

正则表达式

一.匹配符
.表示匹配任意一个字符,
比如b.可以匹配ba bb bc bd等等,.可以理解成省略号...,省略一个任意字符;
比如bby,通过b.可以匹配出bb,不能匹配出by
^表示匹配开始位置
比如^b,可以匹配以b开头的字符b,比如bbba可以匹配到最开头的b,如果是cbba则匹配不到里面的b
^上尖号,理解成顶天,行首
$表示匹配结尾位置
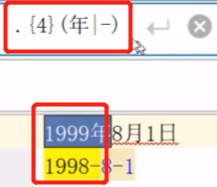
比如ca$,可以匹配以ca结尾的支符串ca,与上尖号类似
$现状像尾巴,故匹配结尾位置
\d表示匹配一个数字,相当于[0-9],digit:数字.
\D表示匹配一个非数字,相当于[^0-9]
\s表示匹配任意的一个空白字符,space:空格
\S表示匹配任意的一个非空白字符
\w表示匹配一个数字、字母、下划线,word:单词
\W表示匹配一个非数字、字母、下划线
二.限定符
*星号,匹配前一个字符出现0到n次
比如b*会匹配b这个字符出现0次到n次,
如果是bobbby,则会匹配出b(1次),bbb(3次,取最大串)
想想天上的星星,可以看不见星星,也可以有满天星星(0,到n次)
+ 匹配前一个字符出现1到n次
每次增加,至少要增加1以上,所以匹配前一个字符出现1到n次
?匹配前一个字符出现0到1次
问号,问你有没有,有1无0,所以只匹配前一个字符出现0到1次
{m,n}匹配前一个字符出现m到n次,包含m与n
三.逻辑符
|或
o|cb会把|这个两边的字符串当成整体,即匹配出o与cb
(o|c)b会匹配出ob与cb
与程序中的或符号||对应记忆
\\转义字符
以上出现的,带有含义的字符,转以后都变成普通的字符
\\.代表匹配字符.
\\代表匹配字符\
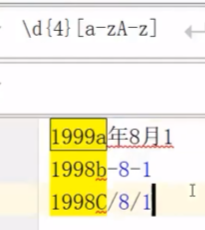
[]字符集,代表匹配这里面的任意的一个字符
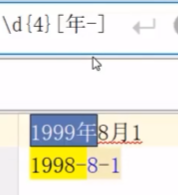
[]里面如果出现-,则代表一个区间,如果想使用-字符,而非使用区间,则将-写到[]开头
[]里面出现的其他字符,都是纯字符,比如[.]仅代表.字符,不带有其他含义
正则表达式python接口
一.match 匹配,提取
info = "姓名:bobby1987 生日:1987年10月1日 本科:2005年9月1日"
match_res = re.match('.*生日.*\d{4}',info)
#1.match方法是从字符串的最开始匹配的,所以前面要加上.*
#2.match方法是按照最长的能匹配到的串来截取的
match_res = re.match('.*生日.*?\d{4}',info)
#3.这里加了一个问号后,就按照第一个能匹配到的串来截取(不是最长的串)
match_res = re.match('.*生日.*?(\d{4}).*本科.*(\d{4})',info)
#4.match提取字符串:将想要的字符串用括号括起来,使用如下方法提取
print(match_res.group(2))
#match_res.group(0)代表匹配到的总的字符串
#match_res.group(1)是提取自己括起来的第一个括号内的内容
match_res = re.match('.*生日.*\d{4}',info,re.I)
#re.I代表忽略大小写
match_res = re.match('.*生日.*\d{4}',info,re.DOTALL)
#match匹配的截止位置是回车换行符,意思是只匹配一行,如果数据有换行,并且在第二行就匹配不到
#re.DOTALL参数代表可以匹配回车换行
二.search 搜索
search_res = re.search('生日.*\d{4}',info)
#1.search与match用法相似,但是有以下两个不同点
#search不是从字符串头部开始匹配的,所以最前面不要加.*
#search默认可以匹配回车换行符,不需要参数re.DOTALL
三.sub 替换
res = re.sub('\d{4}','2019',info)
#将所有的4位数字替换成2019
#还有一个方法了解一下即可
print(re.findall('\d{4}',info)) #返回一个列表,里面有查询出来的所有值
本文由mdnice多平台发布
