

技术面自我介绍
技术自我介绍: 面试官您好,我是xxx,今年20,是福州大学机械专业的一位本科生,我面试的岗位是前端岗位,我是通过自学的方式学习前端的,目前学习前端已经1年了。平时自学有通过看书,例如红宝书,dom编程艺术,图解http等来学习,也有通过浏览github、gitee、MDN等进行学习.........
接下来我简要的介绍下我的项目 业务:(我认为一名合格的前端首先要会写业务) 1、两个项目都实现了移动端适配==>这里我是通过rem来进行适配的 2、两个项目都实现了登录功能,都是采用token的形式去实习的登录功能==>相当于防范了csrf攻击吧 3、在社区服务项目中我通过路由进行了权限管理 4、在两个项目中我都对axios进行了封装,提高了开发体验 5、在音乐播放器这个项目中我进行了一个下拉刷新功能的实现
用户感官方面的优化:(这个优化可能对性能上的提高不明显,但是对于交互上的提升是比较明显的) 1、通过nprogress这个小进度条提升交互感 2、通过betterScroll使得页面滑动变得更加的丝滑 3、通过骨架屏让使得去提升交互
真实项目性能优化:(对于性能上的提升是明显的) 1、通过长列表渲染来实现对于较长数据的渲染(vue-virtual-scroller) 2、通过路由懒加载的形式实现了相当于按需加载吧 3、通过防抖、节流来实现性能优化 4、通过约束自身代码规范来减少回流重绘 5、通过CDN引入外部资源来减少首屏渲染时间
业务
移动端适配
为什么要移动端适配?
一般情况下设计稿的设计师按照375的尺寸设计,然而,在现在移动终端(就是手机)快速更新的时代,每个品牌的手机都有着不同的物理分辨率,这样就会导致,每台设备的逻辑分辨率也不尽相同,此时375的设计稿,如果想要还原那基本是不可能了,因为如果一个左右布局,左边如果写死,右边自适应的话,每个设备的右边所展示的内容大小就不尽相同,这是移动端适配就显得尤其重要 要知道几个名词:物理像素/逻辑像素/像素dpr==》devicePixelRatio
如何解决1px问题
核心思路:
在web中,浏览器为我们提供了window.devicePixelRatio来帮助我们获取dpr。
在css中,可以使用媒体查询min-device-pixel-ratio,区分dpr
我们根据这个像素比,来算出他对应应该有的大小,但是暴露个非常大的兼容问题
解决过程会出现什么问题呢?
说说什么是视口吧(viewport)
viewport 即视窗、视口,用于显示网页部分的区域,在 PC 端视口即是浏览器窗口区域,在移动端,为了让页面展示更多的内容,视窗的宽度默认不为设备的宽度,在移动端视窗有三个概念:布局视窗、视觉视窗、理想视窗
- 布局视窗:在浏览器窗口css的布局区域,布局视口的宽度限制css布局的宽。为了能在移动设备上正常显示那些为pc端浏览器设计的网站,移动设备上的浏览器都会把自己默认的 viewport 设为 980px 或其他值,一般都比移动端浏览器可视区域大很多,所以就会出现浏览器出现横向滚动条的情况
- 视觉视窗:终端设备显示网页的区域
- 理想视窗:针对当前设备最理想的展示页面的视窗,不会出现横向滚动条,页面刚好全部展现在视窗内,理想视窗也就是终端屏幕的宽度。
移动端视口配置怎么配的?
移动端适配有哪些方案知道吗?
1、rem布局 2、vw、vh布局 3、媒体查询响应式布局
说说媒体查询吧?
通过媒体查询,可以针对不同的屏幕进行单独设置,但是针对所有的屏幕尺寸做适配显然是不合理的,但是可以用来处理极端情况(例如 IPad 大屏设备)或做简单的适配(隐藏元素或改变元素位置)
说说rem适配吧
rem是CSS3新增的一个相对单位,这个单位引起了广泛关注。这个单位与em有什么区别呢?区别在于使用rem为元素设定字体大小时,仍然是相对大小,但相对的只是HTML根元素。这个单位可谓集相对大小和绝对大小的优点于一身,通过它既可以做到只修改根元素就成比例地调整所有字体大小,又可以避免字体大小逐层复合的连锁反应。目前,除了IE8及更早版本外,所有浏览器均已支持rem。对于不支持它的浏览器,应对方法也很简单,就是多写一个绝对单位的声明。这些浏览器会忽略用rem设定的字体大小
rem的具体适配方案知道吗?
flexible.js适配:阿里早期开源的一个移动端适配解决方案
因为当年viewport在低版本安卓设备上还有兼容问题,而vw,vh还没能实现所有浏览器兼容,所以flexible方案用rem来模拟vmin来实现在不同设备等比缩放的“通用”方案,之所以说是通用方案,是因为他这个方案是根据设备大小去判断页面的展示空间大小即屏幕大小,然后根据屏幕大小去百分百还原设计稿,从而让人看到的效果(展示范围)是一样的,这样一来,苹果5 和苹果6p屏幕如果你按照设计稿还原的话,字体大小实际上不一样,而人们在一样的距离上希望看到的大小其实是一样的,本质上,用户使用更大的屏幕,是想看到更多的内容,而不是更大的字。
rem的弊端知道吗
弊端之一:和根元素font-size值强耦合,系统字体放大或缩小时,会导致布局错乱 弊端之二:html文件头部需插入一段js代码
说说vw/vh适配
vh、vw方案即将视觉视口宽度 window.innerWidth和视觉视口高度 window.innerHeight 等分为 100 份
vw和vh有啥不足吗?
vw和vh的兼容性:
Android 4.4 之下和 iOS 8 以下的版本有一定的兼容性问题(但是目前这两版本已经很少有人使用了)
rem的兼容性:
当下主流的写法可以说说吗?
登录功能
能具体说说登录功能是怎么做的吗?
1、当某个页面需要登录时重定向到登录页面
这是由于在router.beforeEach进行了拦截
2、click事件触发登录操作:
3、登录成功后获得token
登录成功后,服务端会返回一个 token(该token的是一个能唯一标示用户身份的一个key),之后我们将token存储在本地cookie/localStorage之中,这样下次打开页面或者刷新页面的时候能记住用户的登录状态,不用再去登录页面重新登录了。
ps:为了保证安全性,可能token有效期(Expires/Max-Age)都是Session,就是当浏览器关闭了就丢失了。重新打开游览器都需要重新登录验证,后端也会在每周固定一个时间点重新刷新token,让后台用户全部重新登录一次,确保后台用户不会因为电脑遗失或者其它原因被人随意使用账号。
用cookie要怎么实现这个登录功能呢?
前端可以自己创建 cookie,如果服务端创建的 cookie 没加HttpOnly,那恭喜你也可以修改他给的 cookie。 调用document.cookie可以创建、修改 cookie,和 HTTP 一样,一次document.cookie能且只能操作一个 cookie。
cookie+sesson的流程是咋样的?
服务器端的 SessionId 可能存放在很多地方,例如:内存、文件、数据库等。
为什么不使用cookie+session呢?
虽然我们使用 Cookie + Session 的方式完成了登录验证,但仍然存在一些问题:
- 由于服务器端需要对接大量的客户端,也就需要存放大量的 SessionId,这样会导致服务器压力过大。
- 如果服务器端是一个集群,为了同步登录态,需要将 SessionId 同步到每一台机器上,无形中增加了服务器端维护成本。
- 由于 SessionId 存放在 Cookie 中,所以无法避免 CSRF 攻击。
cookie有过期时间吗?
cookie:通过 Expires、Max-Age 中的一种 Expires属性指定一个具体的到期时间,到了指定时间以后,浏览器就不再保留这个 Cookie。它的值是 UTC 格式。如果不设置该属性,或者设为null,Cookie 只在当前会话(session)有效,浏览器窗口一旦关闭,当前 Session 结束,该 Cookie 就会被删除。另外,浏览器根据本地时间,决定 Cookie 是否过期,由于本地时间是不精确的,所以没有办法保证 Cookie 一定会在服务器指定的时间过期。 Max-Age属性指定从现在开始 Cookie 存在的秒数,比如60 * 60 * 24 * 365(即一年)。过了这个时间以后,浏览器就不再保留这个 Cookie。 如果同时指定了Expires和Max-Age,那么Max-Age的值将优先生效。 如果Set-Cookie字段没有指定Expires或Max-Age属性,那么这个 Cookie 就是 Session Cookie,即它只在本次对话存在,一旦用户关闭浏览器,浏览器就不会再保留这个 Cookie。
cookie能跨域携带吗?
- 前端请求时在request对象中配置"withCredentials": true;
- 服务端在response的header中配置"Access-Control-Allow-Origin", "http://xxx:${port}";
- 服务端在response的header中配置"Access-Control-Allow-Credentials", "true"
怎么能防止cookie被窃取呢?
通过配置cookie的:Secure / HttpOnly Secure属性指定浏览器只有在加密协议 HTTPS 下,才能将这个 Cookie 发送到服务器。另一方面,如果当前协议是 HTTP,浏览器会自动忽略服务器发来的Secure属性。该属性只是一个开关,不需要指定值。如果通信是 HTTPS 协议,该开关自动打开。 HttpOnly属性指定该 Cookie 无法通过 JavaScript 脚本拿到,主要是Document.cookie属性、XMLHttpRequest对象和 Request API 都拿不到该属性。这样就防止了该 Cookie 被脚本读到,只有浏览器发出 HTTP 请求时,才会带上该 Cookie。
cookie、localStorage、sessionStorage的区别能说说吗?
cookie
生命周期:
cookie:可设置失效时间,没有设置的话,默认是关闭浏览器后失效
localStorage:除非被手动清除,否则将会永久保存。
sessionStorage: 仅在当前网页会话下有效,关闭页面或浏览器后就会被清除。
存放数据大小:
cookie:4KB左右
localStorage和sessionStorage:可以保存5MB的信息。
http请求:
cookie:每次都会携带在HTTP头中,如果使用cookie保存过多数据会带来性能问题
localStorage和sessionStorage:仅在客户端(即浏览器)中保存,不参与和服务器的通信
session有什么不足吗?
Session 机制有个缺点,比如 A 服务器存储了 Session,就是做了负载均衡后,假如一段时间内 A 的访问量激增,会转发到 B 进行访问,但是 B 服务器并没有存储 A 的 Session,会导致 Session 的失效。
为什么采用token呢?
Token 是服务端生成的一串字符串,以作为客户端请求的一个令牌。当第一次登录后,服务器会生成一个 Token 并返回给客户端,客户端后续访问时,只需带上这个 Token 即可完成身份认证。
- 用户输入账号密码,并点击登录。
- 服务器端验证账号密码无误,创建 Token。
- 服务器端将 Token 返回给客户端,由客户端自由保存。
token可以避开同源策略吗?
Token 完全由应用管理,所以它可以避开同源策略
token可以在服务间共享吗?
Token 可以是无状态的,可以在多个服务间共享。
token怎么生成的?
最常见的 Token 生成方式是使用 JWT(Json Web Token),它是一种简洁的,自包含的方法用于通信双方之间以 JSON 对象的形式安全的传递信息。 上文中我们说到,使用 Token 后,服务器端并不会存储 Token,那怎么判断客户端发过来的 Token 是合法有效的呢? 答案其实就在 Token 字符串中,其实 Token 并不是一串杂乱无章的字符串,而是通过多种算法拼接组合而成的字符串,我们来具体分析一下。 JWT 算法主要分为 3 个部分:header(头信息),playload(消息体),signature(签名)。
token存在哪里呢?
- 存储在localStorage中,每次调用接口的时候都把它当成一个字段传给后台
- 存储在cookie中,让它自动发送,不过缺点就是不能跨域
- 拿到之后存储在localStorage中,每次调用接口的时候放在HTTP请求头的Authorization字段里面
token有过期时间吗?
token有过期时间的,jwt可以通过设置第三个属性来实现过期时间的设置 jwt.sign(xxx,xxx,time)
Token存放在cookie, sessionStorage 和 localStorage 中的区别
Token 在用户登录成功之后返回给客户端,客户端组要有三种存储方式
- 储存在 localStorage 中,每次调用接口时放在http请求头里面,长期有效
- 储存在 sessionStorage 中,每次调用接口时把它当为一个字段传给后台,浏览器关闭自动清除
- 储存在 cookie 中,每次调用接口会自动发送,不过缺点是不能跨域
区别: 将 Token 存储在 webStorage(localStorage,sessionStorage) 中可以通过同域的js访问,这样导致很容易受到 ==xss== 攻击,特别是项目中引入很多第三方js库的情况下,如果js脚本被盗用,攻击者就可以轻易访问你的网站。
将 Token 存储在 cookie 中,可以指定 httponly 来防止 js 被读取,也可以指定 secure 来保证 Token 只在 HTTPS 下传输,缺点是不符合 RestFul 最佳实践,容易受到 ==CSRF== 攻击。
jwt是啥?
- JSON Web Token(简称 JWT)是目前最流行的跨域认证解决方案。
- 是一种认证授权机制。
- 客户端收到服务器返回的 JWT,可以储存在 Cookie 里面,也可以储存在 localStorage。
jwt和token有啥区别吗?
相同:
- 都是访问资源的令牌
- 都可以记录用户的信息
- 都是使服务端无状态化
- 都是只有验证成功后,客户端才能访问服务端上受保护的资源
区别:
- Token:服务端验证客户端发送过来的 Token 时,还需要查询数据库获取用户信息,然后验证 Token 是否有效。
- JWT: 将 Token 和 Payload 加密后存储于客户端,服务端只需要使用密钥解密进行校验(校验也是 JWT 自己实现的)即可,不需要查询或者减少查询数据库,因为 JWT 自包含了用户信息和加密的数据。
还有什么鉴权方式吗?
- Session-Cookie
- Token 验证(包括 JWT,SSO)
权限管理
说说权限管理你是怎么做的吧?
有很多人表示他们公司的路由表是于后端根据用户的权限动态生成的,我司不采取这种方式的原因如下:
- 项目不断的迭代你会异常痛苦,前端新开发一个页面还要让后端配一下路由和权限,让我们想了曾经前后端不分离,被后端支配的那段恐怖时间了。
- 其次,就拿我司的业务来说,虽然后端的确也是有权限验证的,但它的验证其实是针对业务来划分的,比如超级编辑可以发布文章,而实习编辑只能编辑文章不能发布,但对于前端来说不管是超级编辑还是实习编辑都是有权限进入文章编辑页面的。所以前端和后端权限的划分是不太一致。
- 还有一点是就vue2.2.0之前异步挂载路由是很麻烦的一件事!不过好在官方也出了新的api,虽然本意是来解决ssr的痛点的。。。
具体怎么实现的权限管理呢?
路由拦截怎么做的?
这里还需要用到vue-router的一个钩子,beforeEach这个全局守卫,他有三个参数:to,from,next
- to:你要跳转去的页面的route信息
- from:当前页面的route信息
- next:需要使用这个方法来resolve钩子,不然无法成功进行页面跳转
菜单权限要怎么控制呢?
常见的菜单权限控制有两种办法,前端控制和后端控制,不过最好是前端来进行控制,不然你想加一个菜单还必须要和后端说,让他加一个菜单,会比较麻烦。 不过不管是前端控制还是后端控制,都需要拿到登录用户对应的菜单列表,然后通过vue-router的addRoutes方法将路由添加上去。
怎么解决的? 具体实现方法是,前端控制可以给路由表每一个路由都添加一个唯一Id,我之前的写法是直接给死role:['admin','test']这样写的,但是这样写有一个问题,如果某个角色想修改权限或者是新加了一个角色,这样子还得重新修改代码,所以这次修改直接给每一个菜单一个对应的roleId,之后就根据登录时的roleIds和路由表里面roleId进行比对,获取到当前用户对应的菜单。
权限的路由表要怎么设计呢?
路由表里面可以定好两种路由,一种是不需要权限控制的,如:登录页,404页面等,一种是需要权限控制的; 这里basRoute就是基础路由,asyncRoutes是需要权限控制的路由,这里是store的permission文件,主要功能就是根据登录用户的roleIds获取对应的路由菜单
富文本编辑器
使用的库是什么
vue-quill-editor
为什么采用这个库
他的原理是什么
还知道哪些其他的库吗
vue2-editor
为什么不用vue2-editor呢?
下拉刷新
下拉刷新的原理有去了解吗
首先要知道主要使用的事件有哪些?
- touchstart: 手指触屏触发的事件,主要工作是在触发时获取鼠标点击的Y坐标,event.touches[0].pageY。
- touchmove: 手指滑动触发的事件, 主要工作是在触发时获取移动的Y坐标减去开始时的Y坐标,得出移动的距离,然后利用transform改变容器的位置。
- touchend: 手指松开触发的事件,主要工作是释放鼠标让div恢复原来位置。
封装axios
为什么使用axios能说说吗?
axios的使用情况
fetch的使用情况
能说说axios具体是怎么封装的吗
1、环境判断
2、设置超时时间、是否携带凭证、post的格式
3、请求拦截器
4、响应拦截器
能说说具体代码实现吗
用过fetch吗?fetch和axios的区别知道吗?
1、最大的不同:
最大的不同点在于Fetch是浏览器原生支持,而Axios需要引入Axios库。
2、兼容性方面
Axios可以兼容IE浏览器,而Fetch在IE浏览器和一些老版本浏览器上没有受到支持,但是有一个库可以让老版本浏览器支持Fetch即它就是whatwg-fetch,它可以让你在老版本的浏览器中也可以使用Fetch,并且现在很多网站的开发都为了减少成本而选择不再兼容IE浏览器。
3、响应超时
Axios的相应超时设置是非常简单的,直接设置timeout属性就可以了,而Fetch设置起来就远比Axios麻烦,这也是很多人更喜欢Axios而不太喜欢Fetch的原因之一。
4、对数据的转换
Axios还有非常好的一点就是会自动对数据进行转化,而Fetch则不同,它需要使用者进行手动转化。
5、拦截器
Fetch没有拦截器功能,但是要实现该功能并不难,直接重写全局Fetch方法就可以办到。
最后附带上一些想法:
通讯录功能
通讯录基本功能有哪些?
1.按照字母分类(A-Z)===>构建一个数组
2.侧边栏高亮显示
3.侧边栏点击跳转与滑动页面侧边栏高亮显示
4.侧边栏滑动跳转
用户感官方面的优化
nprogress
源码分析地址:blog.csdn.net/qq_31968791…
使用到的库是什么
nprogress
进度条的实现原理知道吗
Nprogress的原理非常简单,就是页面启动的时候,构建一个方法,创建一个div,然后这个div靠近最顶部,用fixed定位住,至于样式就是按照自个或者默认走了。
怎么使用这个库的
主要采用的两个方法是nprogress.start和nprogress.done 如何使用: 在请求拦截器中调用nprogress.start 在响应拦截器中调用nprogress.done
为什么采用这个库
betterScroll的原理
使用的库是什么:
better-scroll
为什么使用这个库:
实现原理是什么:
图片懒加载的原理
为什么要使用图片懒加载
在一些图片比较多的网站(比如说大型电商网站)图片是非常多的,如果我们在打开网页的一瞬间就把网站的所有图片加载出来,很有可能造成卡顿和白屏的现象,用户体验变得极其的差. 因为图片真的很多,一瞬间就把网站的所有图片加载出来浏览器短时间内根本处理不完,但是我们打开网站的那一瞬间仅仅只能看到视口内的图片,这时候去加载网页最底部的图片是非常浪费资源和没有必要的,所以遇到这种情况使用懒加载技术就显得尤为必要了。
图片懒加载怎么实现的?
将页面中的img标签src指向一张小图片或者src为空,然后定义data-src(这个属性可以自定义命名,我才用data-src)属性指向真实的图片。src指向一张默认的图片,否则当src为空时也会向服务器发送一次请求。可以指向loading的地址。
骨架屏的原理
你能说说为啥使用骨架屏吗?
现在的前端开发领域,都是前后端分离,前端框架主流的都是 SPA,MPA;这就意味着,页面渲染以及等待的白屏时间,成为我们需要解决的问题点;而且大项目,这个问题尤为突出。
webpack 可以实现按需加载,减小我们首屏需要加载的代码体积;再配合上 CDN 以及一些静态代码(框架,组件库等等…)缓存技术,可以很好的缓解这个加载渲染的时间过长的问题。
但即便如此,首屏的加载依然还是存在这个加载以及渲染的等待时间问题;
现在的前端开发领域,都是前后端分离,前端框架主流的都是 SPA,MPA;这就意味着,页面渲染以及等待的白屏时间,成为我们需要解决的问题点;而且大项目,这个问题尤为突出。
webpack 可以实现按需加载,减小我们首屏需要加载的代码体积;再配合上 CDN 以及一些静态代码(框架,组件库等等…)缓存技术,可以很好的缓解这个加载渲染的时间过长的问题。
目前主流,常见的解决方案是使用骨架屏技术,包括很多原生的APP,在页面渲染时,也会使用骨架屏。(下图中,红圈中的部分,即为骨架屏在内容还没有出现之前的页面骨架填充,以免留白)
骨架屏的要怎么使用呢?
骨架屏的原理知道吗?
方案一、
在 index.html 中的 div#app 中来实现骨架屏,程序渲染后就会替换掉 index.html 里面的 div#app 骨架屏内容;
方案二、使用一个Base64的图片来作为骨架屏
使用图片作为骨架屏; 简单暴力,让UI同学花点功夫吧;小米商城的移动端页面采用的就是这个方法,它是使用了一个Base64的图片来作为骨架屏。
按照方案一的方案,将这个 Base64 的图片写在我们的 index.html 模块中的 div#app 里面。
方案三、使用 .vue 文件来完成骨架屏
真实项目性能优化
长列表渲染的原理
使用到的库是什么
vue-virtual-scroller
首先这个库在使用上是很方便的,就是它提供了一个标签,相当于是对div标签的一个修改,可以实现列表的渲染等等功能
为什么选用这个库
dom结构是怎样的
如何知道当前页面上是哪一个元素呢
根据scrollTop来知道页面卷去的高度
监听 infinite-list-ghost 的 scroll 事件,根据当前 scrollTop 值,从第一个 item 开始累加高度,当总高度大于 scrollTop 时,则当前的 index 为 startIndex。接着从序号为 startIndex 的 item 开始累加,当累加高度大于屏幕高度时,则此时的序号为 endIndex。有了 startIndex 和 endIndex,即可获取需要渲染的列表片段。
能说说长列表的具体步骤吗
路由懒加载的原理
为什么要使用路由懒加载?
当刚运行项目的时候,发现刚进入页面,就将所有的js文件和css文件加载了进来,这一进程十分的消耗时间。 如果打开哪个页面就对应的加载响应页面的js文件和css文件,那么页面加载速度会大大提升。
懒加载的好处是什么?
懒加载简单来说就是延迟加载或按需加载,即在需要的时候的时候进行加载。
怎么使用的路由懒加载?
使用到的是es6的import语法,可以实现动态导入
路由懒加载的原理是什么?
通过Webpack编译打包后,会把每个路由组件的代码分割成一一个js文件,初始化时不会加载这些js文件,只当激活路由组件才会去加载对应的js文件。
作用就是webpack在打包的时候,对异步引入的库代码进行代码分割时(需要配置webpack的SplitChunkPlugin插件),为分割后的代码块取得名字 Vue中运用import的懒加载语句以及webpack的魔法注释,在项目进行webpack打包的时候,对不同模块进行代码分割,在首屏加载时,用到哪个模块再加载哪个模块,实现懒加载进行页面的优化。
函数式组件
说说什么是函数式组件吧?
没有管理任何状态,也没有监听任何传递给它的状态,也没有生命周期方法,它只是一个接受一些 prop 的函数。简单来说是 一个无状态和无实例的组件
首屏渲染时间
说说首屏渲染时间是怎么看的?
通过window.performance这个api可以查看与性能相关的东西
PerformanceTiming 接口是为保持向后兼容性而保留的传统接口,提供了在加载和使用当前页面期间发生的各种事件的性能计时信息。通过 window.performance.timing 获取。
还知道哪些指标?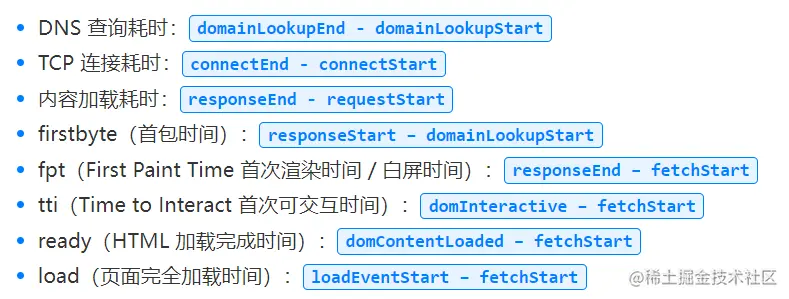
还有什么其他的方法吗?
FMP(First Meaningful Paint)是指页面的主要内容出现在屏幕上所需的时间。
回流重绘
什么是回流知道吗?
当渲染树中部分或者全部元素的尺寸、结构或者属性发生变化时,浏览器会重新渲染部分或者全部文档的过程就称为回流。
什么操作会引起回流知道吗?
- 页面的首次渲染
- 浏览器的窗口大小发生变化
- 元素的内容发生变化
- 元素的尺寸或者位置发生变化
- 元素的字体大小发生变化
- 激活CSS伪类
- 查询某些属性或者调用某些方法
- 添加或者删除可见的DOM元素
说说什么是重绘?
当页面中某些元素的样式发生变化,但是不会影响其在文档流中的位置时,浏览器就会对元素进行重新绘制,这个过程就是重绘。
什么操作会引起重绘呢?
- color、background 相关属性:background-color、background-image 等
- outline 相关属性:outline-color、outline-width 、text-decoration
- border-radius、visibility、box-shadow
在项目中是怎么预防回流重绘的呢?
- 不要使用table布局, 一个小的改动可能会使整个table进行重新布局
- 不要频繁操作元素的样式,对于静态页面,可以修改类名,而不是样式。
- 使用absolute或者fixed,使元素脱离文档流,这样他们发生变化就不会影响其他元素
- 避免频繁操作DOM,可以创建一个文档片段documentFragment,在它上面应用所有DOM操作,最后再把它添加到文档中
- 将元素先设置display: none,操作结束后再把它显示出来。因为在display属性为none的元素上进行的DOM操作不会引发回流和重绘。
- 将DOM的多个读操作(或者写操作)放在一起,而不是读写操作穿插着写。这得益于浏览器的渲染队列机制。
浏览器针对页面的回流与重绘,进行了自身的优化——渲染队列 浏览器会将所有的回流、重绘的操作放在一个队列中,当队列中的操作到了一定的数量或者到了一定的时间间隔,浏览器就会对队列进行批处理。这样就会让多次的回流、重绘变成一次回流重绘。 上面,将多个读操作(或者写操作)放在一起,就会等所有的读操作进入队列之后执行,这样,原本应该是触发多次回流,变成了只触发一次回流。
CDN优化
能说说什么是CDN吗?
CDN(Content Delivery Network,内容分发网络)是指一种通过互联网互相连接的电脑网络系统,利用最靠近每位用户的服务器,更快、更可靠地将音乐、图片、视频、应用程序及其他文件发送给用户,来提供高性能、可扩展性及低成本的网络内容传递给用户。 典型的CDN系统由下面三个部分组成:
- 分发服务系统: 最基本的工作单元就是Cache设备,cache(边缘cache)负责直接响应最终用户的访问请求,把缓存在本地的内容快速地提供给用户。同时cache还负责与源站点进行内容同步,把更新的内容以及本地没有的内容从源站点获取并保存在本地。Cache设备的数量、规模、总服务能力是衡量一个CDN系统服务能力的最基本的指标。
- 负载均衡系统: 主要功能是负责对所有发起服务请求的用户进行访问调度,确定提供给用户的最终实际访问地址。两级调度体系分为全局负载均衡(GSLB)和本地负载均衡(SLB)。全局负载均衡主要根据用户就近性原则,通过对每个服务节点进行“最优”判断,确定向用户提供服务的cache的物理位置。本地负载均衡主要负责节点内部的设备负载均衡
- 运营管理系统: 运营管理系统分为运营管理和网络管理子系统,负责处理业务层面的与外界系统交互所必须的收集、整理、交付工作,包含客户管理、产品管理、计费管理、统计分析等功能。
CDN有什么作用知道吗?
CDN一般会用来托管Web资源(包括文本、图片和脚本等),可供下载的资源(媒体文件、软件、文档等),应用程序(门户网站等)。使用CDN来加速这些资源的访问。 (1)在性能方面,引入CDN的作用在于:
- 用户收到的内容来自最近的数据中心,延迟更低,内容加载更快
- 部分资源请求分配给了CDN,减少了服务器的负载
(2)在安全方面,CDN有助于防御DDoS、MITM等网络攻击:
- 针对DDoS:通过监控分析异常流量,限制其请求频率
- 针对MITM:从源服务器到 CDN 节点到 ISP(Internet Service Provider),全链路 HTTPS 通信
除此之外,CDN作为一种基础的云服务,同样具有资源托管、按需扩展(能够应对流量高峰)等方面的优势。
DNS解析与CDN的区别知道吗?
CDN和DNS有着密不可分的联系,先来看一下DNS的解析域名过程,在浏览器输入 www.test.com 的解析过程如下: (1) 检查浏览器缓存 (2)检查操作系统缓存,常见的如hosts文件 (3)检查路由器缓存 (4)如果前几步都没没找到,会向ISP(网络服务提供商)的LDNS服务器查询 (5)如果LDNS服务器没找到,会向根域名服务器(Root Server)请求解析,分为以下几步:
- 根服务器返回顶级域名(TLD)服务器如.com,.cn,.org等的地址,该例子中会返回.com的地址
- 接着向顶级域名服务器发送请求,然后会返回次级域名(SLD)服务器的地址,本例子会返回.test的地址
- 接着向次级域名服务器发送请求,然后会返回通过域名查询到的目标IP,本例子会返回www.test.com的地址
- Local DNS Server会缓存结果,并返回给用户,缓存在系统中
CDN的工作原理知道吗?
(1)用户未使用CDN缓存资源的过程:
- 浏览器通过DNS对域名进行解析(就是上面的DNS解析过程),依次得到此域名对应的IP地址
- 浏览器根据得到的IP地址,向域名的服务主机发送数据请求
- 服务器向浏览器返回响应数据
(2)用户使用CDN缓存资源的过程:
- 对于点击的数据的URL,经过本地DNS系统的解析,发现该URL对应的是一个CDN专用的DNS服务器,DNS系统就会将域名解析权交给CNAME指向的CDN专用的DNS服务器。
- CND专用DNS服务器将CND的全局负载均衡设备IP地址返回给用户
- 用户向CDN的全局负载均衡设备发起数据请求
- CDN的全局负载均衡设备根据用户的IP地址,以及用户请求的内容URL,选择一台用户所属区域的区域负载均衡设备,告诉用户向这台设备发起请求
- 区域负载均衡设备选择一台合适的缓存服务器来提供服务,将该缓存服务器的IP地址返回给全局负载均衡设备
- 全局负载均衡设备把服务器的IP地址返回给用户
- 用户向该缓存服务器发起请求,缓存服务器响应用户的请求,将用户所需内容发送至用户终端
能具体说说CDN是怎么配置的吗?
通过externals这个配置项进行cdn配置
然后通过在index.html中引入相应的cdn资源
cdn资源的话可以通过bootcdn来进行查找
gzip
怎么开启gzip知道吗?
npm i compression-webpack-plugin -D
能说一说gzip的原理吗?
gizp压缩是一种http请求优化方式,通过减少文件体积来提高加载速度。html、js、css文件甚至json数据都可以用它压缩,可以减小60%以上的体积。前端配置gzip压缩,并且服务端使用nginx开启gzip,用来减小网络传输的流量大小。
节流与防抖
说说你对防抖节流的理解吧?
防抖函数的应用场景:
- 按钮提交场景:防⽌多次提交按钮,只执⾏最后提交的⼀次
- 服务端验证场景:表单验证需要服务端配合,只执⾏⼀段连续的输⼊事件的最后⼀次,还有搜索联想词功能类似⽣存环境请⽤lodash.debounce
节流函数的适⽤场景:
- 拖拽场景:固定时间内只执⾏⼀次,防⽌超⾼频次触发位置变动
- 缩放场景:监控浏览器resize
- 动画场景:避免短时间内多次触发动画引起性能问题
webpack
能说说webpack的作用吗?
- 模块打包(静态资源拓展)。可以将不同模块的文件打包整合在一起,并且保证它们之间的引用正确,执行有序。利用打包我们就可以在开发的时候根据我们自己的业务自由划分文件模块,保证项目结构的清晰和可读性。
- 编译兼容(翻译官loader)。在前端的“上古时期”,手写一堆浏览器兼容代码一直是令前端工程师头皮发麻的事情,而在今天这个问题被大大的弱化了,通过webpack的Loader机制,不仅仅可以帮助我们对代码做polyfill,还可以编译转换诸如.less, .vue, .jsx这类在浏览器无法识别的格式文件,让我们在开发的时候可以使用新特性和新语法做开发,提高开发效率。
- 能力扩展(plugins)。通过webpack的Plugin机制,我们在实现模块化打包和编译兼容的基础上,可以进一步实现诸如按需加载,代码压缩等一系列功能,帮助我们进一步提高自动化程度,工程效率以及打包输出的质量。
为什么要打包呢?
逻辑多、文件多、项目的复杂度高了,所以要打包 例如: 让前端代码具有校验能力===>出现了ts css不好用===>出现了sass、less webpack可以解决这些问题
能说说模块化的好处吗?
- 避免命名冲突(减少命名空间污染)
- 更好的分离, 按需加载
- 更高复用性
- 高可维护性
模块化打包方案知道啥,可以说说吗?
1、commonjs
commonjs 是 Node 中的模块规范,通过 require 及 exports 进行导入导出
commonJS用同步的方式加载模块。在服务端,模块文件都存在本地磁盘,读取非常快,所以这样做不会有问题。但是在浏览器端,限于网络原因,更合理的方案是使用异步加载。
总结:commonjs是用在服务器端的,同步的,如nodejs
2、AMD
AMD规范采用异步方式加载模块,模块的加载不影响它后面语句的运行。所有依赖这个模块的语句,都定义在一个回调函数中,等到加载完成之后,这个回调函数才会运行。
语句如下:通过define定义
可以更好的发现模块间的依赖关系
总结:amd, cmd是用在浏览器端的,异步的,如requirejs和seajs
3、CMD
CMD是另一种js模块化方案,它与AMD很类似,不同点在于:AMD 推崇依赖前置、提前执行,CMD推崇依赖就近、延迟执行。此规范其实是在sea.js推广过程中产生的。
总结:amd, cmd是用在浏览器端的,异步的,如requirejs和seajs
4、esm
esm 是 tc39 对于 ESMAScript 的模块话规范,正因是语言层规范,因此在 Node 及 浏览器中均会支持。
它使用 import/export 进行模块导入导出.
如上例所示,使用import命令的时候,用户需要知道所要加载的变量名或函数名。其实ES6还提供了export default命令,为模块指定默认输出,对应的import语句不需要使用大括号。这也更趋近于ADM的引用写法。
export default命令,为模块指定默认输出
那ES6 模块与 CommonJS 模块的差异有哪些呢?
1. CommonJS 模块输出的是一个值的拷贝,ES6 模块输出的是值的引用。
- CommonJS 模块输出的是值的拷贝(浅拷贝),也就是说,一旦输出一个值,模块内部的变化就影响不到这个值。
- ES6 模块的运行机制与 CommonJS 不一样。JS 引擎对脚本静态分析的时候,遇到模块加载命令import,就会生成一个只读引用。等到脚本真正执行时,再根据这个只读引用,到被加载的那个模块里面去取值。原始值变了,import加载的值也会跟着变。因此,ES6 模块是动态引用,并且不会缓存值,模块里面的变量绑定其所在的模块。
2. CommonJS 模块是运行时加载,ES6 模块是编译时输出接口。
- 运行时加载: CommonJS 模块就是对象;即在输入时是先加载整个模块,生成一个对象,然后再从这个对象上面读取方法,这种加载称为“运行时加载”。
- 编译时加载: ES6 模块不是对象,而是通过 export 命令显式指定输出的代码,import时采用静态命令的形式。即在import时可以指定加载某个输出值,而不是加载整个模块,这种加载称为“编译时加载”。
CommonJS 加载的是一个对象(即module.exports属性),该对象只有在脚本运行完才会生成。而 ES6 模块不是对象,它的对外接口只是一种静态定义,在代码静态解析阶段就会生成。
webpack的编译(打包)流程说说
- 初始化参数:解析webpack配置参数,合并shell传入和webpack.config.js文件配置的参数,形成最后的配置结果;
- 开始编译:上一步得到的参数初始化compiler对象,注册所有配置的插件,插件 监听webpack构建生命周期的事件节点,做出相应的反应,执行对象的run方法开始执行编译;
- 确定入口:从配置的entry入口,开始解析文件构建AST语法树,找出依赖,递归下去;
- 编译模块:递归中根据文件类型和loader配置,调用所有配置的loader对文件进行转换,再找出该模块依赖的模块,再递归本步骤直到所有入口依赖的文件都经过了本步骤的处理;
- 完成模块编译并输出:递归完事后,得到每个文件结果,包含每个模块以及他们之间的依赖关系,根据entry或分包配置生成代码块chunk;
- 输出完成:输出所有的chunk到文件系统;
说一下 Webpack 的热更新原理吧?
Webpack 的热更新又称热替换(Hot Module Replacement),缩写为** HMR**。 这个机制可以做到不用刷新浏览器而将新变更的模块替换掉旧的模块。 HMR的核心就是客户端从服务端拉去更新后的文件,准确的说是 chunk diff (chunk 需要更新的部分),实际上 WDS(无线路由)与浏览器之间维护了一个 Websocket,当本地资源发生变化时,WDS 会向浏览器推送更新,并带上构建时的 hash,让客户端与上一次资源进行对比。客户端对比出差异后会向 WDS 发起 Ajax 请求来获取更改内容(文件列表、hash),这样客户端就可以再借助这些信息继续向 WDS 发起 jsonp 请求获取该chunk的增量更新。 后续的部分(拿到增量更新之后如何处理?哪些状态该保留?哪些又需要更新?)由 HotModulePlugin 来完成,提供了相关 API 以供开发者针对自身场景进行处理,像react-hot-loader 和 vue-loader 都是借助这些 API 实现 HMR。
知道babel吗?说说他的原理吧?
Babel大概分为三大部分:
- 解析:将代码转换成 AST
- 词法分析:将代码(字符串)分割为token流,即语法单元成的数组
- 语法分析:分析token流(上面生成的数组)并生成 AST
- 转换:访问 AST 的节点进行变换操作生产新的 AST
- Taro就是利用 babel 完成的小程序语法转换
- 生成:以新的 AST 为基础生成代码
说说什么是AST树?
抽象语法树(Abstract Syntax Tree)简称AST,顾名思义,它是一棵树,用分支和节点的组合来描述代码结构。
AST的编译过程:
词法分析
何为词法?词法组成语言的单词, 是语言中最小单元。我们写的高级语言代码 ,本质上就是一段文本,只不过是按照一定的格式组织的描述逻辑的文本。 因此词法可以理解成我们代码中一系列独立的单词,var,for ,if,while等。词法分析的过程就是读取代码,识别每一个单词及其种类,将它们按照预定的规则合并成一个个的标识,也叫 token,同时,它会移除空白符,注释,等,最终产出一个token数组。即词法分析阶段把会字符串形式的代码转换为 令牌(tokens) 流,用一段伪代码举例:
语法分析
语法,是词法之间的组合方式。前面说到,我们写的源程序是按照一定的格式组织的描述逻辑的文本,而所谓描述逻辑的格式就是指语法。语法分析的任务就是用由词法分析得到的令牌流,在上下文无关文法(一般指某种程序设计语言上的语法)的约束下,生成树形的中间表示(便于描述逻辑结构),该中间表示给出了令牌流的结构表示,同时验证语法,语法如果有错的话,抛出语法错误。
经过词法、语法分析之后就产生了AST,用一棵树形的数据结构来描述源代码,从这里开始就是计算机可以理解的了。有了AST,就可以根据不用需求进行不同操作,如编译器会将AST转换成线性中间代码,生成汇编代码,最后生成机器码。解释器会将AST解释执行或转成线性的中间代码再解释执行。转译器则会将AST转换为另一个AST,再生成目标代码,例如Babel就是一个典型的Javascript转译器,其主要能力是将ES6+代码转换成兼容旧的浏览器或环境的js代码,我们今天也会利用Babel的能力进行AST操作,关于编译的后续步骤如语义分析,代码优化,代码生成等这里就不再过多讨论,接下来具体了解AST。
一个函数要怎么解析成语法树呢?
你知道哪些plugin吗?
- html-webpack-plugin可以根据模板自动生成html代码,并自动引用css和js文件
- clean-webpack-plugin 清理每次打包下没有使用的文件
- HotModuleReplacementPlugin 热更新
你知道哪些loader吗?
- file-loader:把⽂件输出到⼀个⽂件夹中,在代码中通过相对 URL 去引⽤输出的⽂件
- url-loader:和 file-loader 类似,但是能在⽂件很⼩的情况下以 base64 的⽅式把⽂件内容注⼊到代码中去
- source-map-loader:加载额外的 Source Map ⽂件,以⽅便断点调试
- image-loader:加载并且压缩图⽚⽂件
- babel-loader:把 ES6 转换成 ES5
- css-loader:加载 CSS,⽀持模块化、压缩、⽂件导⼊等特性
- style-loader:把 CSS 代码注⼊到 JavaScript 中,通过 DOM 操作去加载 CSS。
- eslint-loader:通过 ESLint 检查 JavaScript 代码
Git
项目里git怎么使用的可以说说吗?
1.在工作区开发,添加,修改文件。 2.将修改后的文件放入暂存区。 3.将暂存区域的文件提交到本地仓库。 4.将本地仓库的修改推送到远程仓库。
知道git的原理吗?说说他的原理吧
Workspace:工作区,就是平时进行开发改动的地方,是当前看到最新的内容,在开发的过程也就是对工作区的操作
Index:暂存区,当执行 git add 的命令后,工作区的文件就会被移入暂存区,暂存区标记了当前工作区中那些内容是被 Git 管理的,当完成某个需求或者功能后需要提交代码,第一步就是通过 git add 先提交到暂存区。
Repository:本地仓库,位于自己的电脑上,通过 git commit 提交暂存区的内容,会进入本地仓库。
Remote:远程仓库,用来托管代码的服务器,远程仓库的内容能够被分布在多个地点的处于协作关系的本地仓库修改,本地仓库修改完代码后通过 git push 命令同步代码到远程仓库。
能说几个git的操作吗?
**git add:**添加文件到暂存区
git commit
git pull=git fetch+git merge
git fetch
与 git pull 不同的是 git fetch 操作仅仅只会拉取远程的更改,不会自动进行 merge 操作。对你当前的代码没有影响
git branch
开发过程中怎么使用的git
1.1 克隆项目 git clone
1.2 查看分支 git branch
1.3 检出代码 git checkout
拉取远程分支代码
1.4 创建分支 git checkout -b
有时你想自己创建一条分支可执行 git checkout -b dev(分支名) 相当于2条命令 git branch dev git checkout dev 切记,一定要在最新master分支上创建新分支
1.5 拉取/提交/推送代码 git pull/git commit/git push
如果是多人在同一分支开发的话,一般在push之前要先pull最新代码,但谁要能保证你即使pull后在到push这一瞬间,有没有人提交代码呢?
1、若别人有提交代码,idea会在你push时提示你要不要merge,若没有冲突会自动合并,此时git日志里会有这么一行记录
Merge remote-tracking branch 'origin/dev' into dev
git的日志记录也不会是一条完整直线了。若有冲突,需要手动解决。
2、若你先pull,没冲突当然最好,有冲突你会pull失败,提示本地修改会被覆盖。
- 这时可以git stash 暂存修改。
- 暂存成功后 git pull拉取代码。
- git unstash将暂存的代码更新到当前分支上。
1.6 撤销操作
1、还没commit就想放弃修改
直接鼠标右键点击文件Revert就好。
2、commit了之后还没push,想撤回commint前操作。
git reset --hard HEAD~ --hard直接还原到上一版本,不保留修改(慎用)
git reset --soft HEAD~ --soft还原到上一版本,保留commit前的修改(常用)
git reset --mixed HEAD~ --mixed 与soft不同的是,还原到git add前没暂存的文件
图形化 GIt->Repository->Reset HEAD...
3、push之后想回退
依然可以用上述操作,只不过在下一次push之后,会拿回退前的版本跟当前修改合并,有冲突要解决。
1.7合并代码 git merge
将远程代码合并到自己当前的分支上。
技术栈对比以及个人想法
前端的主流技术有哪些?
最近在学什么新技术?
svelte
首先,是 React,React 是一个重运行时的框架,在数据发生变化后,并没有直接去操作 dom,而是生成一个新的所谓的虚拟 dom,它可以帮助我们解决跨平台和兼容性问题,并且通过 diff 算法得出最小的操作行为,这些全部都是在运行时来做的。
那么,Vue 这个框架,在运行时和预编译取了一个很好地权衡,它保留了虚拟 dom,但是会通过响应式去控制虚拟 dom 的颗粒度,在预编译里面,又做了足够多的性能优化,做到了按需更新。
最近很火的 Svelte ,就是一个典型的重编译的框架,作为开发者我们只需要去写模版和数据,经过 Svelte 的编译和预处理,代码基本全部会解析成原生的 DOM 操作,Svelte 的性能也是最接近原生 js 的。
svelte的特点:
目的明确
只针对 Web Apps。无虚拟DOM,意味着,不存在像 React,Vue 那样的跨平台的方案,但同时也带来了一定的性能提升(当然这部分的性能提升可能很小,无感知),官网中,更多聚焦在编译体积和速度上。 此外,它还着重地强调了 Reactivity ,它为 JavaScript 自身添加了 reactivity 。此处应当重点关注。
简洁
写法更类似于 Vue
小巧
麻雀虽小,五脏俱全。它拥有 template 无法比拟的优势,就是它拥有生命周期:onMount onDestory beforeUpdate afterUpdate tick 。 此外,它还有事件方面的处理,不仅支持原生事件,还支持组件自定义事件。 也支持 props ,父子组件通信应无问题且跟 React 相类似。 它具有 Vue 的 slot (插槽)功能,使用方法跟 Vue 应相差不大。 还有很多有趣的特有的组件/功能。可以说,在开发上,应当是比较畅通无阻的。
定位
对于 svelte 的定位,它是远远超越了 template 且目的明确,目光只聚焦于 web apps ,且相对于 Vue , React 删减了一些特性,轻装上阵。 如果,项目不打算往跨平台方面去考虑的话,svelte 或许可以一试。
Vite: 下一代前端工具
说说Vue和React的对比?
对微前端的看法?
微前端:云时代的前端开发模式 微前端(Micro-Frontends)概念是2016年底提出,距今已有五年多时间的沉淀,目前在前端领域也有较为广泛地应用。微前端(Micro-Frontends)是一种类似于微服务的架构,是一种由独立交付的多个前端应用组成整体的架构风格,将前端应用分解成一些更小、更简单的能够独立开发、测试、部署的应用,而在用户看来仍然是内聚的单个产品。
Hr面准备
HR面自我介绍
Hr自我介绍: 面试官您好,我是xxx,今年20,是福州大学机械专业的一位本科生。我面试的岗位是前端开发这一职位,大概在去年3月左右,我在一次校园的活动中接触到了前端,在这之前呢其实我对计算机是不怎么了解的。经过一段时间的接触,我就被前端那种所写即所得的魅力所吸引,我个人是十分喜欢这种感觉的,所以大概在去年4月中旬,我开始系统的自学前端,目前学习前端已经接近1年了。平时自学有通过看书,还有浏览一些网站,看b站等形式去学习。我可以说是非常系统的学习了前端的知识也包括了计算机基础知识,也算是经过个人努力,成功通过了前两轮的技术面试,非常感谢阿里也感谢钉钉能给我面试的机会,也十分感谢面试官的认可。我认为我是一个积极向上,热爱生活,热爱运动的人;平日里我除了学习前端知识外的娱乐方式就是运动、听歌,我觉得自己是个运动狂,我平时最喜欢的就是打篮球和健身。此外还会打羽毛球、乒乓球、游泳等。这些都是我业余生活的娱乐方式吧。在校园生活中我也做了很多的尝试,比如参加各类学校组织的活动,以及各类竞赛,包括学科竞赛以及体育竞赛,都有有取得一些成绩;还有就是从大一到大三都有参加学校的学生工作等。可以说我的大学生活算是丰富多彩的。
你自己最大的优点和缺点?
优点: 1、沉着冷静,遇到事情的时候不会慌张,会冷静的思考对策 2、认真细致,特别是对待自己手头工作的时候,我能用心细致的去完成,这也从小养成的一种习惯吧,因为我小时候学习书法和珠心算吧,这两个是需要耐心以及细心的技能,就在这种环境下不断养成的一种细致 3、我认为我有比较强的适应能力,这种适应能力体现在两个方便,第一就是团队协作中,我认为自己能够快速的去融入到团队中;第二就是对于新环境的适应。 4、我有较强的集体荣誉感,我认为集体荣誉是高于个人的,这点也和我个人学生工作以及目前党员的身份息息相关的,我从高中开始有从事学生工作,高一到大三基本把能做的学生工作做了一遍,所以我觉得自己集体荣誉感是很强的,
缺点: 1、首先,我现在是大三,项目经验不足,也缺乏企业化开发的经验,但我相信我会在工作中积极完成工作,积累各方面经验。 2、其次,在学习工作中可能对一些细节过于的吹毛求疵,(过分的追求细节),导致了项目不一定能按规定时间完成,但我也通过了比较合理的时间规划去慢慢弥补这点不足
你从项目中学到了什么?
**一、**首先是我的第一个项目,这个字节的社区服务项目,这是我第一次接触到团队协作的项目,我们小组一共5位成员,其中有1位产品经理,2位前端,2位后端。 在这个项目里我遇到的最大的困难: 首先是技术方面:大家的代码规范不同导致了可能看不懂队友写的是啥,还有就是在开发过程中可能自己的代码出现了问题,或是队友的代码出现了问题导致整个项目出现bug。
解决方法: 1、通过采用合理的技术约束代码规范 2、我们组建了一个群,当项目出现问题时,大家自动会在群里接龙,汇报自己负责区域的情况,然后缩小排查范围,很容易就能找到问题所在
学到了:(团队配合,协作开发) 1、整个团队的配合是很重要的,无论是在学校还是日后在公司中,因为我们都是以一个团队的形式去完成任务的。我认为在一个团队当中,技术的重要性只能占50%左右,很重要的一点是在这个协作方面吧,只有大家相互配合才能提高开发效率,才能出色完成任务吧,我一直是相信1+1>2的在这种团队协作中。 2、学会了使用新的技术进行团队开发,因为据我了解,公司里面也是采用这套流程的,虽然很难达到公司的规范,但也相当于说是贴近了公司开发的流程。
总的来说我在这个项目里的感悟就是很多时候,技术的好坏并不能决定最终项目的成果,我们身在一个团队当中,我们是团队的一员。在一个团队中如果某个人非常的出色,可能只能将他负责的这块做好,而只有将个人融入到集体中,才能得到一个比较完美的结果。
**二、**我的第二个项目这个多功能音乐播放器,实际上是有点像网易云音乐的一个播放器吧,因为我本身就是个老网易云了,所以就想实现一个自己喜欢的项目,因为我最初学习前端的一个初心就是喜欢前端。
在这个项目里我遇到的最大的困难: 1、首先我在自我定位上出了些问题,因为我是以用户的眼光去代入这个项目,所以我在开发时过多的将自己的角色融入到产品经理所要做的这块上去了,而不是一个前端。所以有时候我在没做出自己想要的需求的时候,会很沮丧。 解决方法: 1、认清自己的定位,用前端的角度去看待问题 2、询问我的小伙伴们,听取他人的意见 3、在我感到沮丧的时候我会通过健身、篮球等方式缓解内心,这也是我遇到挫折时的一个解决方法吧 学到了:(更多偏向思想层面的东西) 1、摆正自己的定位,认真做好前端该做的事情,不要眼高较低 2、面对挫折时其实有很多解决方法都非常有效,对于我来说,真的去运动可以宣泄掉一些负面的情绪,这也是我个人快速自我调节的方法 3、就是在项目开发过程中由于是单人独自开发,让我的代码变得比之前更加的缜密
你的职业规划是什么?
Tips:这个回答要点是具体化,有可执行的计划。条理逻辑清晰,不要听起来像满嘴跑火车。
我要3~5年内继续完善自己的技术,这期间会继续学习Python,机器学习,深度学习的内容,同时也会涉猎其余的编程语言。
首先这个问题我有去思考过,也是根据自身情况做了一些自己的打算 第一,在我的职业规划中我是不打算考研的,首先我选择的前端岗位,我很喜欢前端,而据我了解研究生很少有会在前端领域钻研的,所以我觉得相比于个人能力的提升的话就业是高于研究生的。其次我个人认为考研是去深造去学习的,如果只是单纯的为了逃避就业的话我认为是没必要考研的。所以在我的职业规划中首先我是不打算考研的 第二,在技术方面(完善自身的技术),我打算在未来的三年中还是主要以前端知识的学习为主,继续学习像react,ts,vite等一些知识,争取做到能将一些知识融合起来,串联起来。同时我也会涉猎其他的编程语言像java等,但只是做一些了解,了解这些语言的原因是为了更好的适应公司开发 第三,在工作方面,积极完成工作任务,积累各方面的经验,希望让自己从一个前端小白,成为这个领域的专业人士(高级前端,资深前端把),5年时间,蛮有挑战的。也希望有机会能够带领团队去做项目,去成为一个项目的管理者,为单位做出更大贡献,获得双赢。 最后,我想说的是学无止境吧,我未来的5年里我肯定会不断努力不断进步
你对钉钉的了解
1、无感==》2、感染==》3、感动 我第一次接触钉钉是在3年前,大一的时候,那时候当了班委,学校有一个学生工作的管理群就是统一是采用钉钉管理的,所以那时候我第一次使用到了钉钉,这也算是和钉钉的初次邂逅吧。 到后来我立志入党,在大一到到三这段入党历程中,我的各种党政学习课采用的都是钉钉授课的方式,这也是我们学校一贯的传统。这时候钉钉给我的感觉是一种感染,但我觉得我还是没有了解更多关于钉钉的东西 到了大概二月份左右我看到了钉钉春招的海报,因为我个人最向往的公司就是阿里,所以我毅然决然的投了,在我从一面到现在大概已经快半个月了,我其实真的感受到了很多,无论是从面试体验还是面试官内推人的负责程度上,都是我所有
钉钉:钉钉的功能覆盖面广,应用数量众多,可以满足中小型公司一站式办公的需求,特别是在IM模块,钉钉开发了密聊功能,聊天记录禁止截图禁止转发,增强了数据的安全性。 钉钉消息直通车中,将@我的信息、特别关注、稍后处理、红包和文件5种消息加以区分,加上原本的Ding消息,做到了对消息紧急重要程度的区分,同时消息的自定义分组也可以帮助用户根据消息来源不同分类筛选,结合其不同程度的消息提醒方式,保证用户集中精力处理重要消息,从而提高消息的处理效率。
企业微信:与飞书和钉钉不同,企业微信的基础IM模块无论从功能到交互都与微信非常相似,这使得用户上手成本较低,体验较好。企业微信的消息提醒方式很弱,同时“休息一下”这个功能也可以看出其人文关怀。 与微信的连接是企业微信的特色,企业微信可以连接小程序,添加微信用户、微信群、发送客户朋友圈等,为企业提供客户运营管理的便捷。 不同以上述两个产品,企业微信的协作模块功能入口分散,日程管理功能和文件协作、云盘功能分散在聊天界面的快捷操作中,属于次级界面,用户教育成本较高,同时这些功能也作为一个个应用分布在工作台,企业微信缺乏整体性较强的协作方案,功能之间独立性较强,很难发生联动。
你认为自己的优势是什么?
1、相比于研究生来说,我虽然学历上与他们有差距,但我觉得自己还是有优势的。首先我的第一轮面试大概是2小时20分钟,第二轮面试大概是1小时10分钟吧,在这三小时的时间中我在技术知识的考核上得到了面试官的认可,也就是我可以主观的认为我在技术掌握层面已经不输于大部分的研究生了,而且相比于他们我更加年轻,年轻就是资本哈哈。此外研究生是有做过学校的科研项目,而我也有参加本科生科研项目叫SRTP,这个项目其实就是对标研究生项目实践流程,我目前是一个校级项目的负责人,一个省级项目的成员。所以我认为自己也算是懂一些些科研流程吧。
2、相比于科班同学,我有去了解过,目前国内高校是没有专门开设前端这样的课程的,所以不管是科班还是非科班大家学习前端都是靠着自学的,我也是通过自学来学习前端的,而且据我了解有些科班的同学是从事后端或其他领域开发的然后转前端,因为前端目前来看我认为竞争没java那么激烈,所以这样竞争力会高些。而我个人是完全按照前端体系进行一个学习,也就是我不会去遗漏掉前端的基础知识吧。我对自己前端知识方面的掌握还是有蛮大的自信的。除此之外我也自学了算法以及像操作系统计算机网络这些计算机基础知识,并且在面试中也是得到面试官的认可了吧
3、我是非常喜欢前端这份工作的,算是一种热情吧。我个人的性格也是这样,对于喜欢的人,喜欢的事情,喜欢的工作等会保持很高的热情,我觉得我自己喜欢的事情其实我都能玩出些名堂来了。我自学前端是从去年4月份开始的,到现在大概11个月左右吧,也正是这种热情促使我不断进步。
4、我并非是独自一人学习的,在学习路上有人相互督促
