

什么是RabbitMQ?
RabbitMQ是一个消息排队软件,也被称为消息代理或队列管理器。它支持诸如AMQP、MQTT和STOMP等协议,仅举几例。RabbitMQ可用于长期运行的任务,例如后台作业,并用于不同服务之间的通信。
RabbitMQ 是如何工作的?
描述 RabbitMQ 的最简单的类比是邮局和从头到尾涉及的必要步骤,以便将邮件送到最终目的地。在现实生活中,这些步骤包括将邮件投进邮箱,然后在幕后进行一些处理,以确定邮件的路径,最后由邮递员将邮件送到目的地。
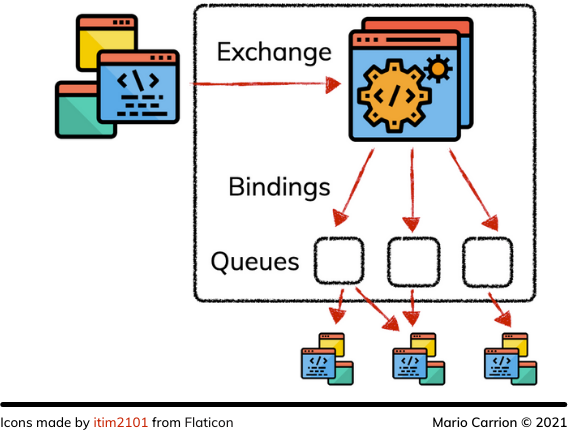
RabbitMQ 作为一个队列工作,发布者可以提交消息,然后最终被多个消费者消费;但是 RabbitMQ 的有趣部分是位于这些发布者和消费者之间的中介机制。这个中介被称为Exchange,这个 Exchange 可以被配置为定义绑定,以允许这些消息被路由到不同的队列中,然后客户端可以监听以不同的方式消费消息,也许可以通过一个唯一的具体密钥或通配符来消费。
使用存储库实现发布者
为了与RabbitMQ交互,我们将使用包 streadway/amqp并与其他数据存储类似,我们将定义一个Repository,它将与实际的 RabbitMQ 发布者进行交互,并将在service 类型中调用。
该资源库类型将被命名为rabbitmq.Task,它将包含一个引用 RabbitMQ 通道的未导出字段以及发射三个事件所需的相应方法Created 、Deleted 和Updated 。
func (t *Task) Created(ctx context.Context, task internal.Task) error {
return t.publish(ctx, "Task.Created", "tasks.event.created", task)
}
func (t *Task) Deleted(ctx context.Context, id string) error {
return t.publish(ctx, "Task.Deleted", "tasks.event.deleted", id)
}
func (t *Task) Updated(ctx context.Context, task internal.Task) error {
return t.publish(ctx, "Task.Updated", "tasks.event.updated", task)
}
这三个方法将引用一个名为publish 的未导出的方法,该方法用于发布数据,该数据是使用encoding/gob 包对消息进行编码的结果,类似于我们讨论使用 Memcached 缓存时使用的代码。
func (t *Task) publish(ctx context.Context, spanName, routingKey string, e interface{}) error {
// XXX: Excluding OpenTelemetry and error checking for simplicity
var b bytes.Buffer
_ = gob.NewEncoder(&b).Encode(e)
_ = t.ch.Publish(
"tasks", // exchange
routingKey, // routing key
false, // mandatory
false, // immediate
amqp.Publishing{
AppId: "tasks-rest-server",
ContentType: "application/x-encoding-gob",
Body: b.Bytes(),
Timestamp: time.Now(),
})
return nil
}
接下来,在service 包中的 service.Task类型被更新以使用接口类型接收该存储库的实例,然后在持久化数据存储调用完成后使用它,类似于。
func (t *Task) Create(ctx context.Context, description string, priority internal.Priority, dates internal.Dates) (internal.Task, error) {
// XXX: Excluding OpenTelemetry and error checking for simplicity
task, _ := t.repo.Create(ctx, description, priority, dates)
_ = t.msgBroker.Created(ctx, task)
return task, nil
}
请参考Delete 调用以及Update 调用,以了解更多细节,实际上,代码与上面的代码相似。
现在,让我们来看看订阅者的实现。在这个例子中,我们将实现一个新的运行进程,负责消费这些数据。
订阅者实现
这个新的进程将消费那些RabbitMQ事件,以正确索引任务记录,改变我们最初使用Elasticsearch的方式,它还将支持像我们之前所涉及的Graceful shutdown。
目前,用于监听的代码是一个稍长的方法,重要的部分将是RabbitMQ返回的实际Go通道,这段代码做了如下事情来接收所有事件。
// XXX: Excluding some things for simplicity, please refer to the original code
for msg := range msgs {
switch msg.RoutingKey {
case "tasks.event.updated", "tasks.event.created":
// decode received Task event
// call Elasticsearch to index record
case "tasks.event.deleted":
// decode received Task event
// call Elasticsearch to delete record
}
// acknowledege received event
}
在现实生活中,您应该考虑实现一个能够处理不同事件的服务器类型,也许类似于net/http.Server 的工作方式,也许可以定义类似于 Muxer 的东西,以允许监听具有相应编码/解码逻辑的多个事件。
总结
RabbitMQ通常被称为分布式队列,但它也可被用作消息代理来通信多个服务,它是一个强大的工具,由于有可用的配置选项,它可用于向多个客户端大规模地传递消息。
