

各位朋友,大家好!
在现场工程团队这里,我们经常被问及追踪问题。有两个问题是经常出现的。*我需要对我的跟踪进行采样吗?以及我如何对我的跟踪进行采样?*问这个问题的人通常是在使用追踪商店,根本不可能储存所有正在产生的追踪。
这些都是很好的问题,答案取决于一些不同的因素。
Grafana Tempo、Grafana Cloud Traces和Grafana Enterprise Traces是高度可扩展的、具有成本效益的解决方案,专门用于存储您的基础设施和应用程序中的所有痕迹,完全不需要取样!它们不仅给用户带来巨大的好处,而且还能为您的应用程序带来巨大的好处。它们不仅给那些想立即观察数据现在是如何在他们的服务中流动的用户带来了巨大的好处,而且还帮助那些可能想回到上周或几周前的工程师和SRE,将历史痕迹与当前状态的痕迹进行比较。这使他们能够找到潜在的优化以及数据流的瓶颈。
然而,有些时候,你不需要所有的跟踪。这可能是因为你对通过你的系统的特定请求不感兴趣,比如那些持续时间小于任意时间的请求;没有导致错误的请求;或者甚至是进入某个特定端点的请求,你根本不关心。
正因为如此,一个组织应该问几个问题来确定他们是否需要取样:
- 是否有充分的理由不存储我们所有的痕迹?
- 如果我们不发送所有的痕迹,我们可能会错过什么?
- 在我们的系统或基础设施中,是否有一些部分是我们从来不需要追踪的?
- 是否有一些我们根本不关心的追踪类型?
如果这些问题的答案都是 "是",那么你可能想进行某种形式的跟踪采样。
当然,还有一个更基本的问题,你可能有。到底 什么是跟踪采样?
尾随采样的介绍
当一个程序被追踪SDK(如OpenTelemetrySDK)检测到时,它发出的跨度就构成了一个单独的追踪。通常情况下,跟踪是基于进入系统的单个独特请求,然后在响应被送回请求者之前被处理。这允许单独观察正在接收的每一个请求,这对发现错误、延迟和其他影响用户的因素非常有帮助。
例如,如果你一秒钟有一个请求,这相当于每分钟60个请求或每天86400个请求。这......不是很多的请求。如果我们考虑一个SaaS解决方案,它可能包括20个单独的微服务,每个服务有几个跨度,每个跨度大约是300字节,最后每个跟踪大约有40个跨度,每个跨度300字节--或每个跟踪12KB。所以在一天的时间里,你需要大约1GB的跟踪存储。
好吧,一天1GB并不算多。你可以很容易地存储和查看这些痕迹。然而,如果你每天只收到86,400个请求,那么可能会发生非常关键的事情。你会倒闭,因为你没有足够的客户。
大多数常见的SaaS解决方案每秒都会收到数万或数十万,甚至数百万的请求。一万二千字节(单个跟踪)乘以一百万,乘以60x60x24,这个数字大到我甚至不打算把它放进我的计算器。要实际处理这么多的跟踪并存储它们,不仅在CPU和内存资源方面,而且在存储方面也变得很昂贵。
正因为如此,今天很多追踪解决方案都使用某种类型的抽样来减少传输和存储追踪的负担。这可以采取的形式是,在一定数量的跟踪中只捕获一个,比如,100个中有一个,这被称为概率或随机 采样。这背后的理论是,在如此多的痕迹被发射出来的情况下,只对其中的一小部分进行抽样,仍能确保你看到与你有关的痕迹,例如抛出错误的请求,或某个最小持续时间。
很多解决方案比这更聪明,实际上使用了更先进的采样。他们采用技术来检测异常情况和与他们所看到的 "正常 "痕迹的偏差,以确保异常值被捕获和存储。虽然这样做效果不错,但有时也会漏掉一些重要的痕迹,这也是我们Grafana实验室认为捕捉所有痕迹很重要的原因之一。
头部采样与尾部采样
采样通常有两种不同的形式:
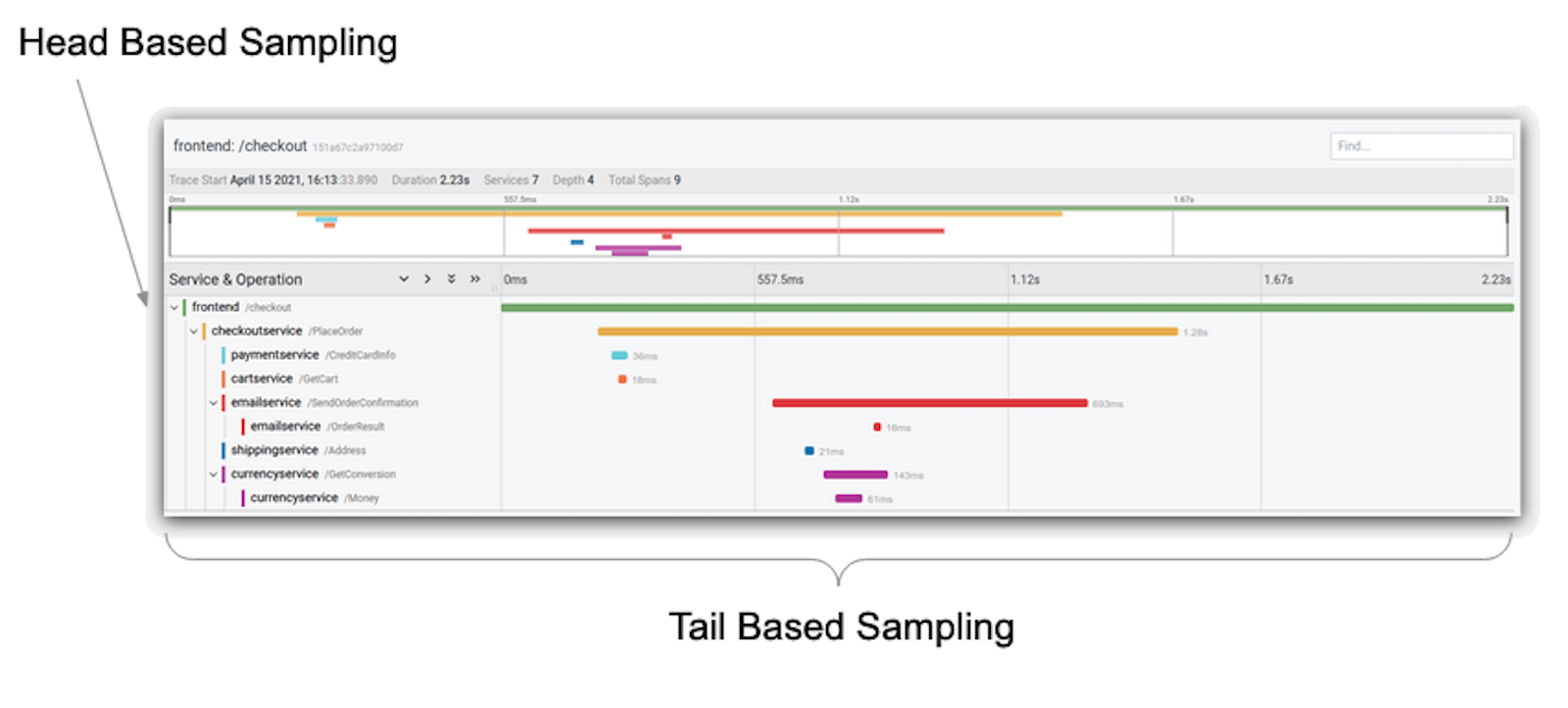
头部取样通常发生在一个仪器化的应用程序中。这种类型的采样决定了是否应该在其生命周期的早期捕获一个跟踪。例如,想象一下,你有健康检查端点,对任何请求只返回 "ALIVE!"。这可能不是你真正关心的代码。(这是一个谎言--你关心它,但鉴于它可能不是一个非常复杂的功能。你只是想确保它能工作,而不是追踪它)。
当一个新的跟踪由于对该端点的请求而被创建时,你可以在你的端点处理程序中写一些代码,指示跟踪仪器不继续跟踪。没有任何跨度将被发送到你使用的任何跟踪商店,为该跟踪创建的任何进一步跨度将被忽略。追踪的头部已经决定忽略它,不管是否有进一步的跨度。
你可能已经猜到了,尾部采样发生在跟踪的末端--也就是说,当一个跟踪的所有跨度都被发射出去并且跟踪结束时。这种情况通常不会发生在应用工具中,因为微服务的复杂性意味着追踪可能会在追踪开始时的下游服务中完成。相反,尾部采样通常发生在跟踪存储的后端,或者更常见的是在本地运行的代理或跟踪收集器在你的应用程序基础设施中运行。
因为尾部采样会等到跟踪的所有跨度都被收到,它可以根据整个跟踪做出决定。根据一个跟踪的所有跨度,它将只存储在任何被存储的跨度中表现出错误的跟踪;有最小持续时间的跟踪;甚至是跨度包括特定标签和属性的跟踪。它甚至还可以做简单的随机抽样。
也就是说,尽管尾部抽样比头部抽样灵活得多,但它也更耗费资源,因为它需要通过一个跟踪的所有跨度来应用所需类型的抽样逻辑。因此,它应该少用。
使用Grafana Agent进行尾部采样
在这一点上,你可能对是否需要进行采样以及采样的内容有了很好的了解。所以你的下一个问题可能是。在向Grafana Tempo、Grafana Enterprise Traces或Grafana Cloud Traces发送追踪之前,你能进行采样吗?
是的!
Grafana Agent是一个通用的可观察性收集器,可以刮取Prometheus指标,捕获日志,并将其发送到Loki,并从任何Tempo兼容的仪器SDK(例如OpenTelemetry、Jaeger、Zipkin等)接收痕迹。
Grafana Agent还包括很多处理追踪的功能,比如从传入的追踪跨度中发出速率、错误和持续时间(RED)指标;为传入的追踪自动产生日志行;从流行的自动发现中添加标签(如k8s细节);当然还有尾部采样。
因为它符合OpenTelemetry SDK标准,Grafana Agent也包括OpenTelemetry指定的所有尾部采样策略。(你可以在这里找到这些,尽管为了获得支持的采样策略的最新观点,值得看一下这里的代码)。
一些流行的取样策略是:
- 跟踪持续时间
- 跨度标签/属性值
- 带标记错误的跨度
正如我已经指出的,能够进行尾部采样需要跟踪的所有跨度都可用。但是,如果你的服务非常大,而且你正在运行多个Agent,会发生什么?在这种情况下,你可能希望在round-robined(或其他负载平衡)配置中运行Grafana Agent。这意味着特定跟踪的跨度有可能被发送到不同的代理。这很快就会成为一个问题,因为即使这些跨度仍然可以被后端存储(Tempo, GET, Grafana Cloud Traces)合并成一个追踪,它也会阻止尾部采样的发生。
不要害怕!Grafana Agent包括一个配置选项。Grafana代理包括一个配置选项,允许在所有已知代理之间进行负载平衡。它确保跨度总是由一个代理处理,可配置为已知代理的静态列表或通过DNS记录返回代理IP列表(如在无头的Kubernetes服务中)。这允许尾部采样发生,即使有多个代理实例。需要注意的是,这确实需要额外的资源--跨度信息最多可以发送两次,让正确的Agent来处理。
一些工作实例
我已经说得够多了,你可能想知道,"他什么时候能说到好东西?"好吧,请抓紧你的帽子、头发或头皮,因为我们即将深入研究一些有用的例子。
我是一个非常喜欢 "看到它,做到它,记住它 "的人,主要是因为我年事已高,我开始有点像《*2001:太空漫游》*中的戴夫-鲍曼(Dave Bowman)穿越星域一样,开始走神了。
因此,这里的例子是互动的。如果你还没有这些软件,你需要安装:
- Git
- Docker和Docker Compose
一旦你安装了这些工具,克隆git仓库(假设你有一个与Github相关的SSH密钥)。
git clone git+ssh://github.com/grafana/opentelemetry-trace-sampling-blogpost.git
cd opentelemetry-trace-sampling-blogpost
该仓库有一个Docker Compose文件,其中包括:
- Grafana(可视化数据)
- Grafana Tempo(存储和查询痕迹
- Grafana Loki(存储和查询日志)
- Grafana代理(在向Tempo发送追踪数据之前对其进行处理)
- 一个展示跟踪采样的演示应用程序,它。
- 将跟踪数据发送到Grafana Agent
- 将日志直接发送到Loki(我们可以使用Docker驱动,但它可以节省额外的复杂性,让我们轻松地添加一些标签)
你可以通过使用标准的Docker Compose功能从你的命令行启动项目:
docker-compose up
已经预先提供了两个数据源。Tempo和Loki。Loki包含来自演示应用程序的日志输出--包括跟踪ID--而Tempo正在存储跟踪。在开始的时候,所有从演示程序发出的痕迹都被存储起来。我们可以通过进入Grafana的 "探索 "页面并查看所有的日志来快速验证这一点:
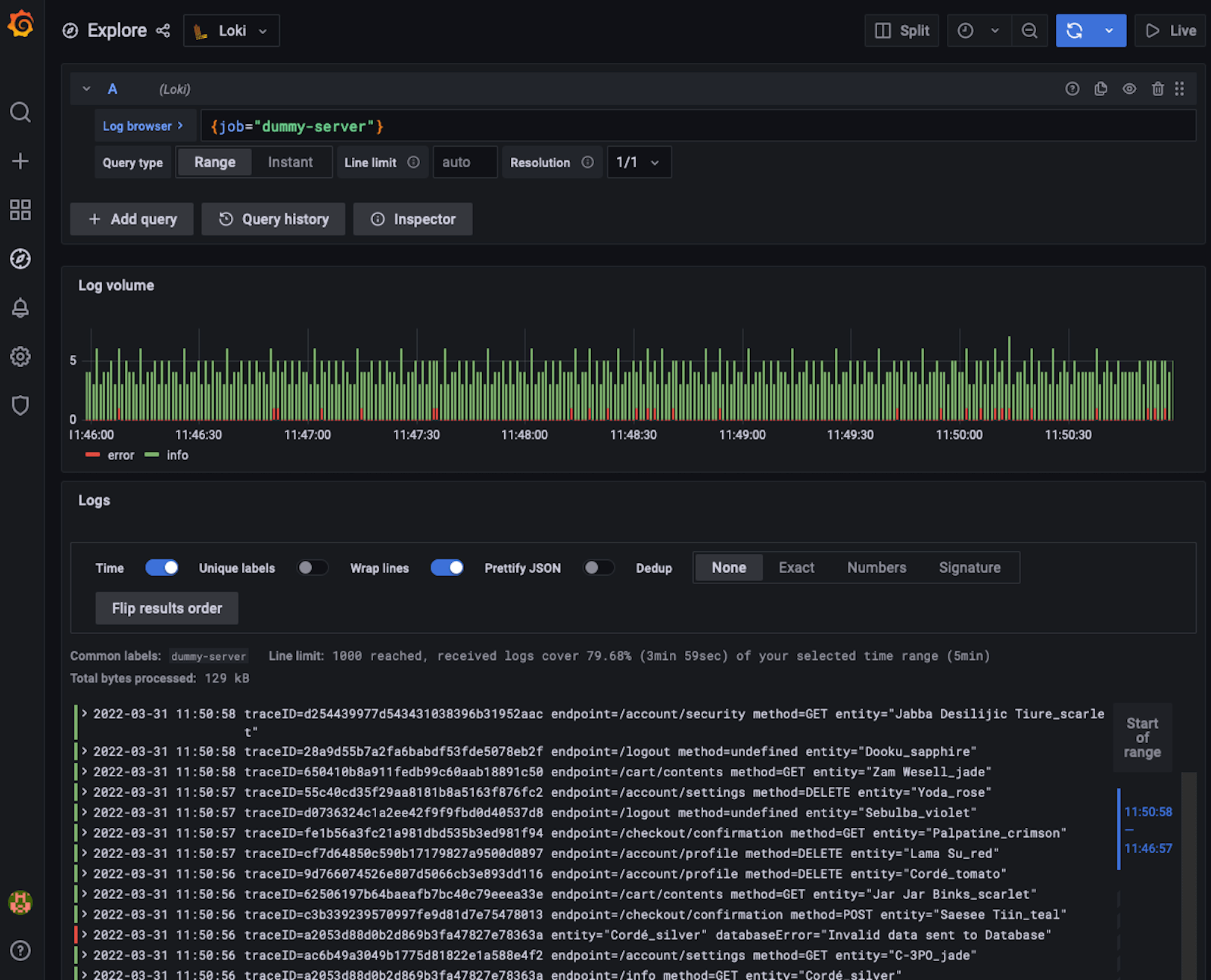
让我们通过扩展一些日志线来看看一些痕迹:
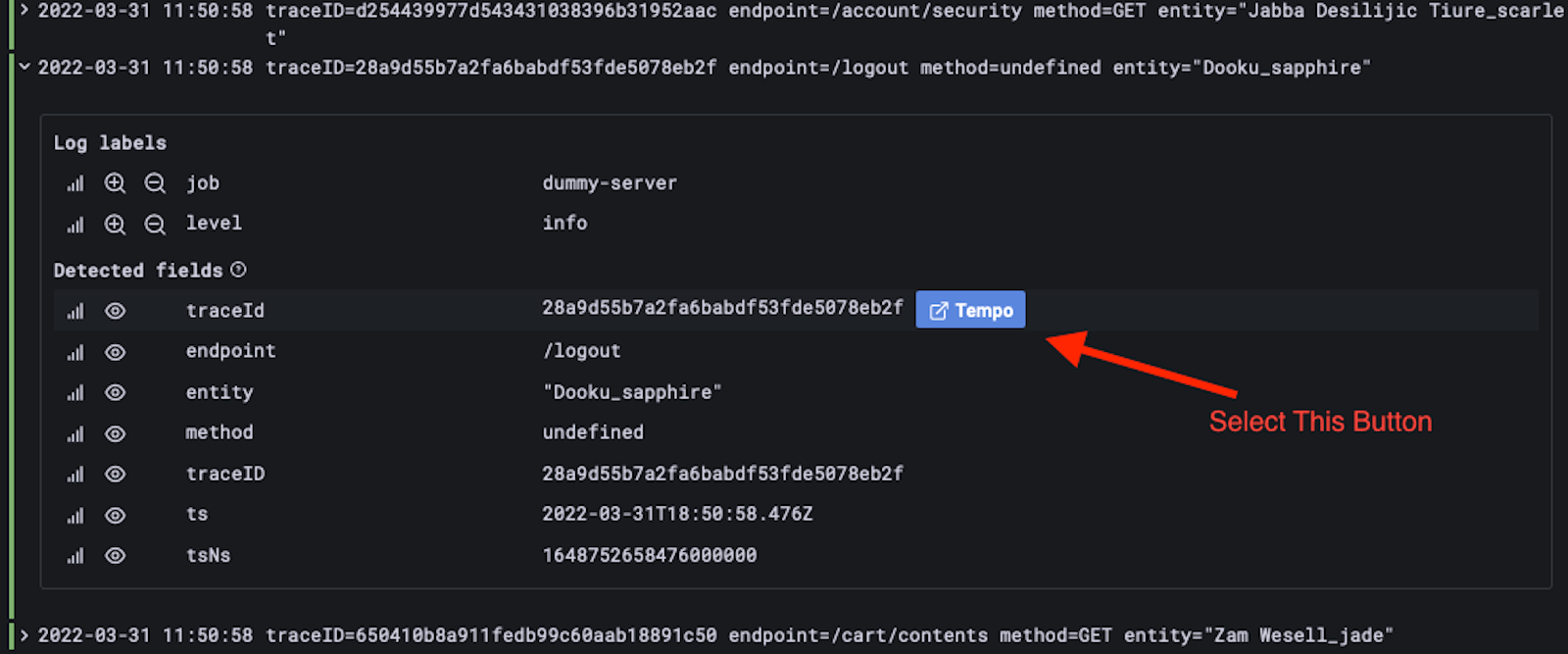
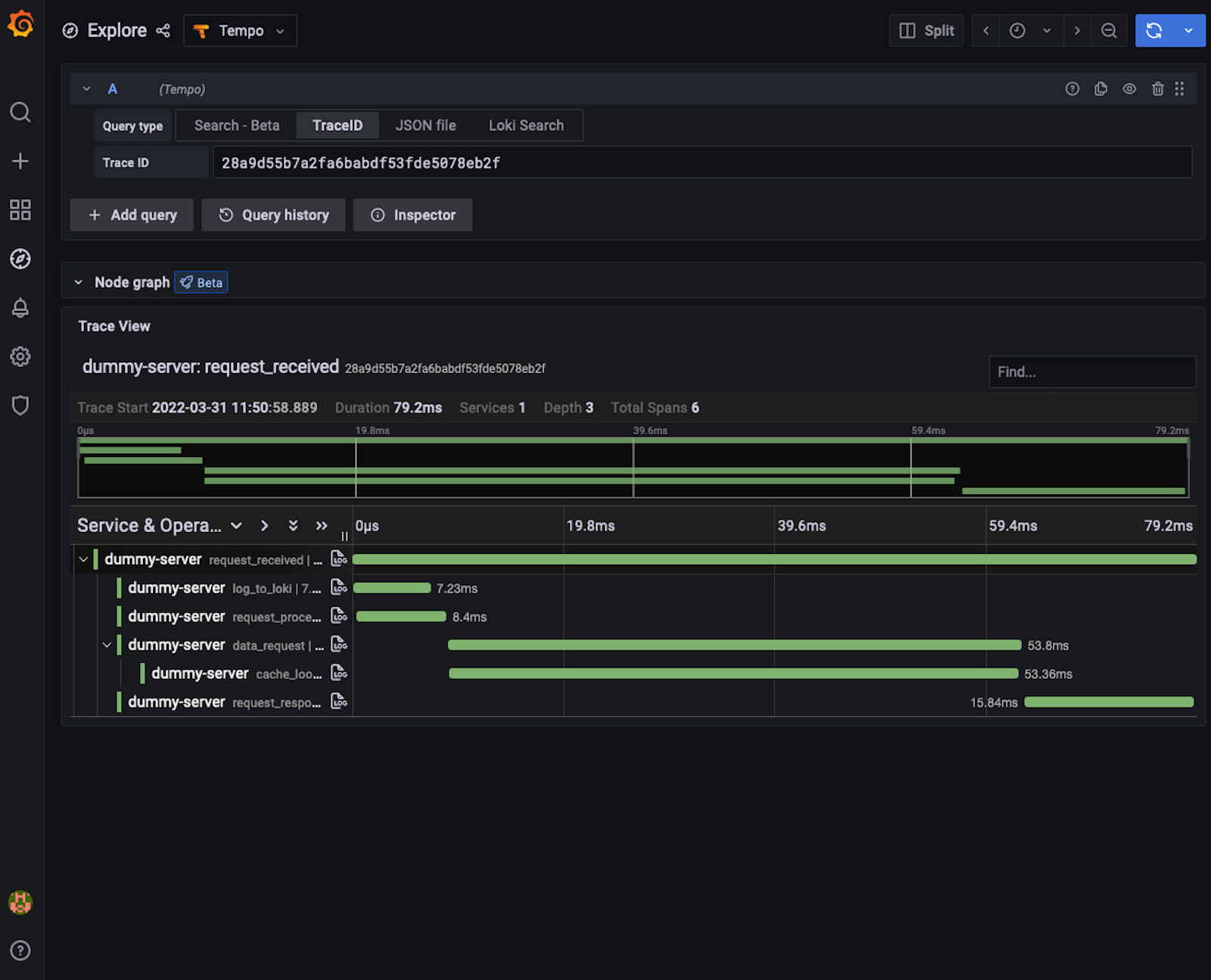
我不打算在这里讨论痕迹是如何被可视化的,因为有很多博文详细介绍了用Grafana进行追踪的情况。
目前,我们的应用程序的所有痕迹都被捕获。因为我们使用Grafana Agent来整理和批处理痕迹,然后再把它们发送到Tempo上,所以配置Agent来捕获它们并远程写入后端非常简单。
找到agent/config.yaml 文件,用你喜欢的代码编辑器打开它。它看起来就像这样:
server:
log_level: debug
traces:
configs:
- name: server_traces
receivers:
otlp:
protocols:
http:
endpoint: "0.0.0.0:4318"
remote_write:
- endpoint: tempo:4317
insecure: true
简单地说,这指示代理在调试模式下记录一切,并创建一个新的traces配置部分,从应用程序接收OTLP格式的traces。然后把它们写到你正在运行的Tempo实例中。
我们要在配置文件中添加一个新的部分。Grafana Agent使用OpenTelemetry尾部采样处理器,因此支持OpenTelemetry收集器的所有采样策略。
让我们做一个明显的改变,使用尾部采样来确保我们只接收有错误的痕迹。
你如何做到这一点?嗯,你需要知道如何过滤进入Agent的轨迹的跨度数据,以便它只标记那些有错误的轨迹。幸运的是,OpenTelemetry规范中有一个惯例,包括为跨度设置状态代码。这意味着,对于你写的任何发生错误的代码,你可以在该点生成的span上设置一个错误状态,这将标志着错误的发生。一般来说,设置一个特定的错误代码和信息来详细说明出错的原因也是很有用的。
如果我们快速看一下下面这个应用程序的代码(src/index.js 文件),我们可以看到这正是发生的情况:
let spanStatus = api.SpanStatusCode.OK;
if (dbError) {
spanStatus = api.SpanStatusCode.ERROR;
dbSpan.setAttributes({
'db.error': 'INVALID_DATA',
'db.error_message': 'Invalid data sent to Database',
});
…
}
dbSpan.setStatus({ code: spanStatus });
我专门在这个跨度上设置了错误代码状态,以及作为属性的额外错误信息。这也确保了父跨度上有一个错误设置,以便将其向上渗透。这可以在后面的代码中看到。
我们可以通过使用Grafana中Tempo数据源的跨度搜索功能搜索错误来看看这个动作。通过搜索有相应状态代码设置的跨度,你可以看到所有有错误抛出的轨迹。
这很容易转化为Agent中尾部采样的过滤器。回到它的开放配置(agent/config.yaml 文件),添加一个新的部分(注意,这需要与remote_write 的相同部分一致):
tail_sampling:
policies:
- status_code:
status_codes:
- ERROR
这个配置块做了几件事。它首先表示我们正在定义一个tail_sampling 部分,然后表示它将包括一个或多个策略(你可以同时定义多个策略)。status_code 策略需要一个叫做status_codes 的块,它定义了存储跟踪所需的代码。目前这些值是: , 和 。UNSET ERROR OK在这种情况下,我们只想存储那些具有ERROR 代码集的跨度的痕迹。
在一个不同的命令行终端,通过运行以下程序重新启动Agent:
docker-compose restart agent
这将以新的尾部采样策略重启Agent。在这一点上,也许值得泡杯茶(或者你选择的饮料),一方面是为了小憩一下,另一方面是因为如果你让系统运行几分钟,你就会更清楚地知道你现在只收集有错误的痕迹了
让我们回到Grafana实例来看看这些变化。我们将查看痕迹的日志(尽管我们也可以像以前一样,轻松地使用Tempo可视化器中的跨度搜索功能'Search - Beta')。展开细节,查看没有发生错误的日志行(任何绿色条目)。点击Tempo按钮,你会看到像这样的东西。
尽管我们有一个表示事件的日志行,并且追踪是由应用程序检测的,但你在Tempo面板上看到一个查询错误的原因是Grafana Agent使用其尾部采样策略丢弃了追踪,因为其中没有一个跨度的状态代码被设置为错误。你可以通过找到标记有错误的日志行(用红色条目表示),并选择Tempo按钮转到相关的追踪,就可以证明我们还在收集追踪。
另一个有用的过滤器是只收集那些有用的端点的痕迹。大多数服务都有健康检查(或 "ping")端点,可以用来确定服务是否正常。我们的应用程序正在追踪的一个端点是/healthcheck 。我们也有几个指标端点--同样是我们不太关心的追踪的东西。所以让我们创建另一个尾部采样策略,忽略这两个。
回到编辑器中的Grafana Agent配置,删除我们为捕获错误而创建的策略。取而代之的是,用下面的块来代替它:
tail_sampling:
policies:
- string_attribute:
key: http.target
values:
- ^\/(?:metrics\/.*|healthcheck)$
enabled_regex_matching: true
invert_match: true
这定义了一个类型为string_attribute 的新策略。这个策略需要一个span标签/属性键来进行过滤,在这种情况下,寻找表示被请求的端点的http.target 属性。values 数组允许你设置一个或多个值,与字符串属性的键值进行匹配。如果有匹配的,那么就会存储跟踪。在这种情况下,我们决定与/metrics/* 和/healthcheck 端点进行匹配。
现在,在这一点上你可能在想,"等等--如果在这些值上发生匹配,那么这些痕迹就会被存储起来......这实际上是与我们想要的相反!"
这就对了!令人高兴的是,这个策略类型包括一个invert_match 布尔选择器,这意味着只有那些与我们的值不匹配的痕迹才会被存储。健康检查和指标端点的痕迹实际上会被丢弃。
你可以通过命令行终端再次重启代理:
docker-compose restart agent
同样,让系统运行几分钟,然后让我们用LogQL在Loki中找到一些健康检查和指标端点的痕迹。
这个LogQL查询确保你只找到与/healthcheck 或/metrics/* 有关的日志行。选择这些条目中的任何一个,然后试图找到与之相关的痕迹,都会失败,因为你已经过滤掉了这些痕迹。
如果你寻找任何其他的日志行,使用我们使用的LogQL查询的反转,你会发现其他端点的所有痕迹都被存储了。
很好!你现在知道如何创建两个独立的策略,收集错误并过滤掉特定的端点。但是你如何确保只看到你关心的端点上的错误?
好吧,OpenTelemetry还包含几个策略,允许你结合其他策略。其中之一是 "和 "策略,顾名思义,它允许你将策略和策略结合起来,形成一个超级策略。
再次编辑Agent配置文件,并将尾部采样块替换为以下内容:
tail_sampling:
policies:
- and:
and_sub_policy:
- name: and_tag_policy
type: string_attribute
string_attribute:
key: http.target
values:
- ^\/(?:metrics\/.*|healthcheck)$
enabled_regex_matching: true
invert_match: true
- name: and_error_policy
type: status_code
status_code:
status_codes:
- ERROR
在这里,你使用 "和 "策略将你之前的两个策略合并成一个。现在你将只看到那些表示发生了错误,但不在指标或健康检查端点上的蛛丝马迹。
同样,在另一个终端窗口重新启动代理:
docker-compose restart agent
现在你可以安全地确保只有来自你关心的端点的错误被存储!你可以通过以下方式轻松地检查这一点。你可以通过回到Grafana来检查这是否有效。你应该看到,只有在健康检查和指标端点上没有发生的错误的痕迹是可用的。
更多的跟踪采样策略
这是对使用Grafana Agent进行尾部采样的一次相当不错的参观,但值得注意的是,状态码和跨度属性策略只是两个基本的例子。事实上,还有几个非常有用的采样策略:
- 概率性(有时被称为随机)抽样允许你只存储Agent看到的1个intraces。
- 延迟过滤器确保只存储超过一定时间的痕迹。
- 数值跨度属性检查允许你只存储属性值在最小和最大值之间的痕迹。
- 速率限制每秒钟最多存储一定数量的跟踪。
- 复合策略将传入的跟踪率的一个百分比分配给子策略。
这些足以确保你能够进行几乎所有你可能需要做的跟踪过滤。
快乐采样!
