

在Ruby中进行多线程工作时,有几种方法可以控制特定线程中的执行流程。在这篇文章中,我将探讨Thread#pass 和Queue#pop ,以及如何理解它们中的每一个都能帮助你大幅度地优化你的应用程序。
线程#pass--它是什么,它是如何工作的
你可以要求调度员 "做别的事情 "的方法之一是使用Thread#pass 方法。
你在哪里可以找到它?嗯,除了Karafka之外,例如在ActiveRecord最近增加的一个叫做#load_async (pull request)的地方。
让我们看看它是如何工作的,以及为什么它可能是或不是你在构建多线程应用程序时正在寻找的东西。
Ruby文档对它的描述相当简约。
给线程调度器一个提示,将执行传递给另一个线程。一个正在运行的线程可能会也可能不会切换,这取决于操作系统和处理器。
这意味着,在处理线程时,你可以告诉Ruby,从执行当前的线程转向关注其他线程,这并不是一个坏主意。
默认情况下,你创建的所有线程都有相同的优先级,并被以同样的方式对待。下面的代码就是一个很好的说明。
threads = []
threads = 10.times.map do |i|
Thread.new do
# Make threads wait for a bit so all threads are created
sleep(0.001) until threads.size == 10
start = Time.now.to_f
10_000_000.times do
start / rand
end
puts "Thread #{i},#{Time.now.to_f - start}"
end
end
threads.each(&:join)
# for i in {1..1000}; do ruby threads.rb; done > results.txt
平均来说,每个线程的计算都花费了类似的时间。
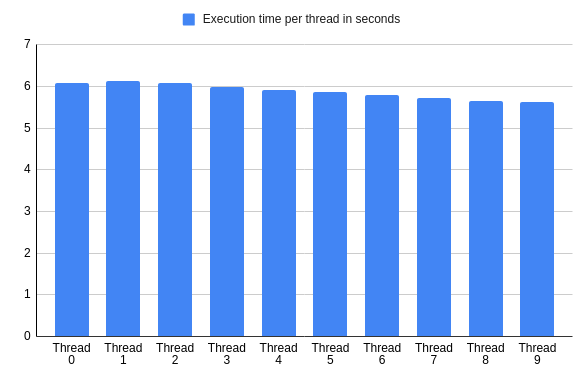
最快和最慢的线程之间的差异不到8%。
然而,当其中一个线程 "通过 "时,事情发生了巨大的变化。
threads = []
threads = 10.times.map do |i|
Thread.new do
sleep(0.001) until threads.size == 10
start = Time.now.to_f
10_000_000.times do
Thread.pass if i.zero?
start / rand
end
puts "Thread #{i},#{Time.now.to_f - start}"
end
end
threads.each(&:join)
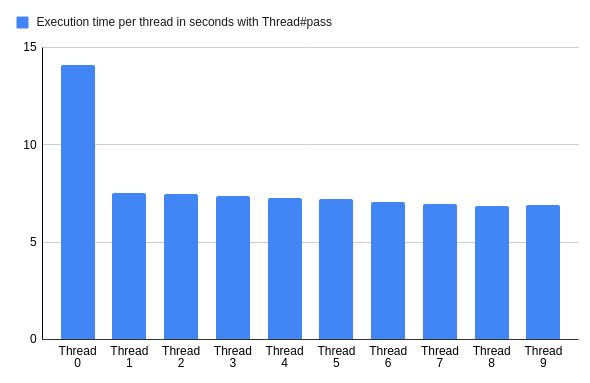
现在,零号线程花费的时间是其他线程做同样工作的两倍。
值得指出的是,这种方法本身并没有停止执行流程,它只是向Ruby提示,可能还有其他更重要的事情要做。
Jean Boussier在ActiveRecord中正是使用了这种行为。
def schedule_query(future_result) # :nodoc:
@async_executor.post { future_result.execute_or_skip }
Thread.pass
end
这段代码安排了一个后台工作,并向调度器建议,可能值得在其他地方做这个或其他事情。
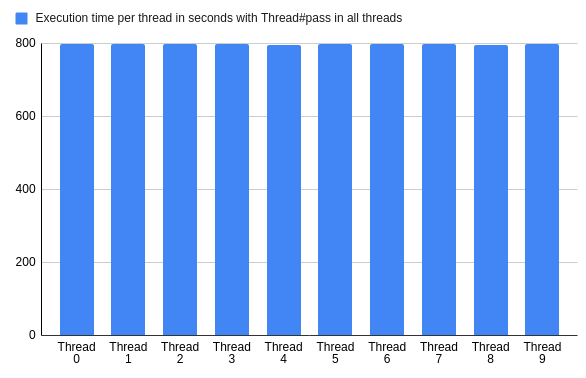
值得一提的是,当所有的线程都使用Thread#pass ,这对Ruby VM来说是一个巨大的负担。由于没有一个线程愿意做任何工作,Ruby会发疯,执行时间会增加100倍以上。
队列#pop--它是什么以及它是如何工作的
Queue 是一个众所周知的类, 是它包含的最重要的方法之一。#pop
下面是Ruby文档中关于Queue 类和#pop method 的内容。
Queue类实现了多生产者、多消费者的队列。当信息必须在多个线程之间安全交换时,它在线程编程中特别有用。队列类实现了所有需要的锁定语义。
#pop:如果队列是空的,调用线程将被暂停,直到数据被推送到队列中。如果non_block为真,线程就不会被暂停,并且会引发ThreadError。
当被问及队列时,大多数程序员想到的是工人从队列中消耗作业。
numbers = Queue.new
threads = 10.times.map do |i|
Thread.new do
while number = numbers.pop
result = Time.now.to_f / number
# a bit of randomness
sleep(rand / 1_000)
puts "Thread #{i},#{result}"
end
end
end
10_000.times { numbers << rand }
# see what I did here? ;)
Thread.pass until numbers.empty?
numbers.close
threads.each(&:join)
关于Queue#pop ,值得注意的是,它将阻塞某个线程的执行,直到有事情要做。这意味着,从性能的角度来看,被阻塞的线程几乎是 "看不见的"。下面是一个运行计算的例子,其中有0、4、9和99个阻塞的线程。
queue = Queue.new
THREADS = 4
THREADS.times do
Thread.new { queue.pop }
end
# Wait until all the threads are initialized
Thread.pass until queue.num_waiting == THREADS
start = Time.now.to_f
10_000_000.times do
start / rand
end
puts Time.now.to_f - start
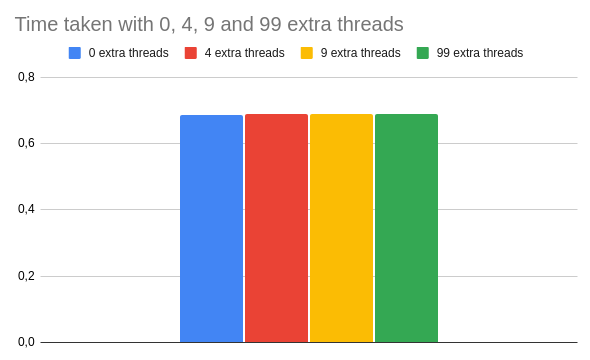
正如你所看到的,不活动的线程对这段代码的整体性能没有很大影响。即使有99个额外的线程,最终的结果也与基线相差不大。
减少多线程环境下的方法调用
现在你知道了Thread#pass 和Queue#pop 的作用,让我们把它们放在一个真正的用例中工作。为了实现这一目标,我们将研究Karafka框架。
Karafka是一个用来简化基于Apache Kafka的Ruby应用开发的框架,是我建立的。该版本2.0 ,支持跨多线程的工作分配。从数据处理的角度来看,它的工作方式非常简单。
1.从Kafka中获取一些数据
2.将其分为处理单元(作业)
3.把所有的工作放到一个队列中
4.等待所有的工人挑选工作并完成所有的工作
5.无休止地重复
假设有无穷无尽的数据流可用,这几乎可以按以下方式建模。
queue = Queue.new
THREADS = 10
THREADS.times do |i|
Thread.new do
loop do
data, task = queue.pop
task.call(data)
end
end
end
def wait_for_jobs_to_finish(queue)
Thread.pass while queue.num_waiting < THREADS || !queue.empty?
end
def data
Array.new(10) { rand }
end
task = ->(data) { data * 2 }
100_000.times do
data.each { queue << [_1, task] }
wait_for_jobs_to_finish(queue)
end
这就是我最初实现听众循环和工作分配的方式。
当对Thread#pass 的执行次数进行基准测试时(我们衡量最大吞吐量的地方),情况看起来很稳定。
尽管迭代次数增加了,但我们不会在每个迭代中更频繁地等待。这意味着,我们的工作足够短,可以在Ruby返回等待循环之前完成。
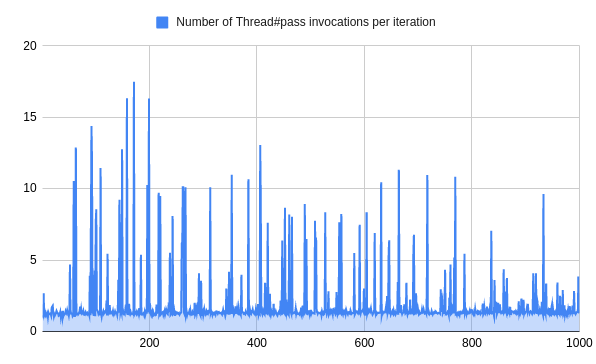
如果我们假设我们的工作在线程执行被打断之前需要的时间比Ruby给的时间多,事情就会变得更有趣。那么事情就会变得不一样了。
# Same code as before but the job has a bit of sleep simulating IO
task = ->(data) { sleep(rand(9..11) / 10000.0) }
假设我们每项工作耗时1ms左右,那么通过的次数就会激增。
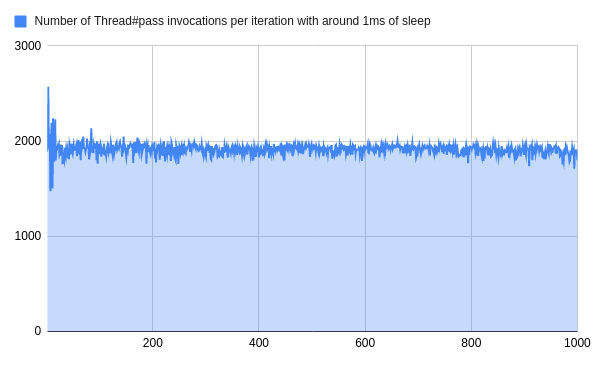
这意味着同一方法的调用次数增加了1000多倍。
在这种情况下,我们每个作业要运行大约100ms(+/-10%)的重度查询,我们最终每个迭代的结果如下。
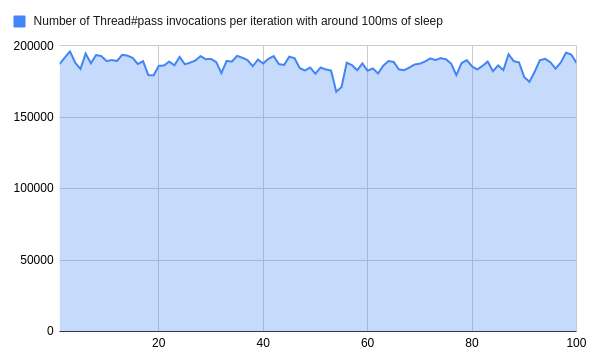
这意味着,Ruby不得不平均运行18万次以上的#Thread#pass ,白白浪费了。
在优化任何代码时,最好是确定其使用的主要用例。在Karafka的案例中,虽然原始吞吐量很重要,但更多的是复杂的工作能够使用GVL发布策略,允许在IO时执行并行工作。
那么,有没有更好的方法让Ruby耐心地等待所有工作的完成?有的。 Queue#pop. 由于它是线程安全的,我们可以用它来通知主线程,给定的工作已经完成。这不会消除无用的运行,但它会大大减少它们,事实上,它们将变得无足轻重。由于我们知道我们已经排了多少个作业,我们知道我们需要多少次#pop 。
queue = Queue.new
lock = Queue.new
THREADS = 10
THREADS.times do |i|
Thread.new do
loop do
data, task = queue.pop
task.call(data)
lock << true
end
end
end
def wait_for_jobs_to_finish(dispatched, lock)
dispatched.times { lock.pop }
end
def data
Array.new(10) { rand }
end
task = ->(data) { data * 2 }
100_000.times do
data.each { queue << [_1, task] }
wait_for_jobs_to_finish(data.size, lock)
end
lock.pop 将停止主线程的执行,直到每个作业完成。这意味着我们随着线程数量的增加而增加停止的次数。然而,这种相关性是线性的,最终的结果比使用Thread.pass 时要小几个数量级。
下面是同样的基准,在非睡眠的情况下,用一些Queue#pop 的调用来代替Thread#pass 。
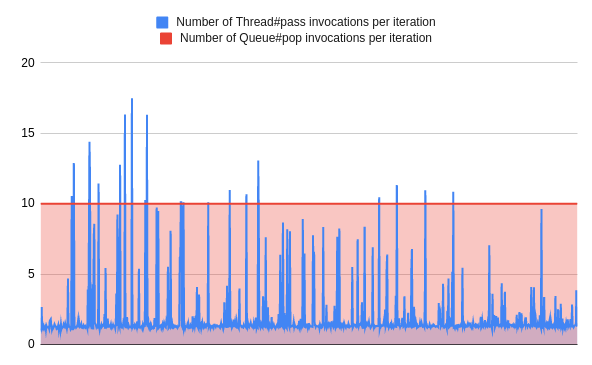
Queue#pop 调用的数量等于线程数。它与作业类型或其他任何情况无关。因此,工作时间越长,改进就越大。
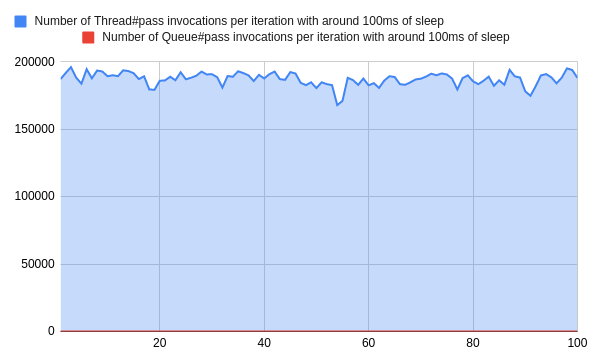
这一变化不仅使调用次数减少了**99.994%**以上,而且还大大降低了CPU的利用率,这在有大量IO的情况下尤其明显(这里用睡眠模拟)。
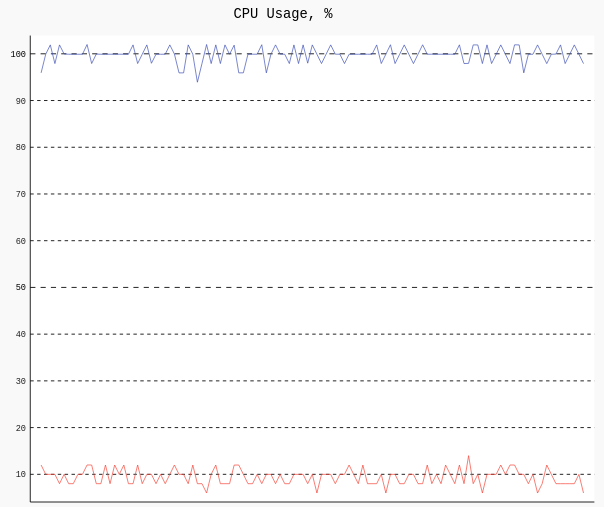
总结
那么,一个比一个好吗?不,它们应该在不同的情况下使用,以实现不同的目标。
Thread#pass 不应该被用来推迟工作,而应该为Ruby提供一个提示,即它可能有更重要的事情可以关注。
Queue#pop 另一方面,它不仅可以作为队列的一个组成部分,还可以作为多线程应用流程控制的一部分。
并发是不容易的。线程管理和选择适当的方法与了解你的主要用例和建立正确的基准一样关键。有时微小的调整可以提供巨大的好处。
