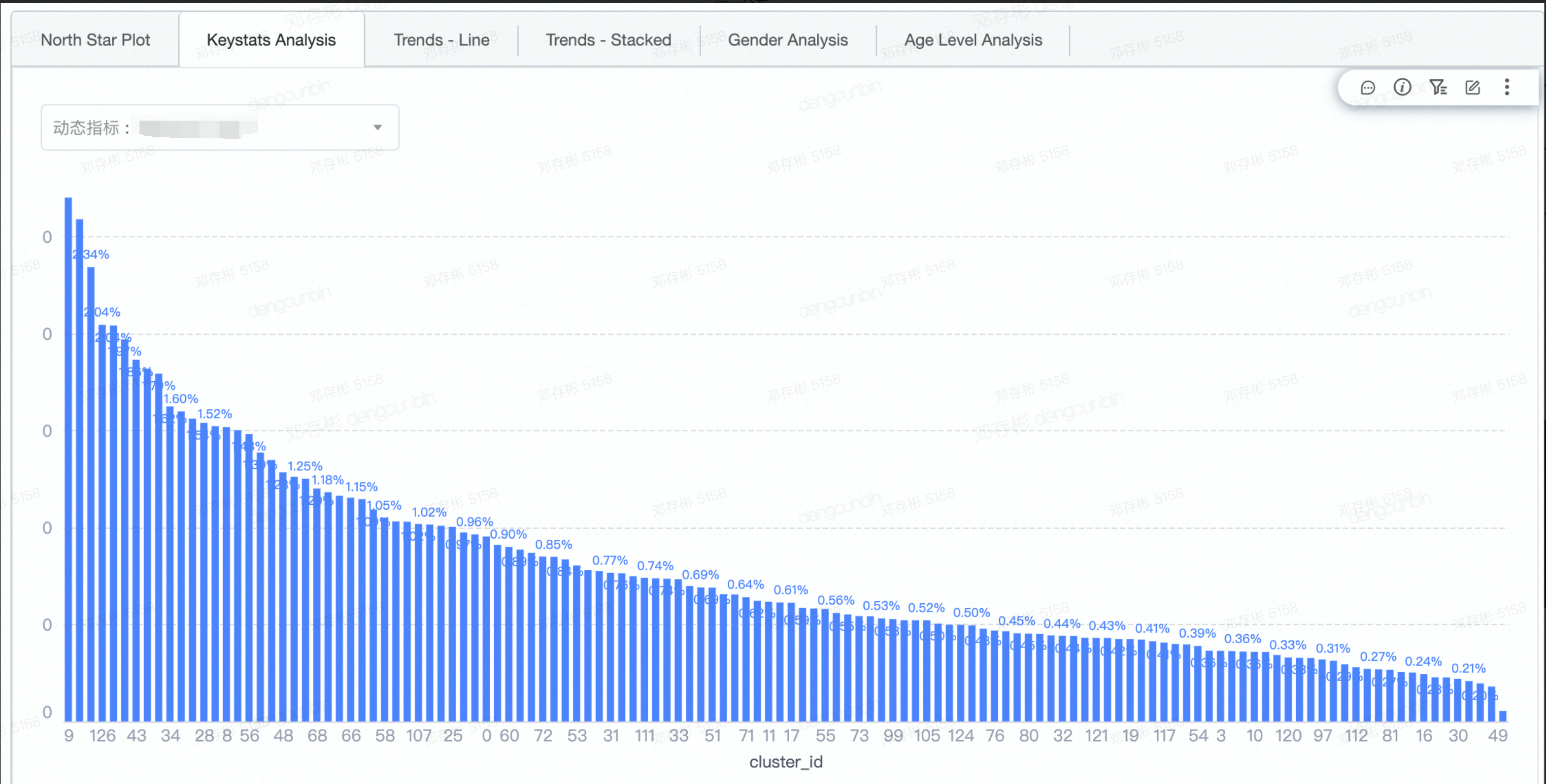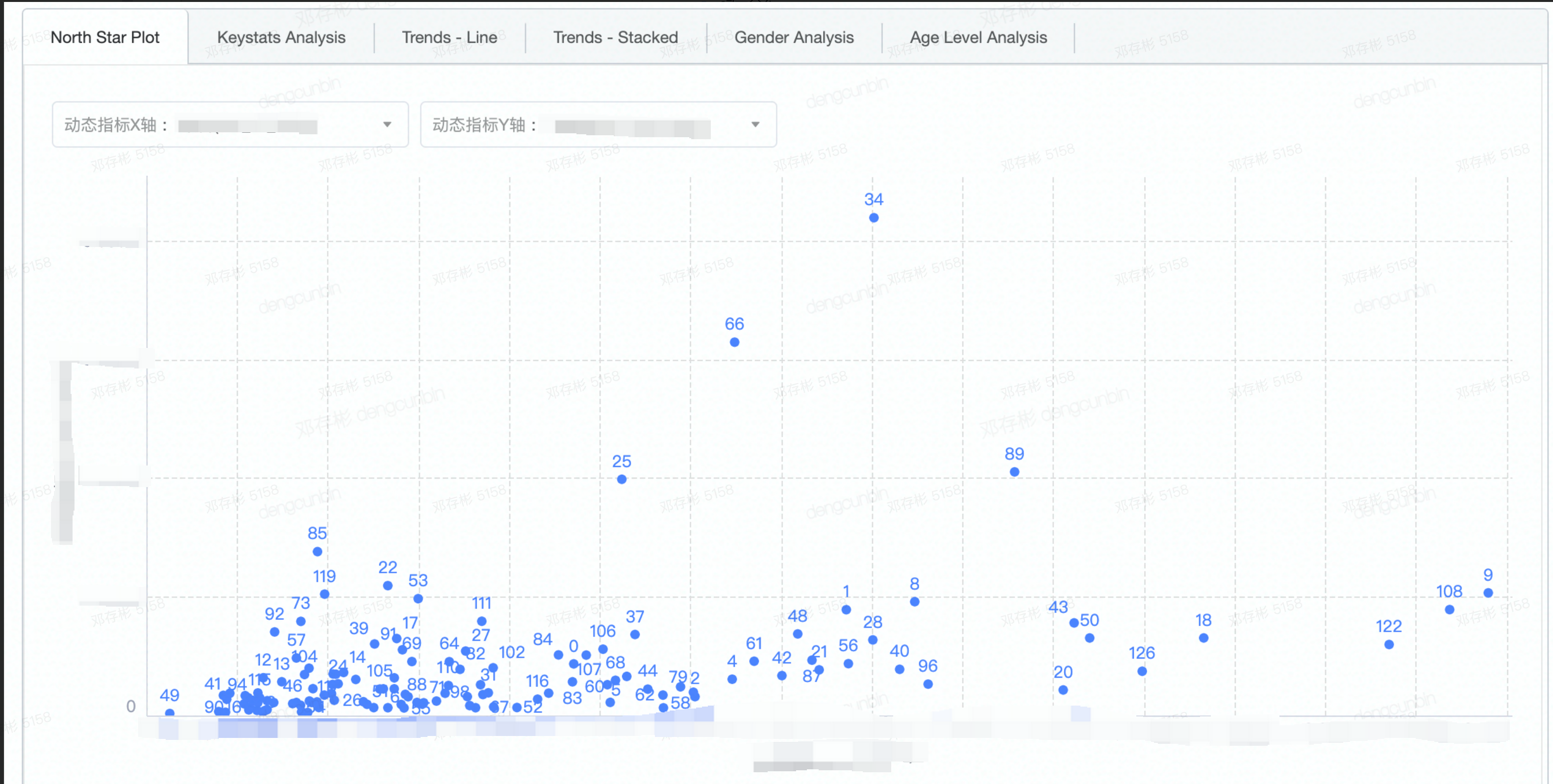**稳定性分析**- **cluster中心点漂移** **diff**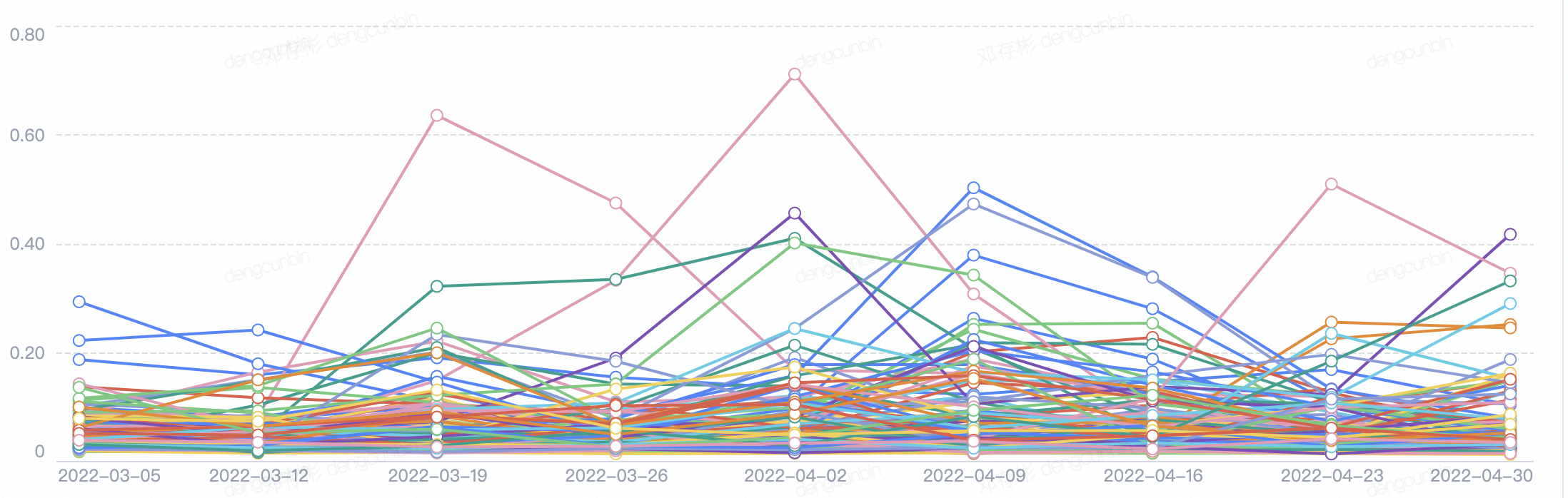- **相邻两个周期同一个cluster的用户占比**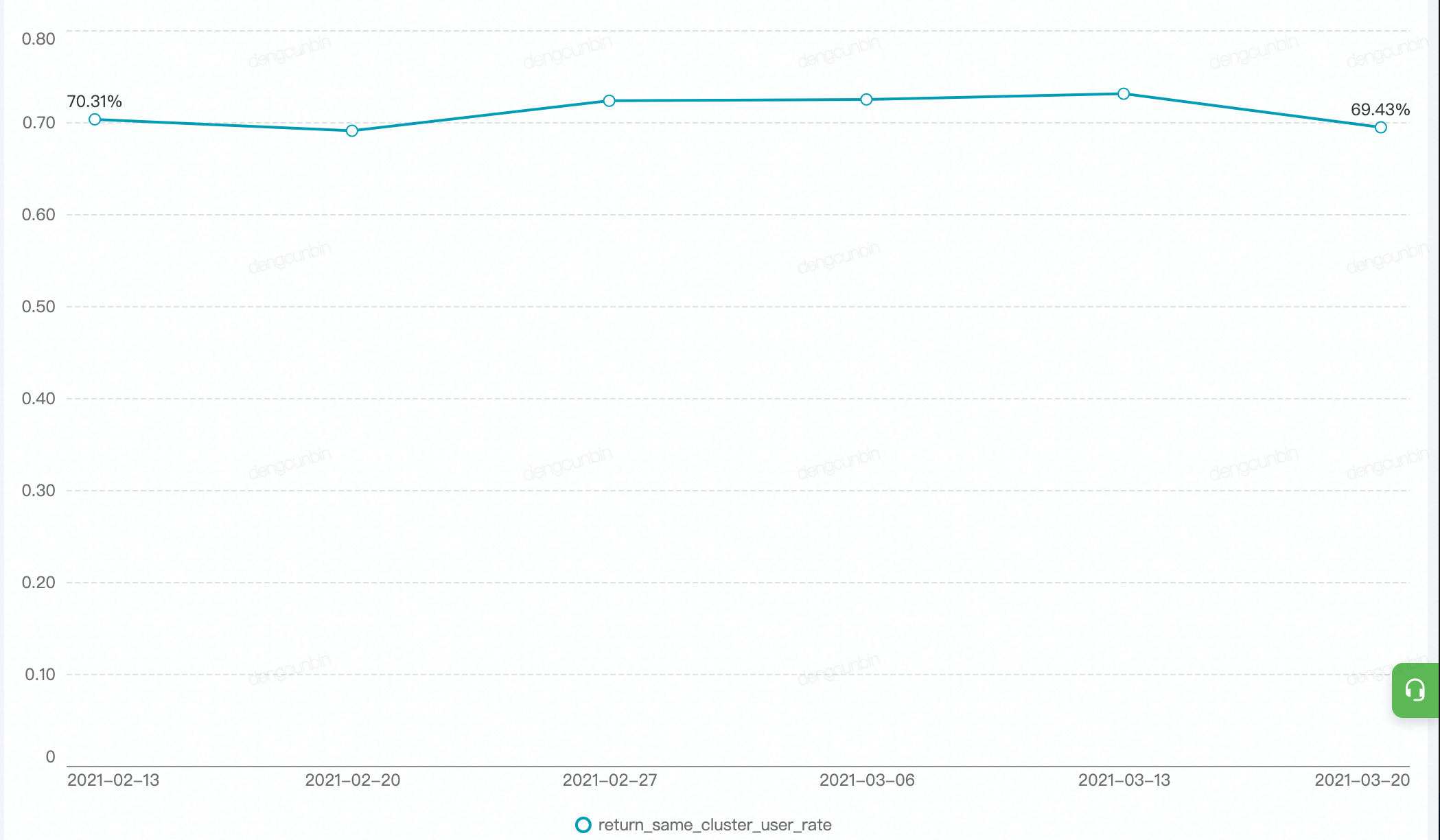 |
复制代码
| 5 | 人工标注 | 通过将用户在Cluster可视化分析中得出的定性+定量的结论进行标注 | - cluster与tribe是一对多的关系- 标注逻辑会被保存至之后周期性运行的任务中,方便用户快速查看标注后的指标数据,但是用户有必要每周确认匹配逻辑是否发生了迁移。 | | | 6 | Tribe Level 可视化分析 | 通过用户标注的cluster-tribe匹配逻辑,渲染tribe level分析页面,为用户提供对tribe进行跟踪分析的能力。 | - 所呈现的指标与Cluster Level一致 | |
2.4 应用场景
- 用户群体的兴趣偏好,帮助理解站内人群的结构
- 内容消费情况,帮助理解哪些内容更受欢迎
- 发现核心群体,基于其喜欢的内容,制定增长策略
三、个人总结:
机器学习不是说你知道了这个知识你就入门了,机器学习还需要一定的数学、统计学知识,并把所学的知识加以实践才能真正懂得机器学习的精妙之处。如像淘宝用户的行为分析中可以通过K-means聚类算法来探究用户使用不同功能的时长占比、点击占比等。对产品优化更有帮助。
四、参考文献
大数据 理论基础
机器学习理论基础
| 快速入门 | 推荐描述 | 相关链接 |
|---|---|---|
| 吴恩达《Machine Learning》 | 这绝对是机器学习入门的首选课程,没有之一!即便你没有扎实的机器学习所需的扎实的概率论、线性代数等数学基础,也能轻松上手这门机器学习入门课,并体会到机器学习的无穷趣味。 | 课程主页- www.coursera.org/learn/machi… github.com/fengdu78/Co… |
| 周志华《机器学习》 | 被大家亲切地称为“西瓜书”。这本书非常经典,讲述了机器学习核心数学理论和算法,适合有作为学校的教材或者中阶读者自学使用,入门时学习这本书籍难度稍微偏高了一些。 | 读书笔记- www.cnblogs.com/limitlessun… github.com/Vay-keen/Ma… datawhalechina.github.io/pumpkin-boo… zhuanlan.zhihu.com/c_101385029… |
| 李航 《统计学习方法》 | 包含更加完备和专业的机器学习理论知识,作为夯实理论非常不错 | 读书笔记- www.cnblogs.com/limitlessun… github.com/SmirkCao/Li… zhuanlan.zhihu.com/p/36378498 |
