

这是我参与「第四届青训营」笔记创作活动的的第14天
1.为什么做行为数据分析
1.1为什么要做用户数据分析
在企业竞争越来越激烈,获客成本越来越高的背景下,如何高效地理解用户需求和精细化运营是当前企业竞争的关键,而用户数据分析正是我们保持此竞争力的重要手段,我们通过数据来驱动用户增长、降低成本和提高收益。
2.数据分析的各个环节
数据分析全景图
搭建指标体系的价值
- 衡量经营状况
- 统一口径和统一认知
- 团队牵引
- 支撑后续制定目标和衡量目标
- 发现问题
- 定位问题
埋点简介
1.埋点(数据)是什么?
埋点数据是指上报的记录着触发原因和状态信息的日志数据。按照上报方来看,可以划分为“服务端埋点”和“客户端埋点”按照上报形式,可以划分为“代码埋点”、“可视化全埋点”。
2.埋点包含哪些要素?
who when where how what how much “张三”于“北京时间2022年1月2号12点整”在“游戏商城”用“xx支付”的形式“充值”了“500元”钻石。
3.在哪里埋点呢?
在你要做数据分析的环节来埋点。
数据分析的各个环节
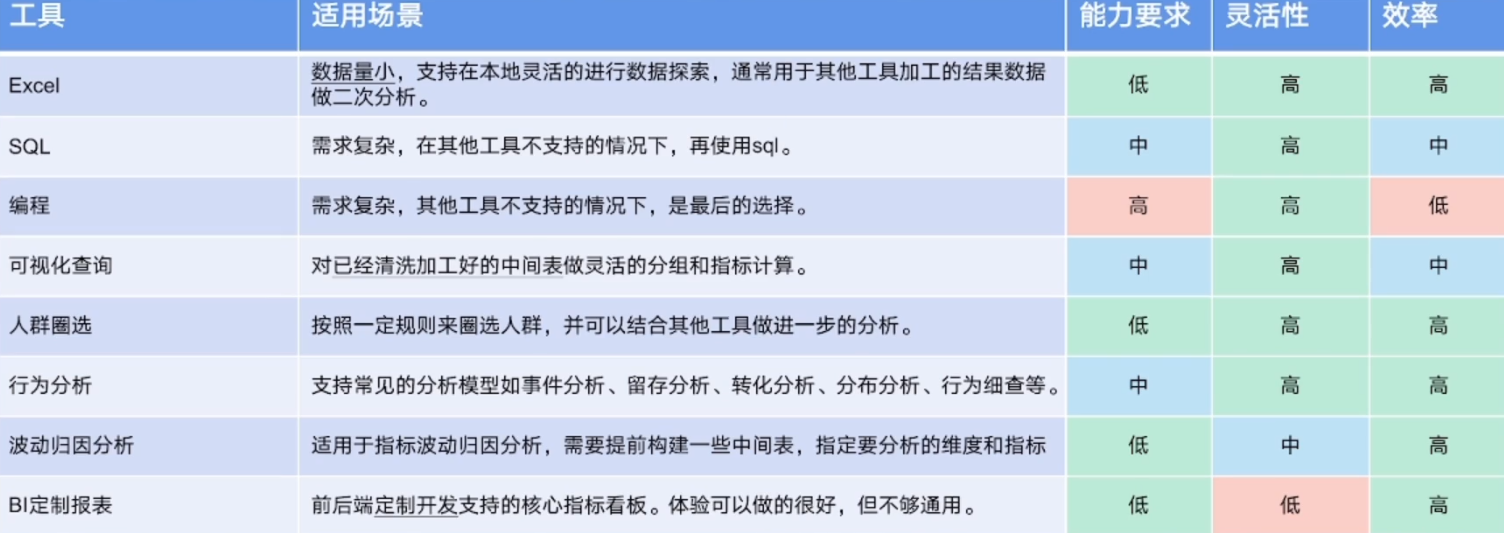
数据表与SQL
表的基本构成:表名、表字段、表字段类型等。 SQL:结构化查询语言,用来操作表的语言。细分为DDL(数据定义语言)和DML(数据操纵语言)等。
指标和维度
指标是数据的量化统计,维度是数据分组的方式。
3.数据分析的流程和案例
分析流程
明确目的
- 验证有没有问题
- 定位问题原因
- 做数据探索
- 评估工作重心
经验猜想
- 整体上就是大胆假设,小心求证。
- 1.找同事提供支持
- 2.亲自使用产品
数据准备
- 采集
- 摸底
- 清洗
数据分析
- 维度对比下钻
- 指标拆解
产出报告和优化建议
验证
- AB测试
- 调查问卷
- 舆情分析(放风)
全量实施和总结复盘
- 评估收益
- 总结经验
- 找老板邀功
分析思路
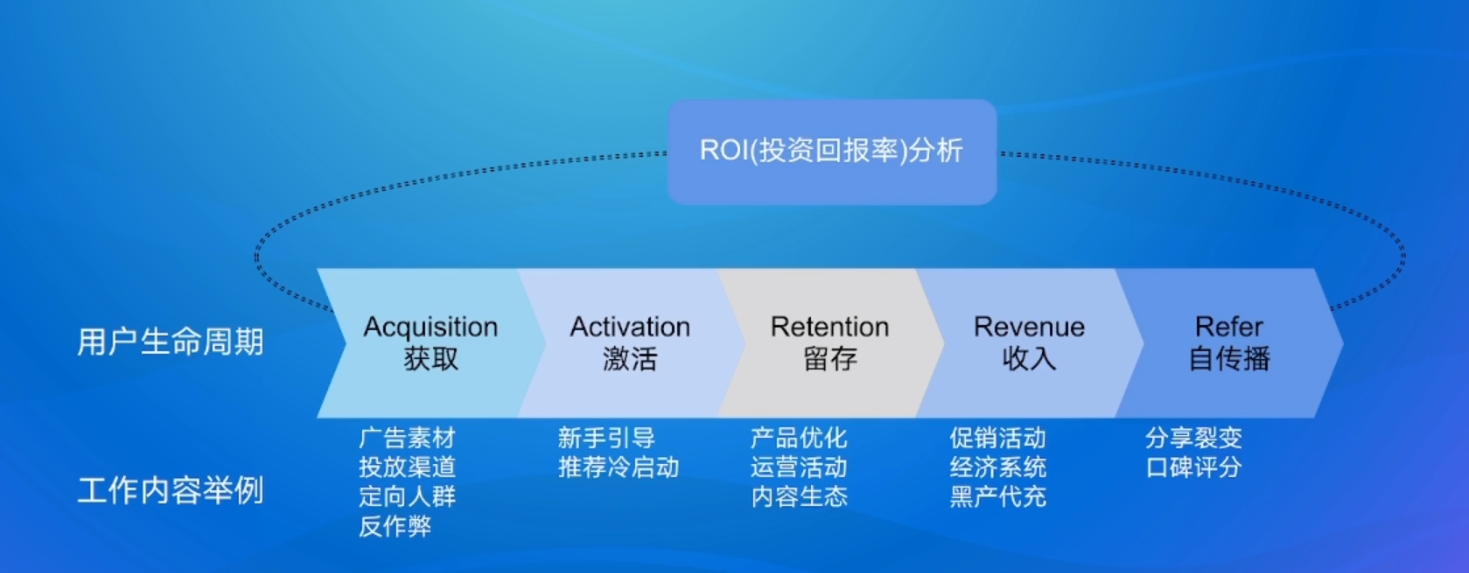
数据分析常见的问题
- 上游数据质量不高
- 不验证就全量上线
- 优化策略短期有利而长期有损
- 过分挖掘用户信息,不注重用户隐私保护
4.总结与思考题
01.机器学习概览
为什么要机器学习?
-
人工智能时代已经到来
- 个性化推荐
- 机器翻译
- 人脸识别
-
大数据成为热议的内容
- 数据多
- 产生快
- 形式杂
- 组织乱
-
解决实际的业务决策问题
- 数据价值
什么是机器学习?
- 机器学习就是把无序的数据转换为有用的信息
- 从数据中自动分析获得模型,并利用模型对未知数据进行预测
标准流程
- 原始数据
- 数据探测
- 特征工程
- 构建数据集
- 建模调参
- 模型评估
机器学习算法有哪些?
机器学习有非常多的种类及相应的算法,主要可以分成三大类︰
- 监督/非监督学习--取决于训练是否需要人类的监督
- 批量/在线学习--取决于系统是否能持续地从数据流中学习并更新
- 基于实例/模型学习--取决于系统是直接把新数据与旧数据比较,还是通过建模来预测
机器学习的挑战有哪些?
在机器学习中,面临的挑战主要来自两大模块:糟糕的算法和糟糕的数据。
-
1.算法的问题主要有以下两种︰
- 过拟合( Overfitting )
- 欠拟合(Underfitting )
-
2.数据的问题具体表现为∶
- 训练数据太少
- 训练数据不具备代表性
-
3.数据本身质量很差
-
4.选取的特征没有相关性
在大数据场景下,对资源的要求非常高,比如存储和算力。
02.特征工程
概述
- 定义∶特征工程是将原始数据转化成更好的表达问题本质的特征的过程。
- 意义∶数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。
- 创造新的特征是一件非常困难的事情,需要丰富的专业知识和大量的时间。机器学习的本质本质就是特征工程。
流程
- 数据理解
- 数据预处理
- 特征构造
- 特征选择
Embedding概览简介
- Embedding,即嵌入,起先源自于NLP领域,称为「词嵌入( word embedding )」,主要是利用背景信息构建词汇的分布式表示,最终可以得到一种词的向量化表达,即用一个抽象的稠密向量来表征一个词。
- 直观上看embedding相当于是对oneHot做了平滑,而oneHot相当于是对embedding 做了maxpooling。
Embedding产生过程
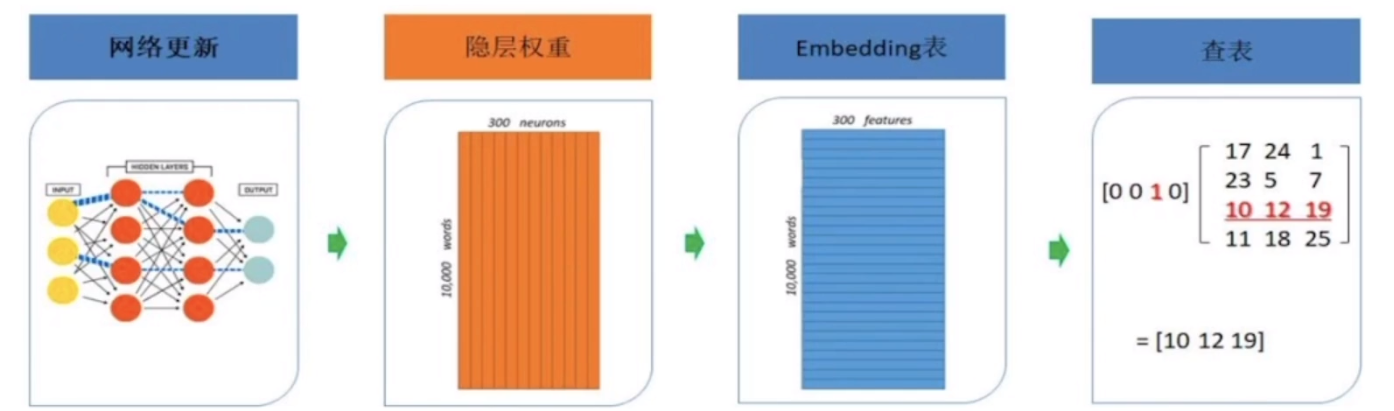
Embedding意义作用
- 解决维度灾难,降低复杂度。
- 解决稀疏容易造成的梯度消失的问题
- 增加语义信息,能够很好地挖掘嵌入实体间的内部关联
03.聚类算法
3.1 概览简介
聚类算法是一种无监督的机器学习算法。在给定的数据集中,我们可以通过聚类算法将具有相似特征的数据分成一组,不相似特征的数据分成不同组。
- K-means
- DBSCAN
- 层次聚类

3.3 K-means
- 首先,我们确定要聚类的数量,并随机初始化它们各自的中心点。
- 通过计算当前点与每个簇中心之间的距离,将每个数据点归到与之距离最近的中心的簇中。
- 基于迭代后的结果,计算每─簇内,所有点的平均值,作为新簇中心。
- 迭代重复这些步骤,或者直到簇中心在迭代之间变化不大。
关于聚类的簇数量最优选择,常用肘部法和轮廓系数法,可参考此文章www.biaodianfu.com/k-means-cho…
04.聚类画像分析
概览简介
一个基于聚类的用户画像分析工具,以对用户群体进行标注及定位
- 洞察群体用户在站内的消费、投稿内容生态情况
- 研究用户与内容的关系和演变,理解业务增长的变化,制定用户与内容的增长策略。
流程
分析过程
向量获取
选择Embedding作为聚类算法特征的依据∶
- 具有用户行为的语义特征,能学习到用户行为数据之间的关联
- 离线分析用到线上推荐特征,可作为线上推荐效果的debug工具,反映其效果好坏
聚类算法
选择K-means算法作为分群的依据︰
- 用户推荐向量满足凸优化函数求解问题
- 算法的复杂度、数据量、以及机器资源的trade-off
- 可理解性和算法稳定性
cluster level可视化分析
核心指标层面可分为︰
- 定性指标:从内容角度理解cluster人群偏好的兴趣,比如Top播放视频、Top收藏视频、投稿的随机抽样、词云、头像等
- 定量指标:从数量角度理解cluster人群的具体表现,优劣情况,比如年龄/性别操作系统的数量分布,视频播放次数、视频完播次数、分享/评论/点赞/收藏率、活跃天数、留存率等
应用场景
- 用户群体的兴趣偏好,帮助理解站内人群的结构
- 内容消费情况,帮助理解哪些内容更受欢迎
- 发现核心群体,基于其喜欢的内容,制定增长策略
