

我很高兴地宣布,Swift Collections 是一个新的开源包,专注于扩展可用的 Swift 数据结构集。与之前的Swift Algorithms和Swift Numerics包一样,我们发布 Swift Collections 是为了帮助孵化 Swift 标准库的新功能。
Swift 标准库目前实现了三个最基本的通用数据结构。Array,Set 和Dictionary 。这些都是适合各种使用情况的工具,它们特别适合作为货币类型使用。但有时,为了有效地解决一个问题或维护一个不变因素,Swift程序员会从一个更大的数据结构库中受益。
我们希望Collections 包能让你以更少的精力编写更快、更可靠的程序。
简要浏览
Collections 包的初始版本包含三个最常被要求的数据结构的实现:双端队列(简称 "deque")、有序集合和有序字典。
Deque
Deque(发音为 "deck")的工作原理与Array :它是一个有序的、随机访问的、可变的、范围可替换的、具有整数索引的集合。
与Array 相比,Deque 的主要好处是它支持两端的有效插入和删除。
这使得deque在我们需要一个先入先出的队列时成为一个很好的选择。为了强调这一点,Deque 提供了方便的操作来在两端插入和弹出元素:
var colors: Deque = ["red", "yellow", "blue"]
colors.prepend("green")
colors.append("orange")
// `colors` is now ["green", "red", "yellow", "blue", "orange"]
colors.popFirst() // "green"
colors.popLast() // "orange"
// `colors` is back to ["red", "yellow", "blue"]
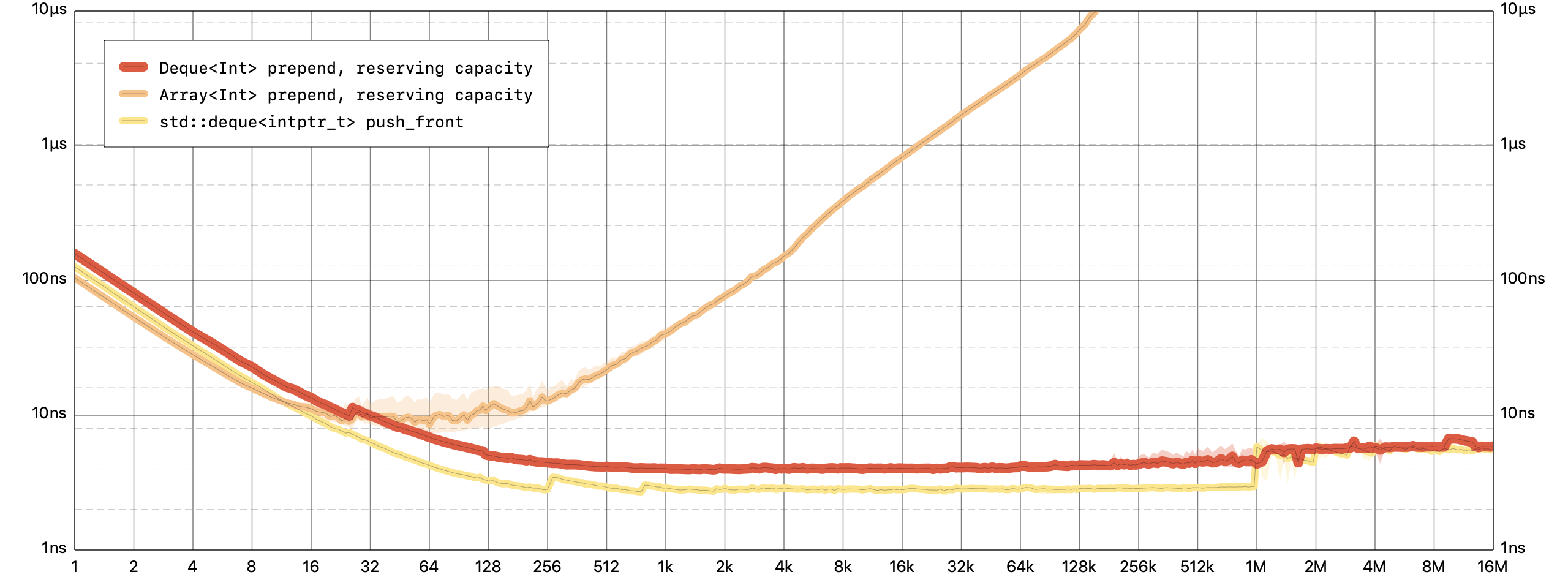
对于
Deque,预置一个元素是一个恒定的时间操作,但是对于Array,则是一个线性时间操作。注意:所有的图表都是以对数尺度绘制每个元素的平均处理时间。越低越好。这些基准是在我的2017 iMac Pro上运行的。
当然,我们也可以使用任何熟悉的MutableCollection 和RangeReplaceableCollection 方法来访问和改变集合的元素。索引的工作方式与Array 中的完全一样--第一个元素总是在索引0处:
colors[1] // "yellow"
colors[1] = "peach"
colors.insert(contentsOf: ["violet", "pink"], at: 1)
// `colors` is now ["red", "violet", "pink", "peach", "blue"]
colors.remove(at: 2) // "pink"
// `colors` is now ["red", "violet", "peach", "blue"]
colors.sort()
// `colors` is now ["blue", "peach", "red", "violet"]
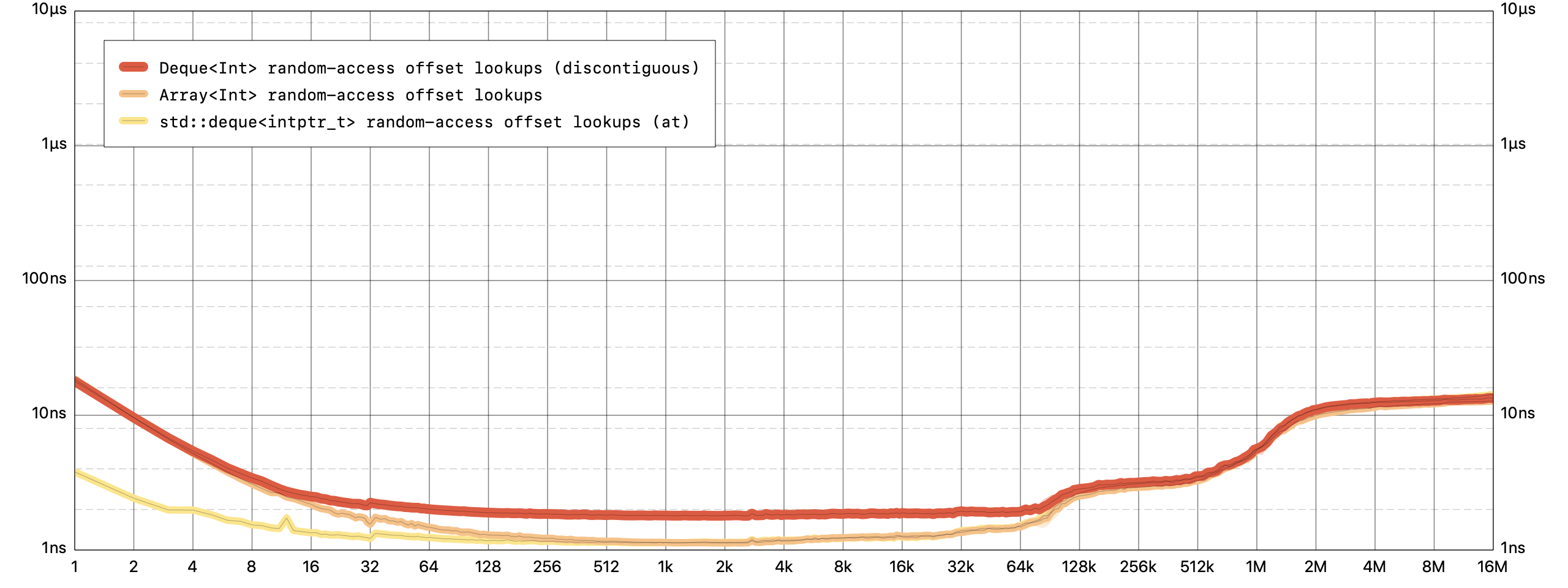
像
Array,在一个任意偏移处访问一个元素对于Deque,是一个恒定的时间操作。
为了支持前面的有效插入,deques需要放弃在一个连续的缓冲区中维护他们的元素。这使得它们在不需要在前面插入/移除元素的情况下比数组的工作速度略慢--所以盲目地用deques来取代所有的数组可能不是一个好主意。
有序集合
OrderedSet是一个强大的Array 和Set 的混合体。
我们可以用任何符合Hashable 协议的元素类型创建一个有序集合。
let buildingMaterials: OrderedSet = ["straw", "sticks", "bricks"]
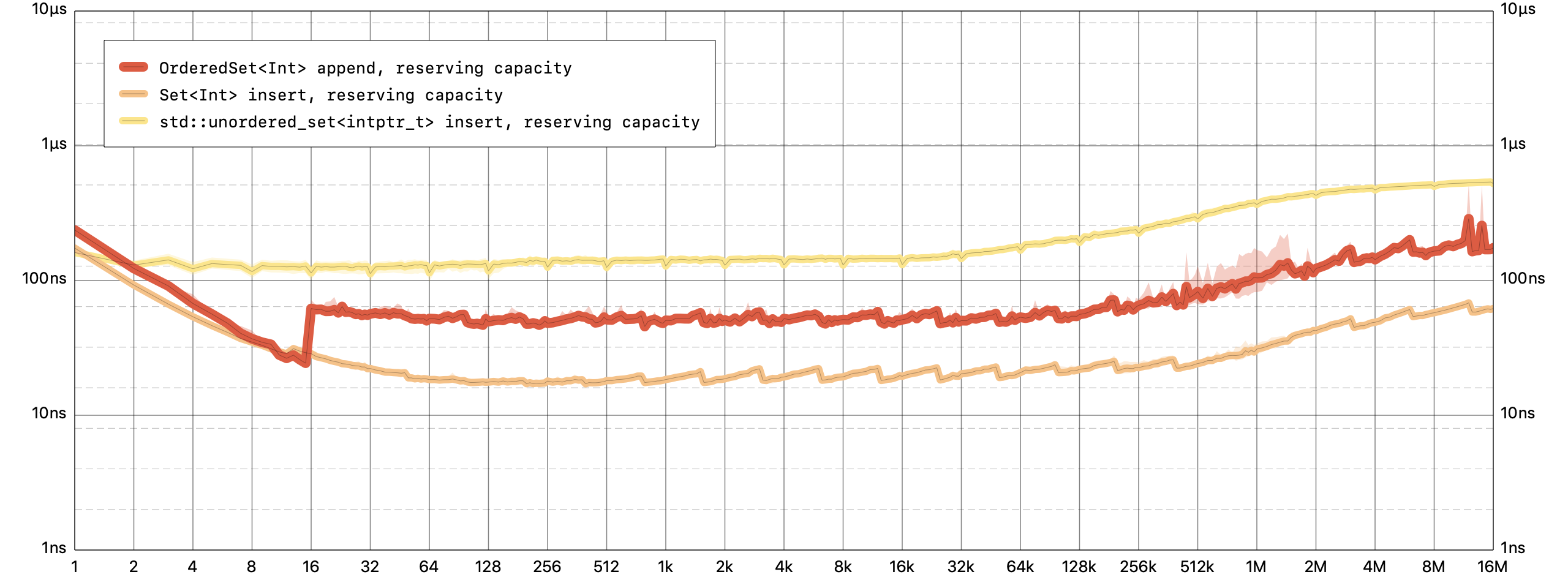
添加一个元素,包括确保它是唯一的,对于
OrderedSet,是一个恒定的时间操作。注意:所有的基准都将
std::unordered_set和std::unordered_map配置为使用与 Swift 相同的哈希函数,以便进行同类比较。
与Array 一样,有序集以用户指定的顺序保持其元素,并支持对其成员的高效随机访问遍历:
for i in 0 ..< buildingMaterials.count {
print("Little piggie #\(i) built a house of \(buildingMaterials[i])")
}
// Little piggie #0 built a house of straw
// Little piggie #1 built a house of sticks
// Little piggie #2 built a house of bricks
像Set ,有序集确保每个元素只出现一次,并提供高效的成员测试:
buildingMaterials.append("straw") // (inserted: false, index: 0)
buildingMaterials.contains("glass") // false
buildingMaterials.append("glass") // (inserted: true, index: 3)
// `buildingMaterials` is now ["straw", "sticks", "bricks", "glass"]
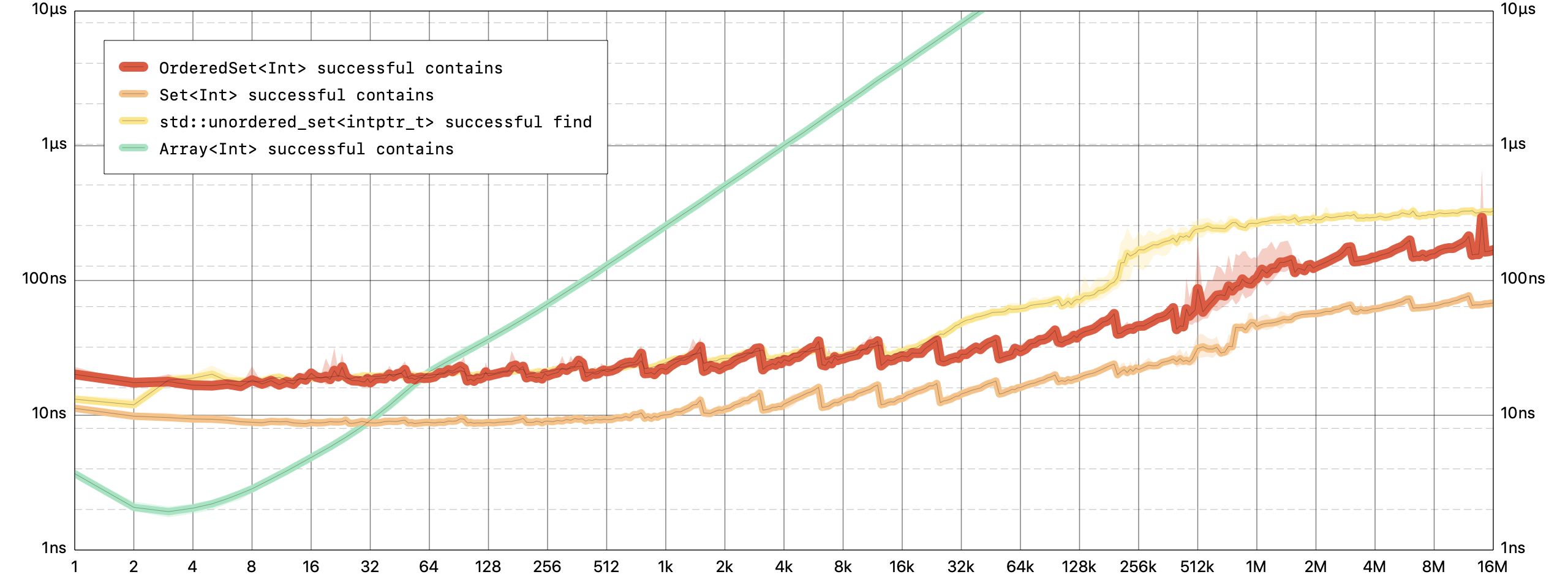
对于
OrderedSet,成员测试是一个恒定的时间操作,但对于Array,是一个线性时间操作。
OrderedSet 使用标准数组值来存储元素,可以用最小的开销来提取。如果我们想把一个有序集合的内容传递给一个只接受 (或对 或 )的函数,这是一个很好的选择。Array RangeReplaceableCollection MutableCollection
func buildHouses(_ houses: Array<String>)
buildHouses(buildingMaterials) // error
buildHouses(buildingMaterials.elements) // OK
对于需要符合SetAlgebra 的情况,OrderedSet提供了一个符合SetAlgebra 的有效的无序元素视图:
func blowHousesDown<S: SetAlgebra>(_ houses: S) { ... }
blowHousesDown(buildingMaterials) // error: `OrderedSet<String>` does not conform to `SetAlgebra`
blowHousesDown(buildingMaterials.unordered) // OK
OrderedSet 还实现了 和 的一些功能,以及 的大部分功能。(成员的唯一性和顺序敏感的平等性阻止了完全的一致性。)RangeReplaceableCollection MutableCollection SetAlgebra
这是通过维护一个成员数组(用于有效的随机访问遍历)和一个数组索引的哈希表(用于有效的成员测试)来实现的。因为存储在哈希表内的索引通常可以被编码成比标准Int 更少的比特,所以OrderedSet 通常会比一个普通的老Set 使用更少的内存!
有序字典(OrderedDictionary
OrderedDictionary当元素的顺序很重要或者我们需要有效地访问集合中不同位置的元素时,它是Dictionary 的一个有用的替代品。
我们可以用符合Hashable 协议的任何键类型来创建一个有序字典:
let responses: OrderedDictionary = [
200: "OK",
403: "Forbidden",
404: "Not Found",
]
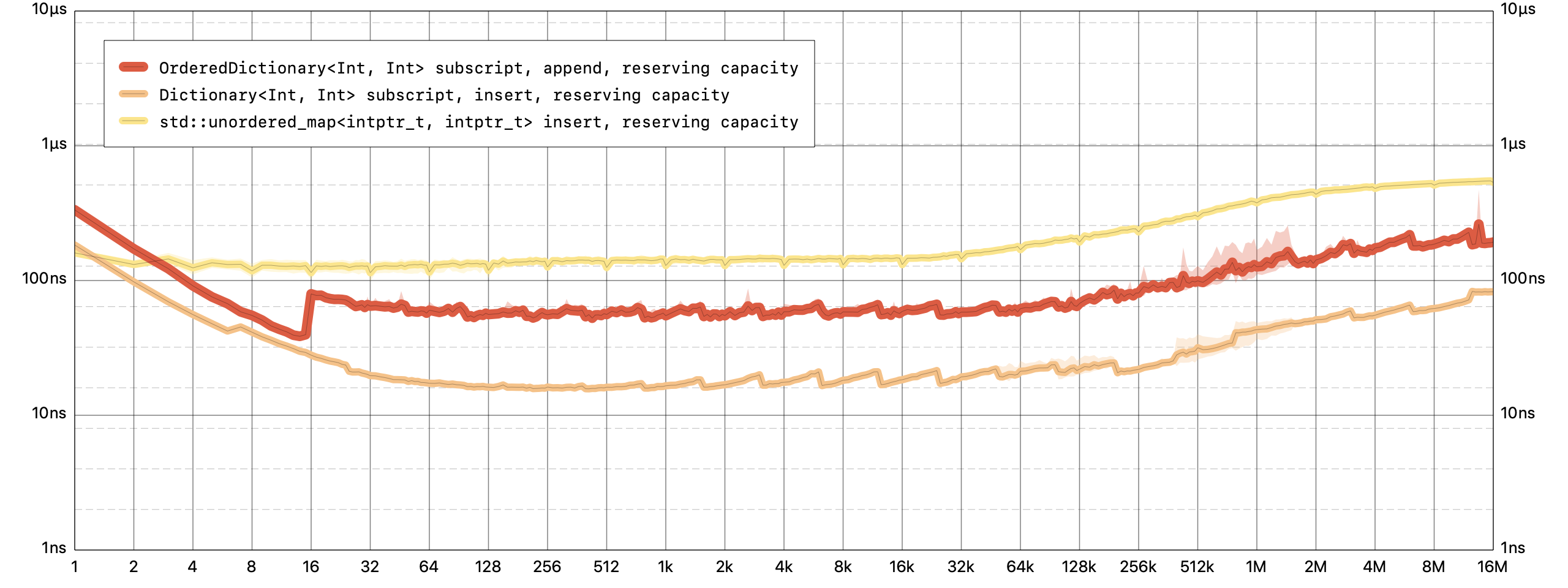
在
OrderedDictionary中插入一个新的键值对,会以恒定的时间将其追加。
OrderedDictionary 有序字典提供了许多与 相同的操作。例如,我们可以使用熟悉的基于键的下标有效地查询和添加值。Dictionary
responses[200] // "OK"
responses[500] = "Internal Server Error"
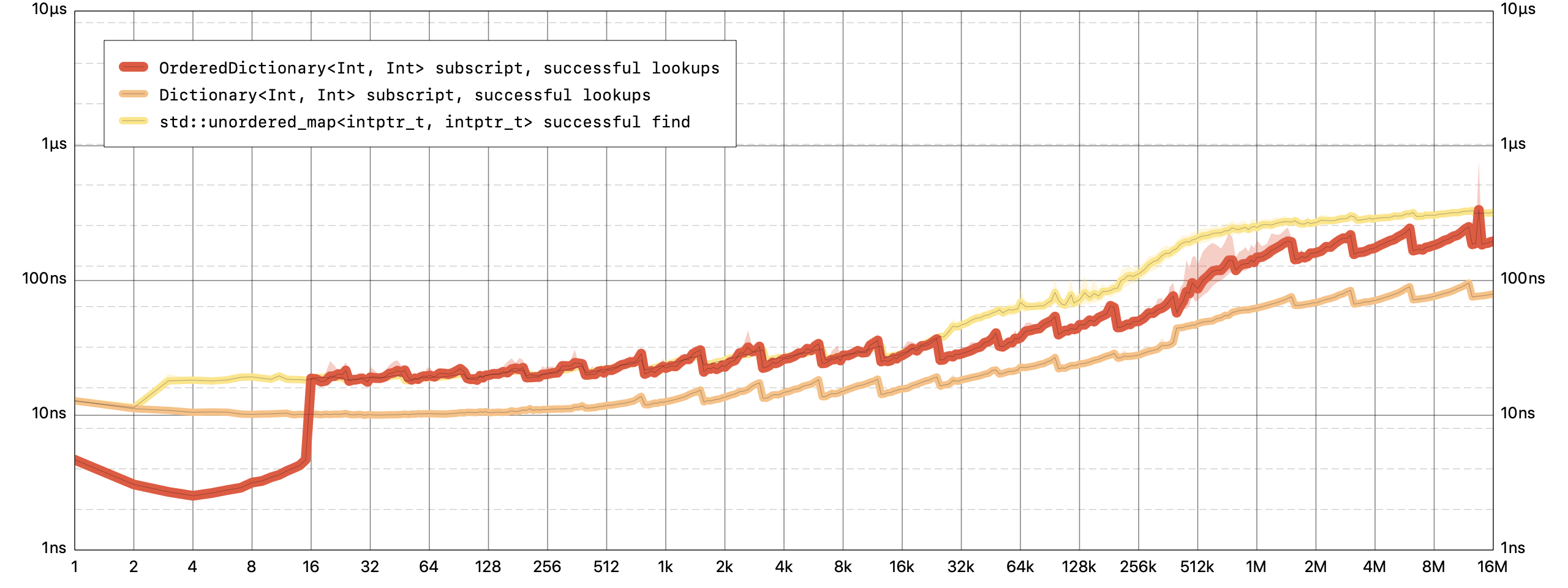
对于
OrderedDictionary,查询一个键的值是一个恒定的时间操作。
如果使用 subscript setter 添加一个新条目,它就会被附加到 dictionary 的末尾。所以默认情况下,dictionary 包含的元素是按照它们最初插入的顺序:
for (code, phrase) in responses {
print("\(code) (\(phrase))")
}
// 200 (OK)
// 403 (Forbidden)
// 404 (Not Found)
// 500 (Internal Server Error)
OrderedDictionary 使用整数索引,第一个元素总是从 开始。为了避免基于键和基于索引的下标之间的歧义, 并不直接符合 。相反,它提供了一个对其键值对的随机访问视图。0 OrderedDictionary Collection
responses[0] // nil (key-based subscript)
responses.elements[0] // (200, "OK") (index-based subscript)
像标准的Dictionary ,OrderedDictionary 也提供轻量级的keys 和values 视图。同一个索引可以在字典提供给它的内容的所有视图中移植:
if let i = responses.index(forKey: 404) {
responses.keys[i] // 404
responses.values[i] // "Not Found"
responses.remove(at: i + 1) // (500, "Internal Server Error")
}
// `responses` is now [200: "OK", 403: "Forbidden", 404: "Not Found"]
OrderedDictionary 实现了 和 的一些功能,尽管它对成员唯一性的要求使它不能实现对这两个协议的完全一致性。MutableCollection RangeReplaceableCollection
一个有序的字典由一个OrderedSet 的键组成,同时还有一个包含其相关值的常规Array 。每一个都能以最小的开销被提取出来,这是与期望某种类型的函数进行交互的有效选择。
与 Swift 标准库的关系
我们对标准库的期望是包括一套丰富、实用的通用数据结构。
与Swift Numerics和Swift Algorithms 等包类似,Collections 包的一个重要目标是作为新数据结构实现的(相对)低摩擦试验场,然后再通过常规的 Swift 进化过程将其作为官方库的补充。
我们以包的形式使用这些结构获得的经验将为最终的审查讨论提供参考。这也将为我们提供一个机会,在任何设计问题被刻在石头上之前,对其进行修正。
Collections 包在某种程度上是对向 Swift 贡献新数据结构所涉及的挑战的认可。因为标准库是ABI稳定的,所以必须花大量时间考虑数据结构的哪些部分会被@frozen ,哪些不会,以及哪些方法应该被@inlinable ,并触及这些冻结的内部结构。
因此,Collections 包不仅仅是一组数据结构。它也是一个为那些想了解ABI设计的黑暗艺术的贡献者提供的水坑,以及一个复杂的工具包,以帮助满足数据结构所要求的正确性和效率的高标准。
然而,仅仅因为一个补充可能是列入Collections 包的良好候选者,它不需要在那里开始它的生命。这并不是对Swift进化过程的改变。尽管对新数据结构的要求很高,但得到良好支持的提案将一如既往地得到考虑。
贡献标准
这个包的近期重点是孵化一套实用的生产级数据结构--类似于你可能在C++容器库或Java集合框架中找到的那些。
要成为Collections 包的良好候选者,一个数据结构应该能明显改善真实世界的 Swift 代码的性能或正确性,而且其实现策略应该考虑到现代计算机架构和 Swift 的性能特征。
Collections 包并不打算成为数据结构的全面分类法。有许多经典的数据结构不值得列入,因为它们比标准库中的现有类型提供的价值不够,或者因为存在具有卓越实现策略的替代品。(例如,我们不太可能想实现链表或红黑树--同样的利基可能会被高扇形搜索树(如内存B树)更好地填补。
由于这个包的重点是提供生产级的数据结构实现,所以对收录的标准很高。一些评估贡献的基线标准:
-
可靠性:实现必须正确地工作,没有任何未处理的边缘情况,并且必须在面对未来的语言、编译器和标准库变化时继续工作。
为了帮助这项工作,该软件包包括对编写组合回归测试的支持,以及一个针对语义协议要求的半自动一致性检查库。
-
运行时性能:实现必须在所有实际工作集上表现出最佳性能,从单一元素到数千万元素。这不仅仅是指渐进的性能--常数因素也很重要!这也是我们的目标。
该软件包带有一个精心设计的基准测试模块,可用于在所有可能的工作集大小上进行操作。我们就是用它来创建这篇博文中的基准的。我们可以用它来识别需要优化工作的领域,并根据硬数据来评估潜在的优化。
-
内存开销:内存是一种稀缺资源;我们实现的数据结构不应该在存储内部指针、填充字节、未使用的容量或类似的赘肉上花费太多的内存。一旦我们决定了一个实现策略,我们就应该采用书中的每一个技巧来最大限度地减少内存的使用!
