

这是我参与「第四届青训营 」笔记创作活动的第6天
1 YARN概述
从餐厅分配座位场景导入,初试调度系统;介绍调度系统的演进过程;Hadoop YARN 的设计思想和整体架构
1.1 初识调度系统
场景导入
- 学校为改善学生生活新建了一所美食餐厅,餐厅座位有限且只能堂食
- 各学院需缴纳一定管理费用后学生才能在该餐厅用餐,缴纳费用与分配的座位数成正比
- 因餐厅物美价廉、环境干净,来该餐厅就餐的人络绎不绝
如何进行高效座位分配在保障就餐公平性的前提下让尽可能多的学生都能够及时 就餐、尽可能多的座位被有效使用?
简易分配模型
- 学院:缴纳费用后获得固定座位数
- 学生:按照学院组织,学院内的用餐小组**按照预定时间排队,每个小组有一个负责人
- 餐厅经理:(两个备用经理)对所有学院按照分配座位满足率由低到高排序,优先选择靠前学院进行餐位派发
- 餐厅经理选择一个学院后,基于餐厅座位情况,以 FIFO方式选择用餐小组并分配桌号
- 用餐小组在餐厅经理助手引导下到特定位置进行就餐,用餐小组负责人安排组内成员就坐
- 用餐结束后,用餐小组负责人向餐厅助手说明
-
保障公平性
- 学院间按照分配座位满足率排序;
- 学院内FIFO;
-
保障高效性
- 餐厅经理有很多助手以辅助其派发,助理可以统计就餐信息、学院排序、引导等;餐厅经理做决策,助手异步同步信息;
- 用餐小组负责人
-
保障高可用
- 两个备用经理,随时可以工作;
-
如何满足 “尽可能多”?
- 座位超售:所有学院分配座位大于总座位数
- 学院超用:有座位时学院可以超分配座位
- 座位超发:“允许一个座位坐两个人”
- 鼓励快餐:鼓励大家快速就餐离开
-
就餐学生有个性化需求
- 同用餐小组必须坐一个桌子
- 同用餐小组必须坐不同桌子
- 用餐小组必须要坐靠窗位置
- 有重要活动同学需靠前就餐
1.2 调度系统的演进
调度系统发展的背景
- IT到DT时代的变革,注重数据价值
- 数据计算方式的变革,注重计算效率
- 企业对外服务需数以万计的硬件资源
- 灵活调度、提高利用率是降本增效的关键问题
调度系统解决的问题
- 用有限资源解决有限资源无法满足的需求时就需要调度
- 主要解决资源请求和可用资源的*映射(Mapping) *问题,也就是将负载的资源请求与当前计算集群中的可用物理资源通过一定的调度策略进行匹配(Matching)。
调度系统预达的目标
- 严格的多租户间公平、容量保障
- 调度过程的高吞吐与低延迟
- 高可靠性与高可用性保障
- 高可扩展的调度策略
- 高集群整体物理利用率
- 满足上层任务的个性化调度需求
- 任务持续、高效、稳定运行
- We want to have all of them… However…
调度系统设计的基本问题
-
资源异质性和工作负载异质性
- 异质性大白话说就是不一样,种类多
- 机器硬件配置和计算存储资源都存在较大差异,很难保证采用完全相同的配置,目前主要通过将资源分配单位细粒度划分以及虚拟化技术来解决
- 工作负载异质性是从系统提交的任务角度来看的,负载类型多样化(流处理、批处理、内存计算、在线服务等),任务偏好多样化和动态化(任务的约束条件、运行过程中资源使用动态变化),资源需求多样化(CPU,内存,GPU,IO等)
-
数据局部性
- 大数据场景下因为数据传输开销要远大于计算逻辑传输开销,因此往往将计算任务推送到数据存储所在地进行,这种设计哲学一般被称为数据局部性问题。在资源管理与调度语境下一般存在3种类型数据局部性:节点局部性,机架局部性和全局局部性。节点局部性完成计算不需要进行数据传输,机架局部性需要在机架之间进行数据传输存在一定开销,其它情况则属于全局局部性需要跨机架进行网络传输进而产生较大的网络传输开销,因此最优的方式是尽可能保证节点局部性。
-
抢占式和非抢占式调度
- 强调高优先级任务执行效率的调度策略会采用抢占式调度,强调资源公平分配的调度会采用非抢占式调度。
-
资源分配粒度
- 大数据场景下的计算任务往往呈现层级结构,例如:作业级(Job)-任务级(Task)-实例级(Instance),从计算任务视角来看,此时资源调度系统就面临资源分配粒度问题,资源分配粒度主要存在三种方式:(1)群体分配策略(Gang Scheduler),即要么全满足要么全不满足,Flink和MPI任务依赖这种方式;(2)增量满足式分配策略,只要分配部分资源就可以启动运行,MR采用这种方式;(3)资源储备策略,资源达到一定量才能启动作业,在未获得足够资源时作业可以先持有目前已经分配的资源并等待其他作业释放资源,调度系统不断获取新资源并进行储备和积累,直到分配到的资源量达到最低标准后开始运行,在作业启动前已经分配的资源处于闲置状态。
-
饿死与死锁问题
- 有死锁一定有饿死,有饿死不一定有死锁
-
资源隔离方法
- 为了减少任务之间的干扰需要进行一定的隔离措施,LXC是一种轻量级的内核虚拟化技术,LXC在资源管理方面依赖于 Linux 内核的 cgroups 子系统,cgroups 子系统是 Linux 内核提供的一个基于进程组的资源管理框架,可以为特定的进程组限定可以使用的资源。其他技术有Intel RDT。
调度系统泛型
-
集中式调度系统
-
产生背景:该调度系统是大规模数据分析和云计算出现的雏形,主要进行大规模的集群管理以提高数据处理能力。
-
基本原理:中心式调度系统融合了资源管理和任务调度,有一个中心式的 JobTracker 负责进行集群资源的合理分配、任务的统一调度、集群计算节点信息的统计维护、任务执行过程中的状态管理等。
-
优点:
- JobTracker 能够感知集群中所有资源和任务的执行状态,能够进行全局最优的资源分配和调度,避免任务间的干扰,适当进行任务抢占,保证任务计算效率和服务质量;
- 架构模型简单,只有一个全局的管理者负责进行所有管理。
-
缺点:
- JobTracker 作为集群的中心,存在单点瓶颈问题,不能支持大规模集群;
- 内部实现异常复杂,一个调度器中需要实现所有的功能模块,可扩展性差;
- 负载变更会导致系统需要进行不断的迭代,这将增加系统的复杂性,不利于后期的维护和扩展;
- 只支持单类型的任务,MR 类型的批处理任务;
-
典型的调度系统:Hadoop1.*版本;K8S中的kube-scheduler,Quasar。
-
-
两层调度系统
-
产生背景:为了解决集中式调度系统的扩展性问题,系统实现复杂,可扩展性差,不能支持不同类型任务等缺点。
-
实现原理:将资源管理和任务调度解耦。集群资源管理器负责维护集群中的资源信息并将资源分配给具体的任务,任务管理器负责申请资源并将申请到的资源根据用户逻辑进行细分和具体的任务调度。
-
优点:
- 资源管理器只负责资源分配,任务调度由应用完成,提高了系统的扩展性;
- 任务调度逻辑由具体的任务完成,能够提供对不同类型任务的支持;
- 内部实现模块化,利于维护和扩展;
-
缺点:
- 任务无法感知全局的资源情况,只能基于request/offer来进行资源获取,无法有效避免异构负载之间的性能干扰问题;
- 任务调度和资源管理解耦不利于实现多任务间的优先级抢占;
- 所有任务的资源请求都需要资源管理器进行处理,此外其还需要与节点管理器之间维持通信,导致资源管理器存在单点问题;
-
典型系统:Mesos,YARN,Fuxi
-
-
共享状态调度系统
-
产生背景:前面的调度器存在一个问题就是计算框架在进行资源申请的时候无法获知到集群的全局资源信息,这就导致无法进行全局最优的调度,共享状态调度器就提供了这个问题的一种解决方式。
-
基本原理:是一个半分布式的架构,通过共享集群状态为应用提供全局的资源视图,并采用乐观并发机制进行资源申请和释放,来提高系统的并发度。
-
优点:
- 支持全局最优调度;
- 能够一定程度的提高并发度;
-
缺点:
- 高并发资源请求下会造成频繁的资源竞争;
- 不利于资源分配的公平性;
- 资源全局副本维护模块存在单点瓶颈;
-
典型系统:Omega
-
-
分布式调度系统
-
产生背景:提高系统吞吐率和并发度
-
基本原理:分布式调度器之间没有通讯协作,每个分布式调度器根据自己最少的先验知识进行最快的决策,每个调度器单独响应任务,总体的执行计划与资源分配服从统计意义。
-
优点:提高吞吐量和并发度
-
缺点:
- 调度质量得不到保障;
- 资源非公平分配;
- 不能支持多租户管理;
- 不能避免不同任务之间的性能干扰;
-
典型系统:Sparrow
-
-
混合式调度系统
-
产生背景:针对一些特定的混合任务调度场景,某些任务需要比较快的调度响应,而其他任务不需要很快的调度响应,但是需要保证调度质量。
-
基本原理:设计两条资源请求和任务调度路径,保留两层调度的优点,同时兼顾分布式调度器的优势。对于没有资源偏好且响应要求高的任务采用分布式调度器,对于资源调度质量要求较高的采用集中式资源管理器进行资源分配。
-
优点:
- 能够针对不同类型的任务进行不同方式的调度;
- 为应用层提供灵活的接口和性能保障;
-
缺点:复杂化了计算框架层的业务逻辑;调度系统内部也需要针对两种不同的调度器进行协同处理;
-
典型调度系统:Mercury:微软的混合调度机制,中心式调度器对调度质量要求较高的作业进行公平的资源分配,分布式调度器对时间敏感和吞吐率要求高的作业进行调度。
-
1.3 YARN 设计思想
演化背景
Hadoop 1.0 时代:由分布式存储系统 HDFS 和分布式计算框架 MapReduce(MR v1) 组成,MR v1 存在很多局限:
- 可扩展性差:JobTracker 兼备资源管理和任务控制,是系统最大的瓶颈
- 可靠性差:采用 master/slave 结构,master 存在单点故障问题
- 资源利用率低:基于槽位的资源分配模型,各槽位间资源使用差异大
- 无法支持多种计算框架:只支持 MR 任务,无法支持其他计算框架
Hadoop 2.0 时代:
- YARN(MR v2) 在 MR v1 的基础上发展而来,将资源管理和任务控制解耦,分别由 Resource Manager 和 ApplicationMaster 负责,是一个两层调度系统
- Hadoop YARN(Yet Another Resource Negotiator) 支持多种计算框架的统一资源管理平台
离线调度生态
- 用户逻辑层:数据分析任务、模型训练任务等
- 作业托管层:管理各种类型上层任务
- 分布式计算引擎层:各种针对不同使用场景的计算引擎,例如:MR、Spark、Flink 等
- 集群资源管理层:YARN
- 裸金属层:众多物理节点组成
面临的挑战
- 公平性:各租户能够公平的拿到资源运行任务
- 高性能:高调度吞吐、低调度延迟,保障资源快速流转
- 高可用:集群要具备很强的容错能力
- 大规模:单集群规模提升(原生 YARN 单集群仅支持 5K节点)
- 高集群资源利用率
- 高任务运行质量保障
系统架构
上图为YARN架构,最上面是User Code,用户基于不同计算引擎写一些自己的业务逻辑提交给YARN Client执行,白色框里是YARN的两大核心:
-
Resource Manager
- 整个集群的大脑,负责为应用调度资源,管理应用生命周期;
- 对用户提供接口,包括命令行接口,API, WebUI 接口;
- 可以同时存在多个RM、,同一时间只有一个在工作,RM 之间通过 ZK 选主;
-
Node Manager
- 为整个集群提供资源, 管理 Container 运行;
- 管理Contianer的运行时生命周期, 包括Localization, 资源隔离, 日志聚合等;
任务运行生命周期核心流程
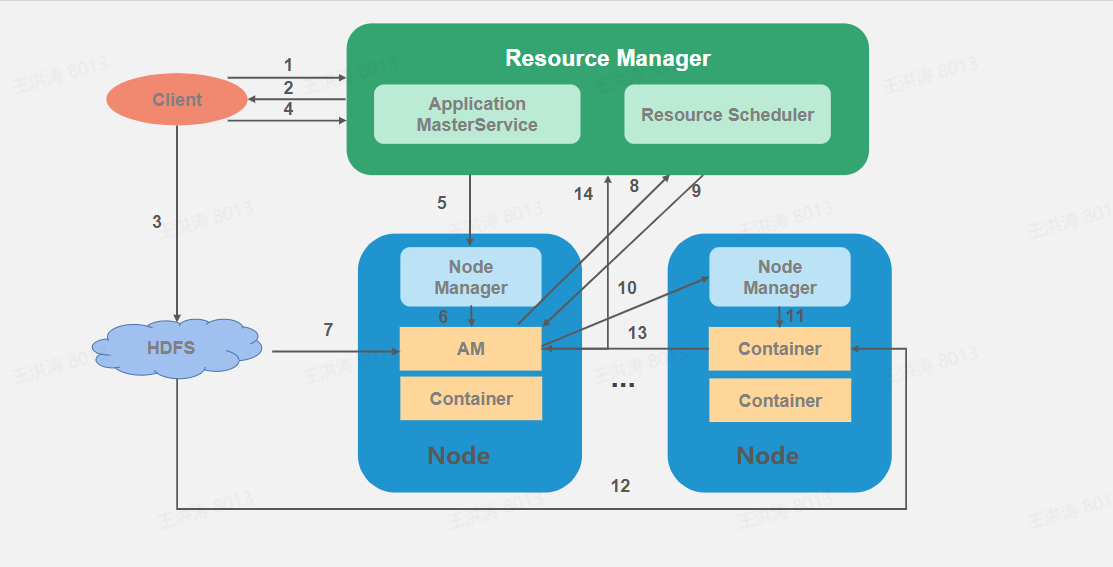
- Client端提交请求给RM
- RM 返回 GetNewApplicationResponse,其中主要包括:ApplicationID、最大可申请资源以及相关配置
- Client 将任务运行所需的资源上传至HDFS的指定目录下,并初始化AM配置,主要构造 ApplicationSubmissionContext (应用ID、应用名称、所属队列、应用优先级、应用类型、应用尝试次数、运行AM所需要的资源等)和 ContainerLaunchContext(容器运行所需的本地资源、容器持有的安全令牌、应用自有的数据、使用的环境变量、启动容器的命令行等)。
- Client 将 AM 提交至 RM,调用 ApplicationClientProtocol #submitApplication。
- RM 根据一定的分配策略为 AM 分配container,并与 NM 通信。
- NM 启动 AM。
- AM 从 HDFS 下载本任务运行所需要的资源并进行初始化工作。
- AM 向 RM 注册和申请资源。ApplicationMasterProtocol # registerApplicationMaster,注册信息包括:AM所在节点的主机名、AM的对外RPC服务端口和跟踪应用状态的Web接口;ApplicationMasterProtocol # allocate,相关信息封装在 AllocateRequest中包括:响应ID、申请的资源列表、AM主动释放的容器列表、资源黑名单、应用运行进度。
- RM 接受 AM 请求后,按照调度算法分配全部或部分申请的资源给 AM,返回一个 AllocateResponse 对象,其中包括:响应ID、分配的container列表、已完成的container状态列表、状态被更新过的节点列表、资源抢占信息(强制收回部分和可自主调配部分)等。
- AM 获取到资源后与对应的 NM 通信以启动 container, ContainerManagementProtocol # startContainers
- NM 启动container。
- Container 从 HDFS 下载任务运行必要的资源。
- Container 在运行过程中与AM通信及时汇报运行情况。
- 任务运行完成后 AM 向 RM 注销,ApplicationMasterProtocol # finishApplicationMaster()。
