

MongoDB Atlas支持谷歌云(GC),使您能够在几分钟内轻松地在GC内启动管理的MongoDB集群。我们很高兴地与大家分享,Databricks最近推出了Databricks on GC,让客户可以在GC和MongoDB Atlas内自由移动和分析他们的数据。随着Databricks的最新更新,现在更容易在GC上开始采用云优先的方法,利用MongoDB Atlas及其为现代应用设计的灵活数据模型和Databricks进行更高级的分析用例。
下面的教程说明了如何在GC和Databricks上使用MongoDB Atlas。我们将在MongoDB Atlas中使用样本销售数据,并使用GC上的Databricks计算滚动平均值。本教程包括以下内容:
-
如何从GC上的MongoDB Atlas读取数据到Spark中
-
如何在Databricks中把MongoDB Connector for Spark作为一个库运行
-
如何使用PySpark库来执行销售数据的滚动平均数
-
如何将这些平均数写回MongoDB,以便应用程序能够访问它们
创建Databricks工作区
要配置一个新的Databricks工作空间,你需要有一个已经创建的GC项目。如果你还没有在GC上部署一个Databricks集群,请按照在线文档创建一个。
注意:遵循文档是很重要的,因为在创建Databricks集群之前,你需要在GC项目中进行一些关键设置,比如启用container.googleapis.com、storage.googleapis.com和deploymentmanager.googleapis.com服务并调整某些Google Cloud配额。
在这个例子中,我们已经创建了谷歌云项目mongodb-supplysales,并准备去谷歌市场将Databricks添加到我们的项目中。
在你的谷歌项目中,点击 "市场",在搜索框中输入 "Databricks":

点击出现的瓷砖,并按照说明操作。
一旦你的Databricks集群被创建,用提供的URL导航到Databricks集群。在这里你可以创建一个新的工作空间:
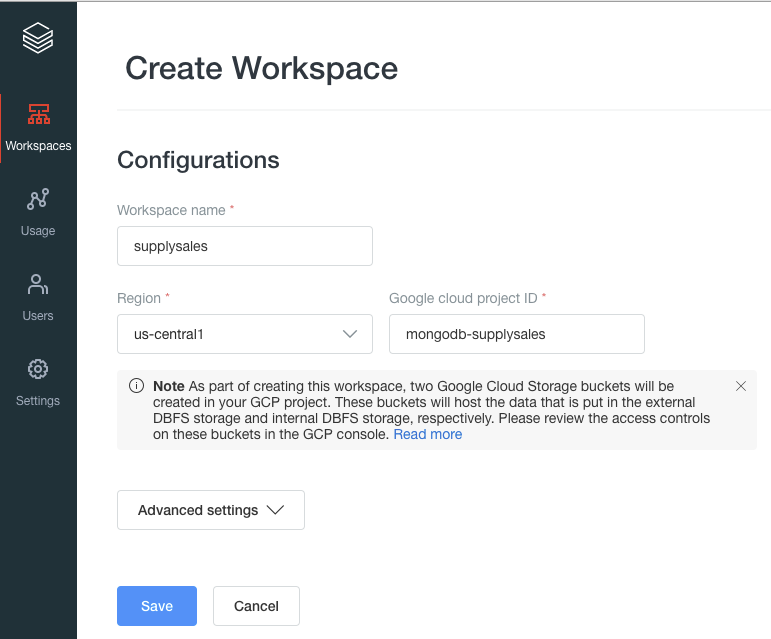
一旦你创建了你的工作空间,你将能够从提供的URL中启动它:
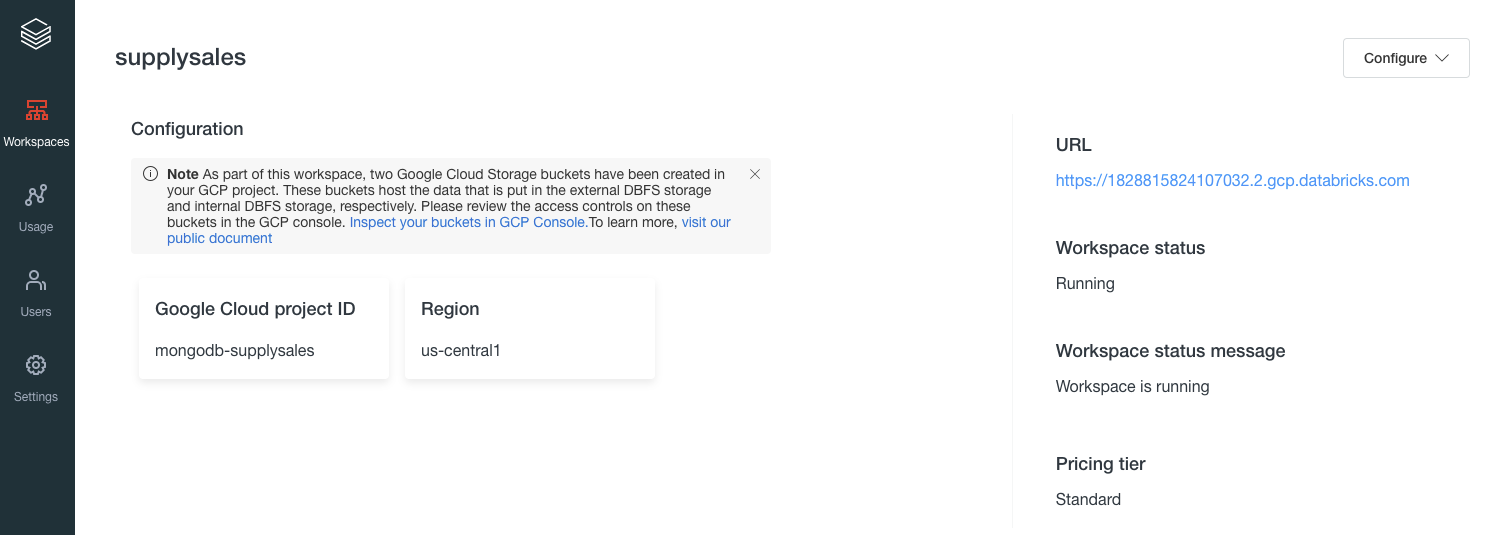
登录到你的工作区,会出现以下欢迎画面:
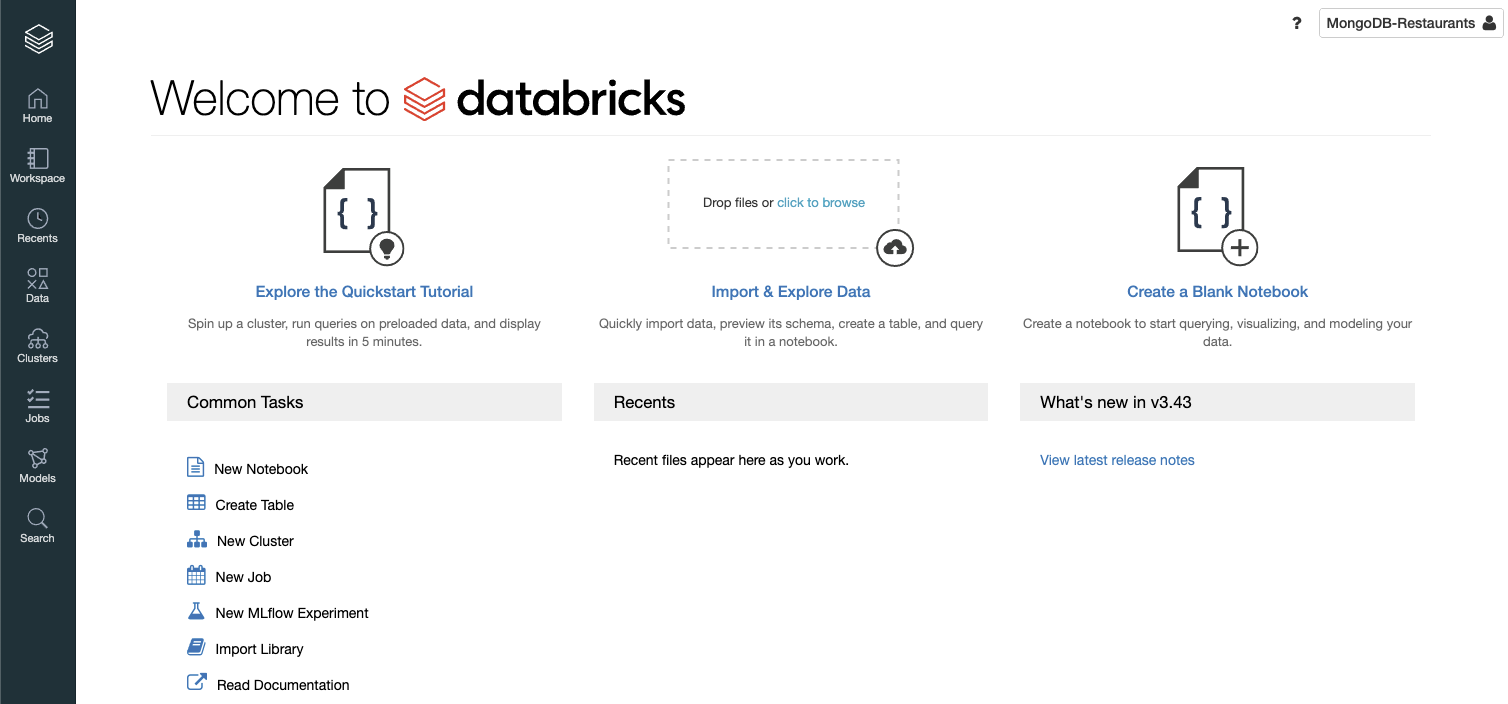
在这篇文章中,我们将创建一个笔记本,从MongoDB读取数据,并使用PySpark库来进行滚动平均计算。我们可以从集群菜单中选择 "+创建集群 "按钮来创建我们的Databricks集群:
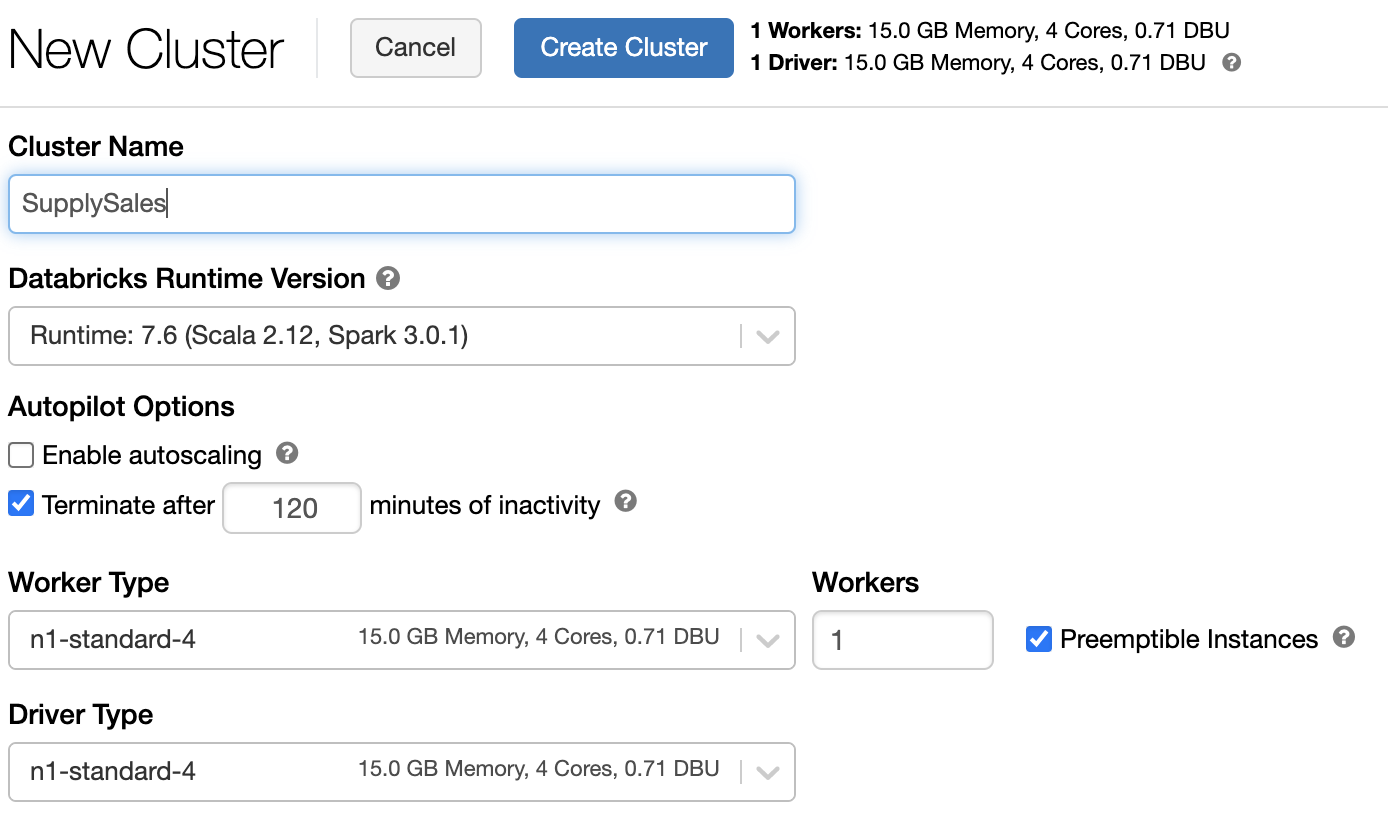
**注意:**为了这个演练的目的,我们只选择了一个工作者和可抢占的实例;在生产环境中,你会希望包括更多的工作者和自动缩放。
在我们创建集群之前,我们可以在高级选项下选择提供Spark配置变量。Spark配置的常见设置之一是定义spark.mongodb.output.uri和spark.mongodb.input.uri。首先我们需要创建MongoDB Atlas集群,这样我们就有一个连接字符串来输入这些值。此时,打开一个新的浏览器标签,导航到MongoDB Atlas。
准备一个MongoDB Atlas实例
一旦进入MongoDB Atlas门户,在用Databricks使用Atlas之前,你需要做以下工作:
-
创建你的MongoDB Atlas集群
-
定义在Spark连接器中使用的用户凭证
-
定义网络访问
-
添加样本数据(本文为可选项)
创建你的MongoDB Atlas集群
如果你已经有一个MongoDB Atlas账户,请登录并创建一个新的Atlas集群。如果你没有账户,你可以在以下网址设置一个免费集群:https://www.mongodb.com/cloud。一旦你的账户设置好了,你就可以通过 "+新集群 "对话框创建一个新的Atlas集群。MongoDB为谷歌云提供了一个免费层:
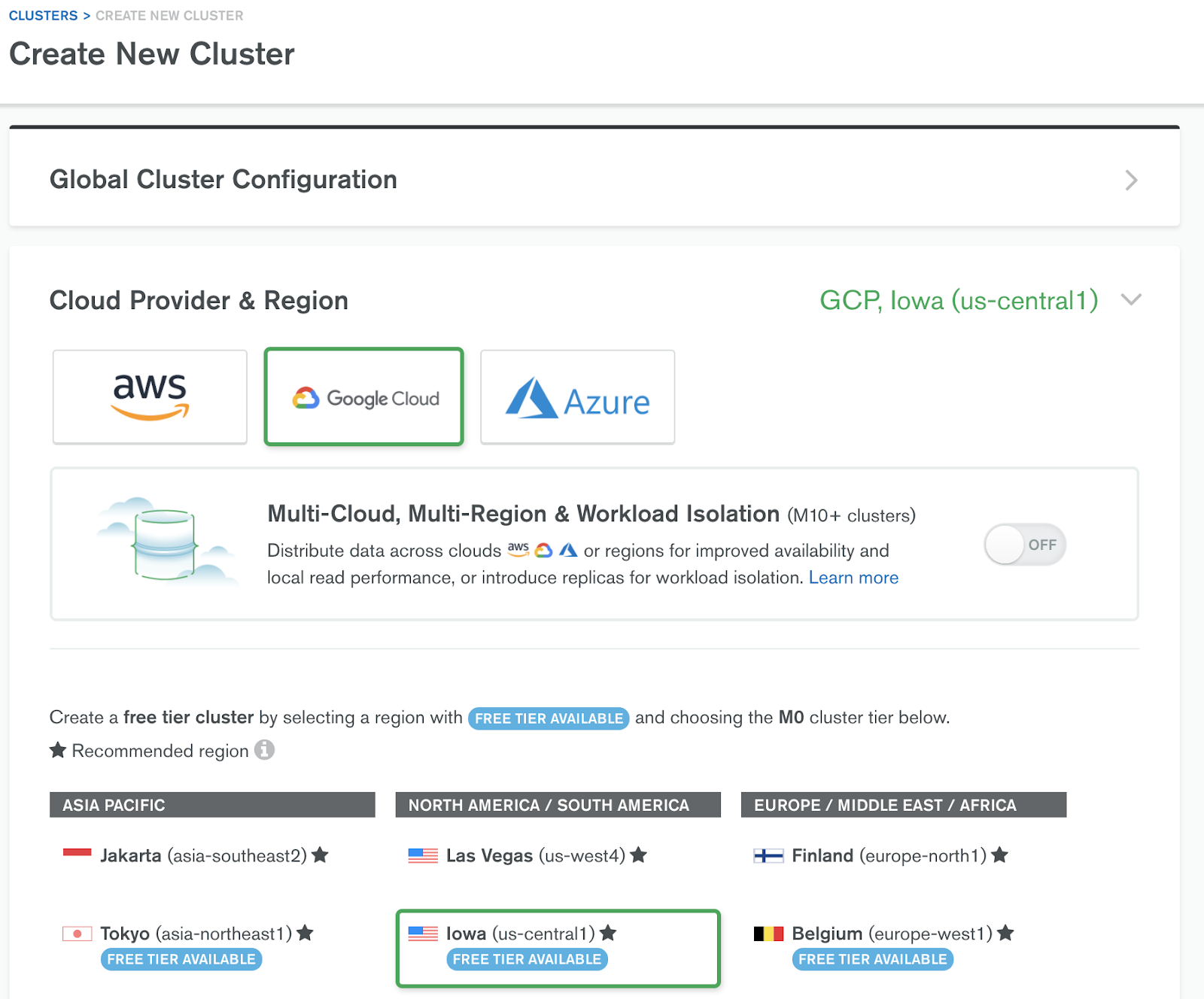
一旦你提供了一个集群名称并点击 "创建",Atlas将需要大约五到七分钟来创建你的Atlas集群。
定义数据库访问
默认情况下,Atlas集群中没有创建用户。为了给我们的Spark集群创建一个身份,以连接到MongoDB Atlas,从数据库访问菜单项中启动 "添加新数据库用户 "对话框:
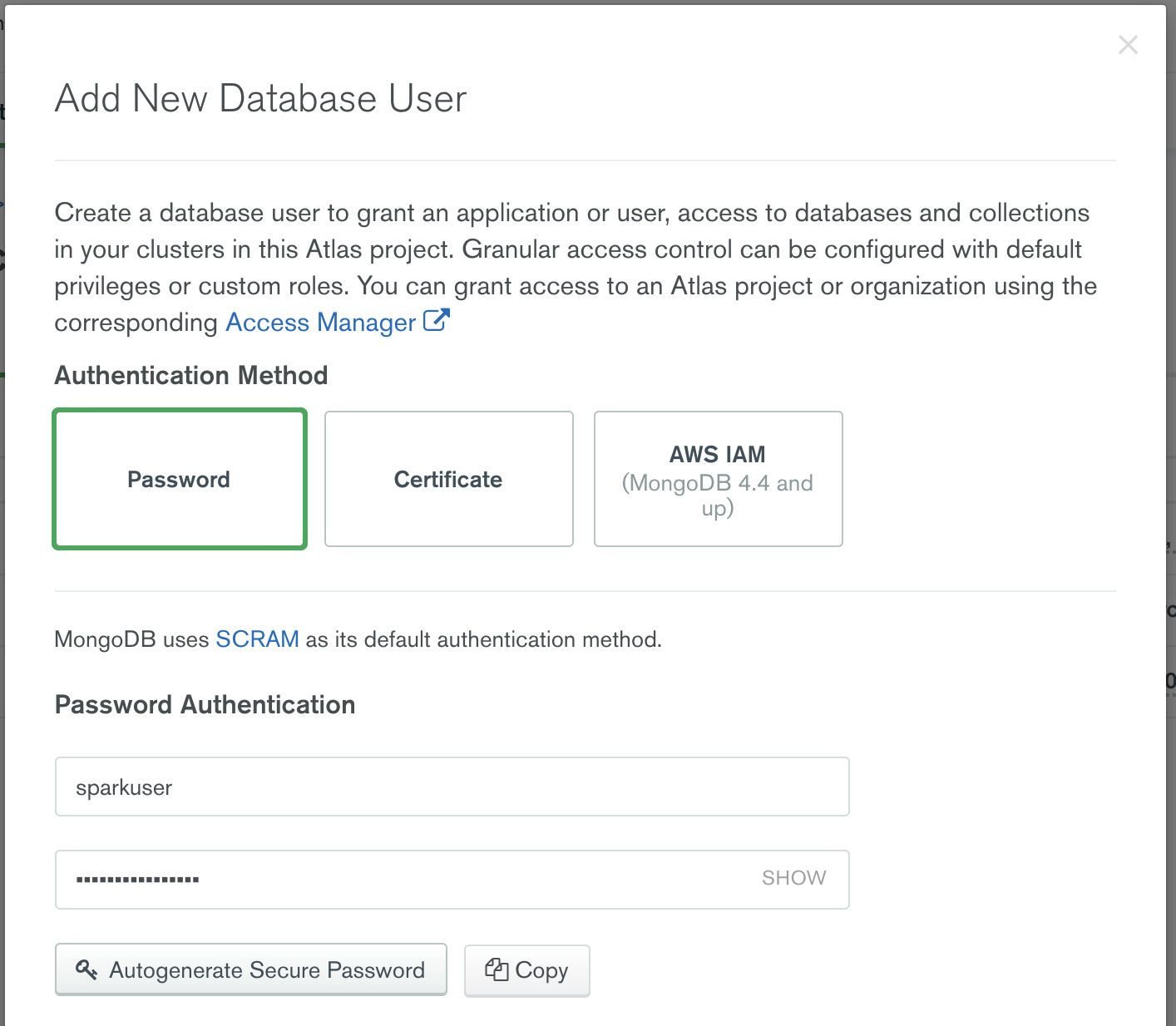
请注意,有三个选项用于对MongoDB Atlas进行认证。密码、证书和AWS IAM认证。选择 "密码",并输入一个用户名和密码。Atlas提供细化的访问控制。例如,你可以限制该用户账户只能在特定的Atlas集群中工作,或者将该账户定义为临时账户,让Atlas在特定时间段内过期。
定义网络访问
MongoDB Atlas默认不允许任何来自互联网的连接。你需要将MongoDB Atlas作为VPC对接或AWS PrivateLink配置的一部分。如果你没有与你的云计算提供商进行这样的设置,你需要指定Atlas可以从哪些IP地址接受进入的连接。你可以通过网络访问菜单中的 "添加IP地址 "对话框来完成这一工作。在本文中,我们将添加 "0.0.0.0",允许从任何地方访问,因为我们不知道我们的Databricks集群将在哪个IP上运行:
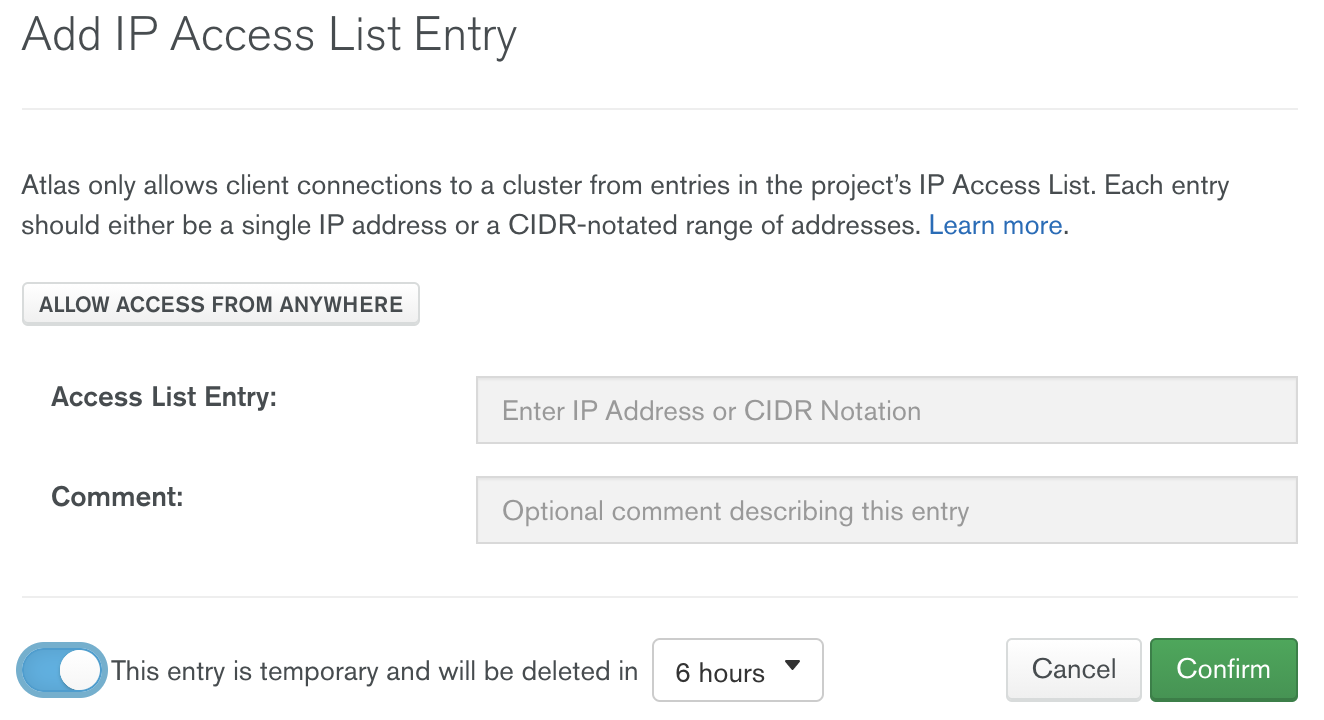
MongoDB Atlas也可以使这个IP访问列表成为临时的,这对于需要允许从任何地方访问的情况来说是非常好的。
添加样本数据
现在我们已经添加了我们的用户账户并允许网络访问我们的Atlas集群,我们需要添加一些样本数据。Atlas提供了几个样本集合,可以从集群的菜单项中访问:
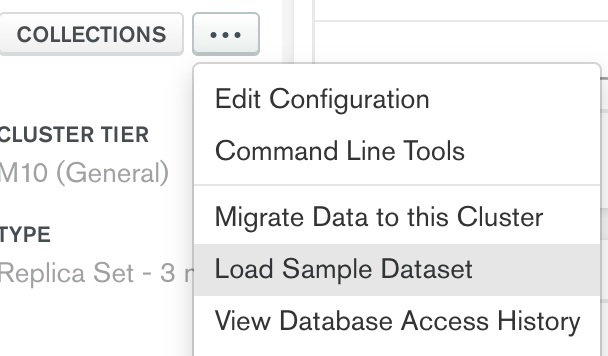
在这个例子中,我们将使用样本_supplies数据库中的销售集合。
用Atlas连接字符串更新Spark配置
通过点击连接按钮并选择 "连接你的应用程序",复制MongoDB Atlas的连接字符串:
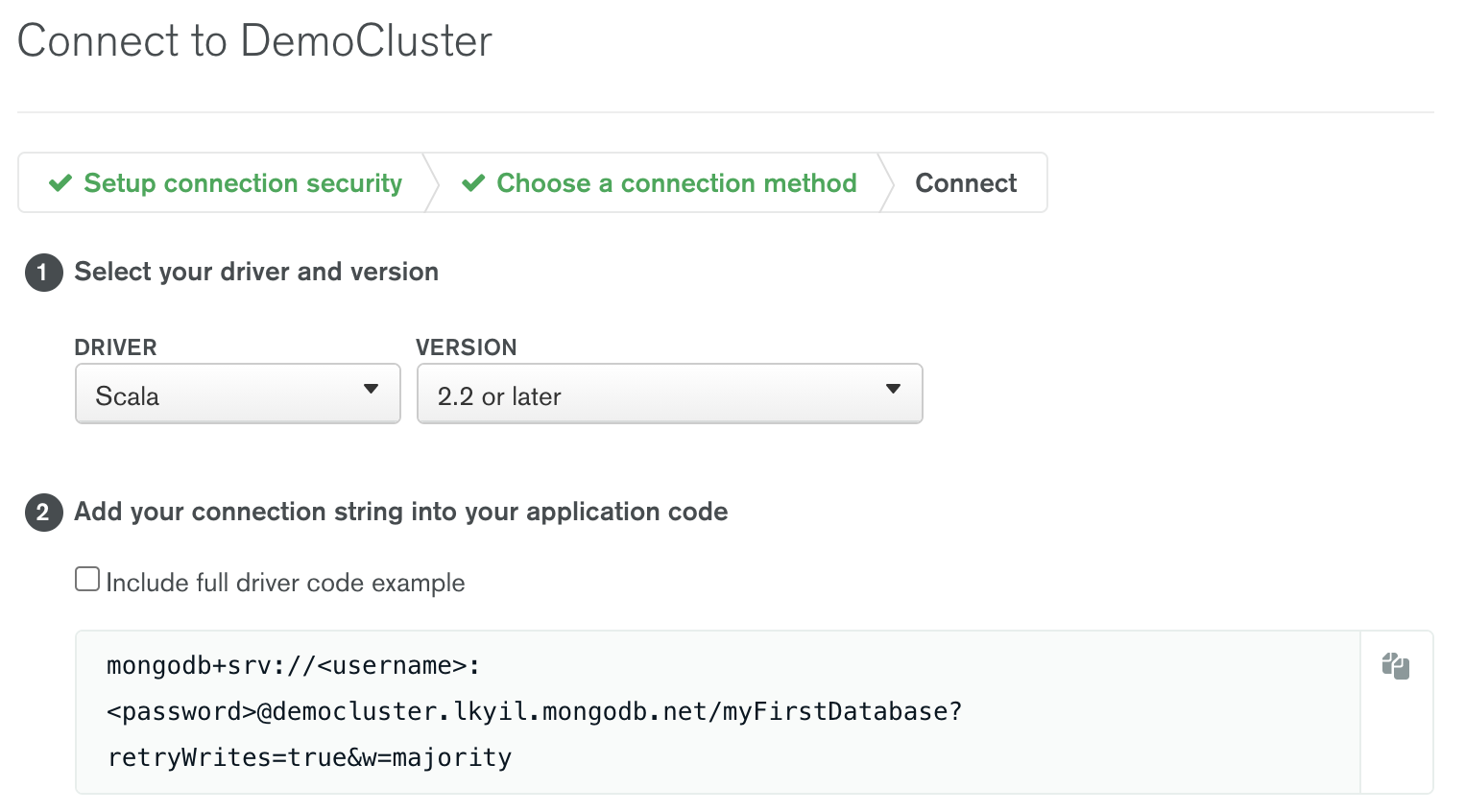
复制连接字符串的内容,并注意以下的占位符 用户名和 密码.你将不得不把这些改为你自己的证书。
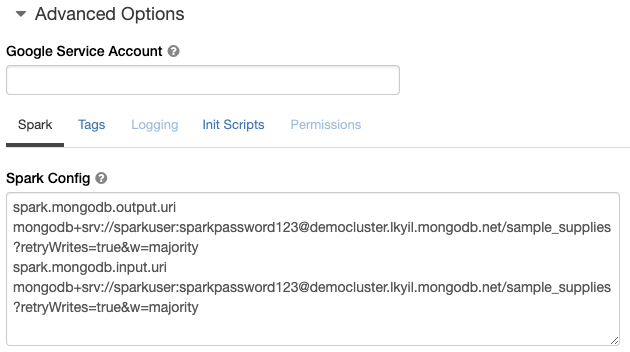
返回到您的Databricks工作区。在Databricks工作区的高级选项下,为spark.mongodb.output.uri和spark.mongodb.input.uri两个变量粘贴连接字符串。请注意,你需要用你之前定义的连接字符串更新MongoDB Atlas中的凭证。为了简化你的PySpark代码,将连接字符串中的默认数据库从MyFirstDatabase改为sample_supplies。(这是可选的,因为你总是可以在运行时通过Spark配置选项定义数据库名称):
启动Databricks集群
现在你的Spark配置已经设置好了,启动集群。
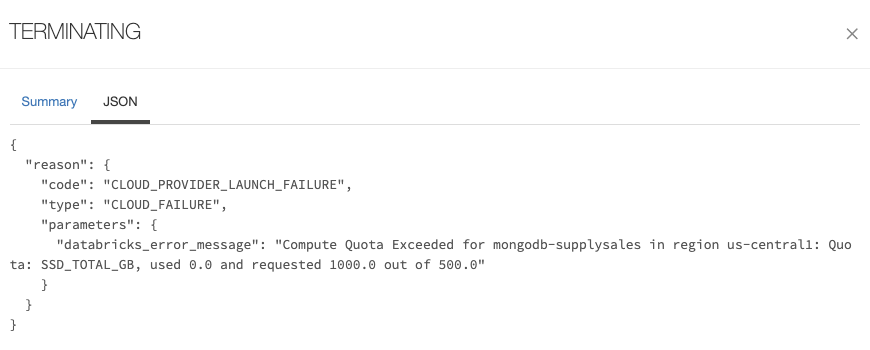
注意:如果集群启动失败,检查事件日志并查看JSON标签。这是一个错误信息的例子,如果你忘记增加SSD的存储配额,你会收到这个错误信息:
添加MongoDB Spark连接器
一旦集群启动并运行,点击Libraries菜单中的 "Install New":
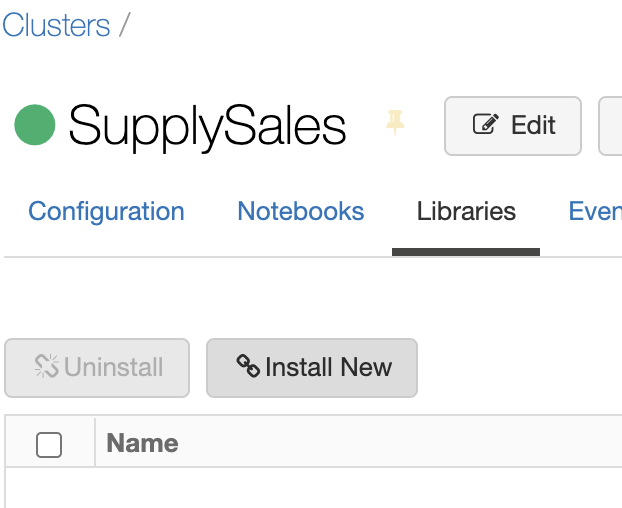
这里我们有多种方法来创建库,包括上传JAR文件或从Maven下载Spark连接器。在本例中,我们将使用Maven并指定org.mongodb.spark:mongo-spark-connector_2.12:3.0.1作为坐标:
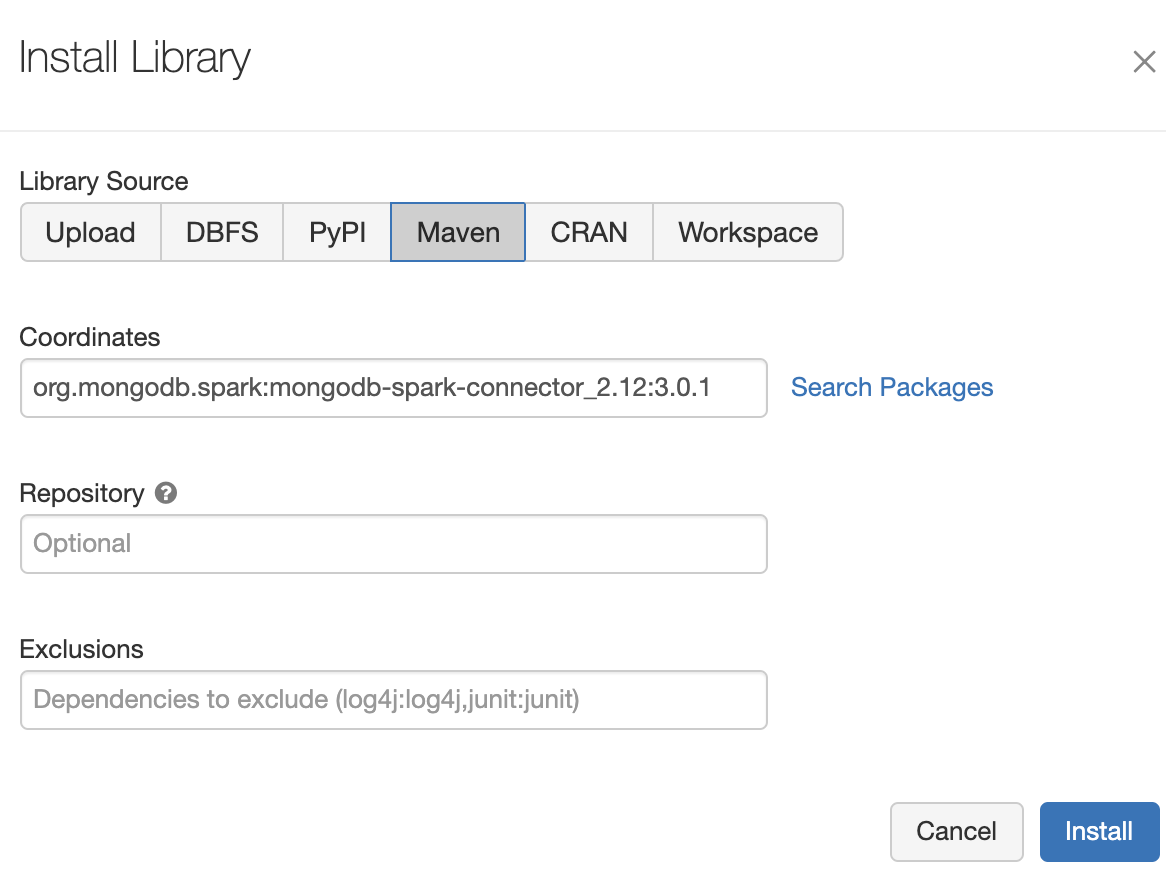
点击 "安装",将我们的MongoDB Spark连接器库添加到集群中。
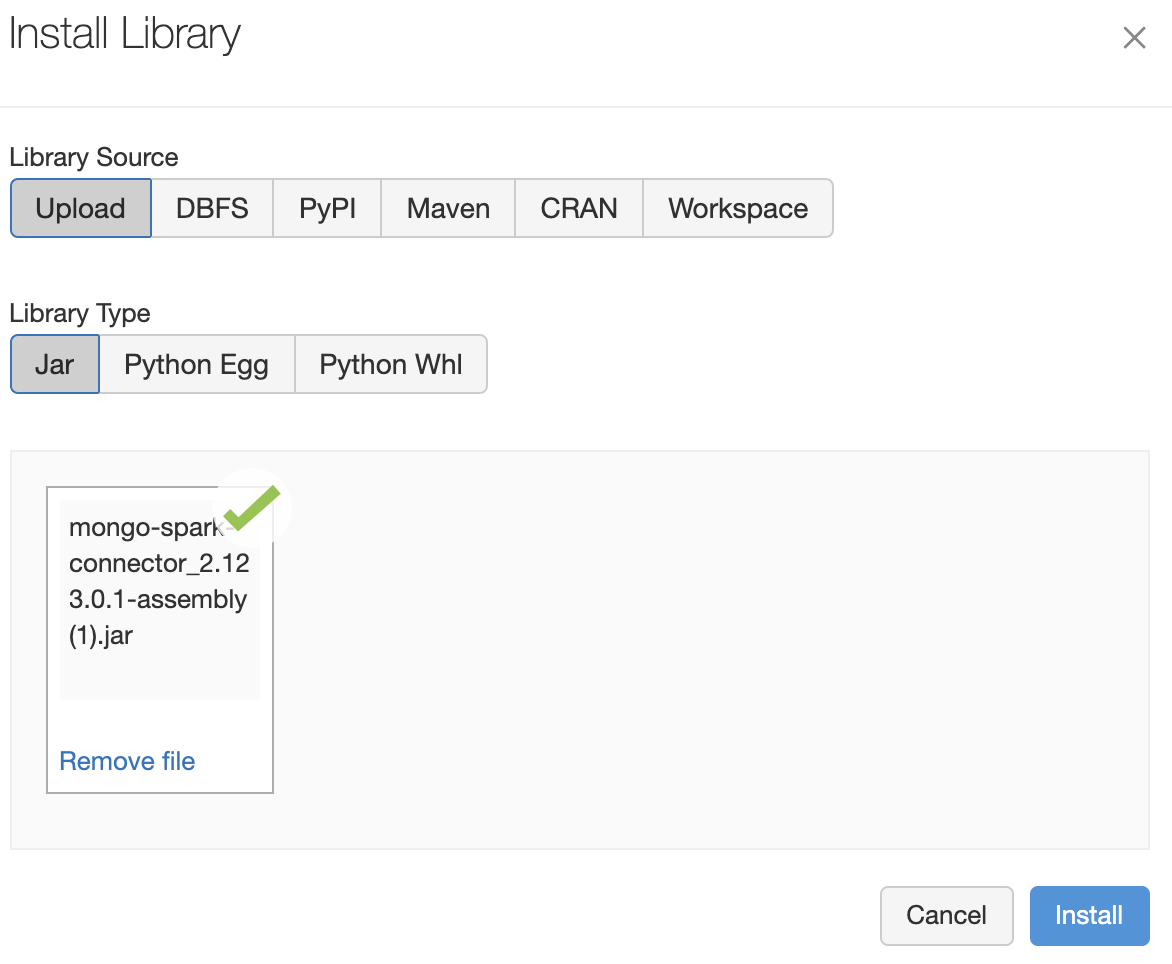
**注意:**如果你收到错误信息 "Maven库只支持Databricks Runtime 7.3 LTS版本,以及>=8.1版本",你可以从repo1.maven.org/maven2/org/… 下载MongoDB Spark Connector JAR文件 ,然后通过使用Upload菜单选项将其上传到Databricks:
创建一个新的笔记本
点击菜单中的Databricks主页图标,选择 "创建一个空白笔记本":
将这个新的笔记本附加到你在上一步创建的集群上:
因为我们将MongoDB连接字符串定义为Spark conf集群配置的一部分,所以你的笔记本已经有了MongoDB Atlas连接上下文。
在第一个单元格中,粘贴以下内容:
from pyspark.sql import SparkSession
pipeline="[{'$match': { 'items.name':'printer paper' }}, {'$unwind': { path: '$items' }}, {'$addFields': { totalSale: { \
'$multiply': [ '$items.price', '$items.quantity' ] } }}, {'$project': { saleDate:1,totalSale:1,_id:0 }}]"
salesDF =
spark.read.format("mongo").option("collection","sales").option("pipeline", pipeline).option("partitioner", "MongoSinglePartitioner").load()
运行该单元格以确保你能连接Atlas集群。
注意:如果你得到一个错误,如 "MongoTimeoutException",请确保你的MongoDB Atlas集群已经配置了适当的网络访问:

笔记本给了我们一个关于数据外观的模式视图。虽然我们可以在数据到达Spark之前继续在Mongo管道中转换数据,但让我们使用PySpark来转换它。创建一个新的单元格并输入以下内容:
from pyspark.sql.window import Window
from pyspark.sql import functions as F
salesAgg=salesDF.withColumn('saleDate',
F.col('saleDate').cast('date')).groupBy("saleDate").sum("totalSale").orderBy("saleDate")
w = Window.orderBy('saleDate').rowsBetween(-7, 0)
df = salesAgg.withColumn('rolling_average',
F.avg('sum(totalSale)').over(w))
df.show(truncate=False)
一旦代码被执行,笔记本将显示我们新的数据框架,其中有滚动平均数一栏:
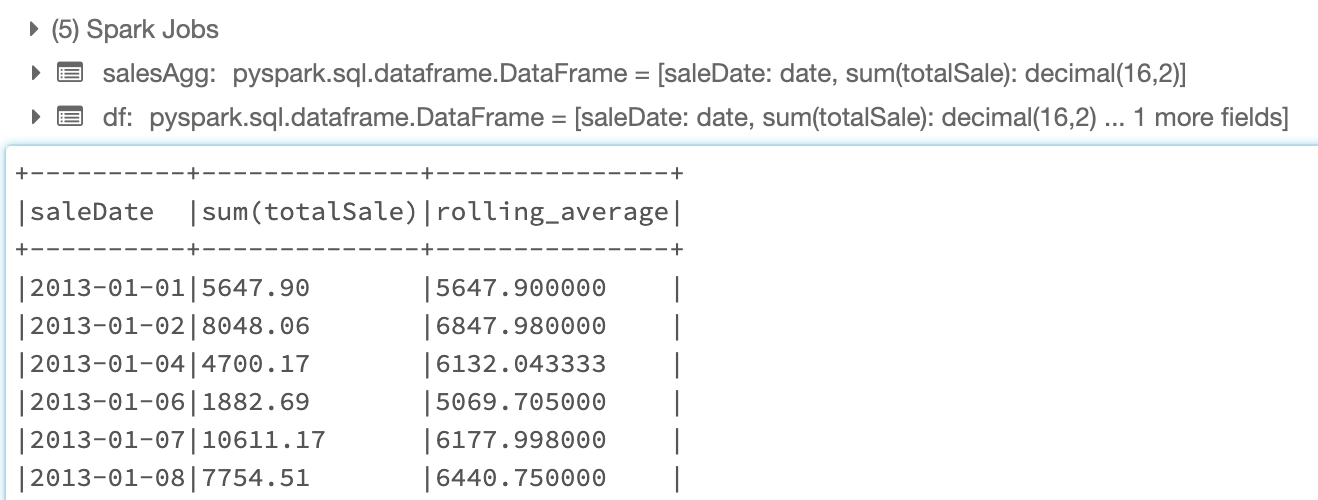
在这个单元格中,我们将提供一些额外的数据转换,如按销售日期分组,并提供每天总销售额的总和。一旦数据达到我们想要的格式,我们就定义一个时间窗口为过去的七个条目,然后在我们的数据框架中添加一列,该列是总销售数据的滚动平均值。
一旦我们进行了分析,我们就可以将数据写回MongoDB,用于额外的报告、分析或存档。在这种情况下,我们将数据写回一个名为sales-averages的新集合:
df.write.format("mongo").option("collection","sales-averages").save()
你可以通过使用MongoDB Atlas集群用户界面中的集合标签来查看数据:
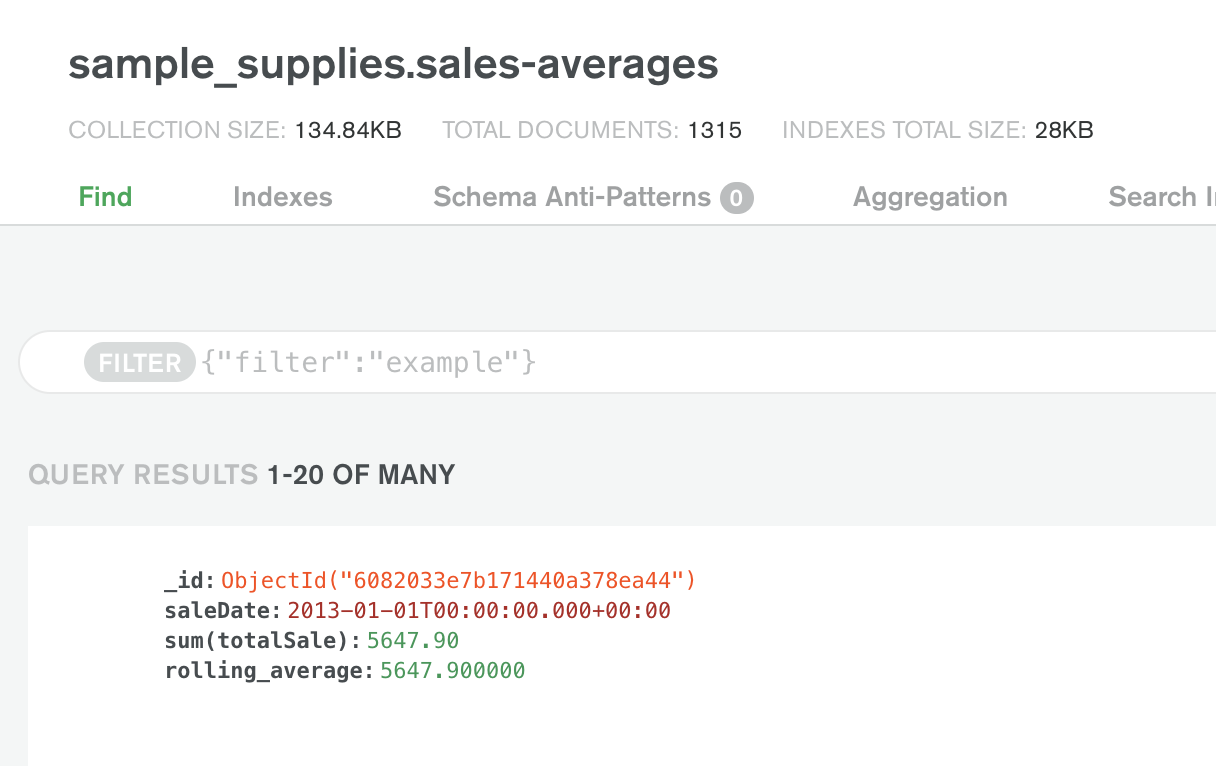
通过MongoDB Atlas中的数据,你现在可以利用许多可用的服务,包括Atlas在线存档、Atlas搜索和Atlas数据湖。
总结
MongoDB Atlas、谷歌云和Databricks之间的整合使你能够深入了解你的数据,并使你能够随着你的需求的变化自由地移动和分析数据。请查看下面的资源,了解更多信息。
