

在Grafana实验室,当我们为Grafana Cloud构建集成时,我们经常会考虑如何帮助用户开始他们的观察之旅。我们喜欢把一些注意力集中在你在路上可能遇到的不同技术上。这样,我们就可以在你使用Grafana产品时分享我们关于与它们互动的最佳方式的提示。
在这篇文章中,我将专注于开源的分布式存储系统Ceph,这是我们在Grafana云(包括永久免费层)中提供的最新集成。
基础知识
Ceph在单个分布式计算机集群上实现对象存储,然后为对象、块和文件级存储提供三合一接口。其目标是提供一个完全分布式的操作,没有单点故障,这使你有可用性和选择扩展。
为了实现这些目标,重要的是集群有每个核心组件的冗余节点,即OSD(对象存储代理)和MDS(元数据服务器代理)。这可以确保数据在多个节点上进行复制,因此,如果一个节点发生故障,你就不会丢失数据。这同样适用于元数据节点,它们控制着你的集群的整体配置。
也就是说,为了正确地监控一个Ceph集群,我们必须关注这两个核心组件,这是一个尖锐的部署的关键。
观察Ceph
这个集成基于内置的Prometheus插件来监控一个Ceph集群。
首先,在你的集群中用以下命令启用它:
*ceph mgr module enable prometheus*
然后,你需要配置Grafana代理来搜刮你的Ceph节点。(请参考这里的集成文档以了解更多细节)。
该集成是由一个单一的和完整的仪表板组成,它总结了一个Ceph集群的所有信息,一目了然。它包括整体集群信息,包括OSD和监控器节点的数量上升/下降;字节和写/读和写/读吞吐率;IOPS;集群可用;使用和整体容量;延迟货币率和分布;等等。
下面是完整的仪表盘的样子(分四块):
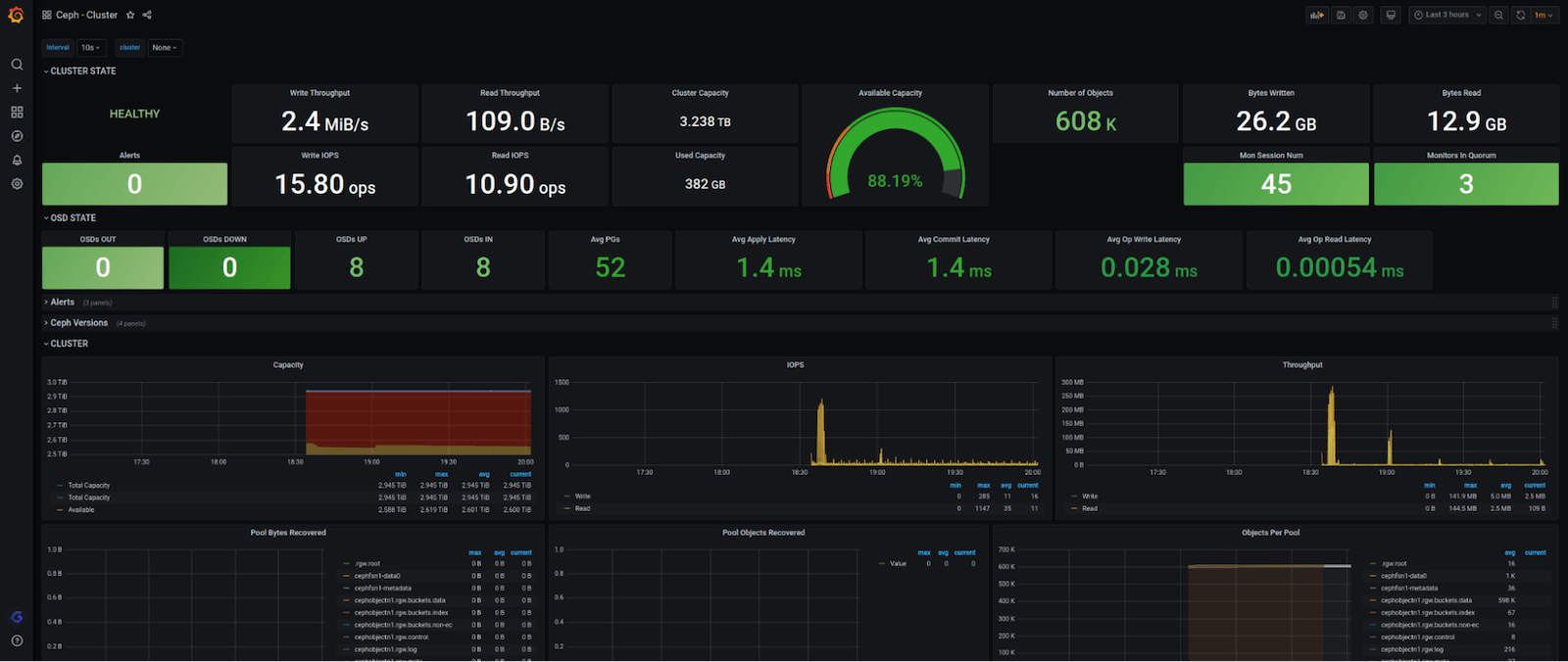
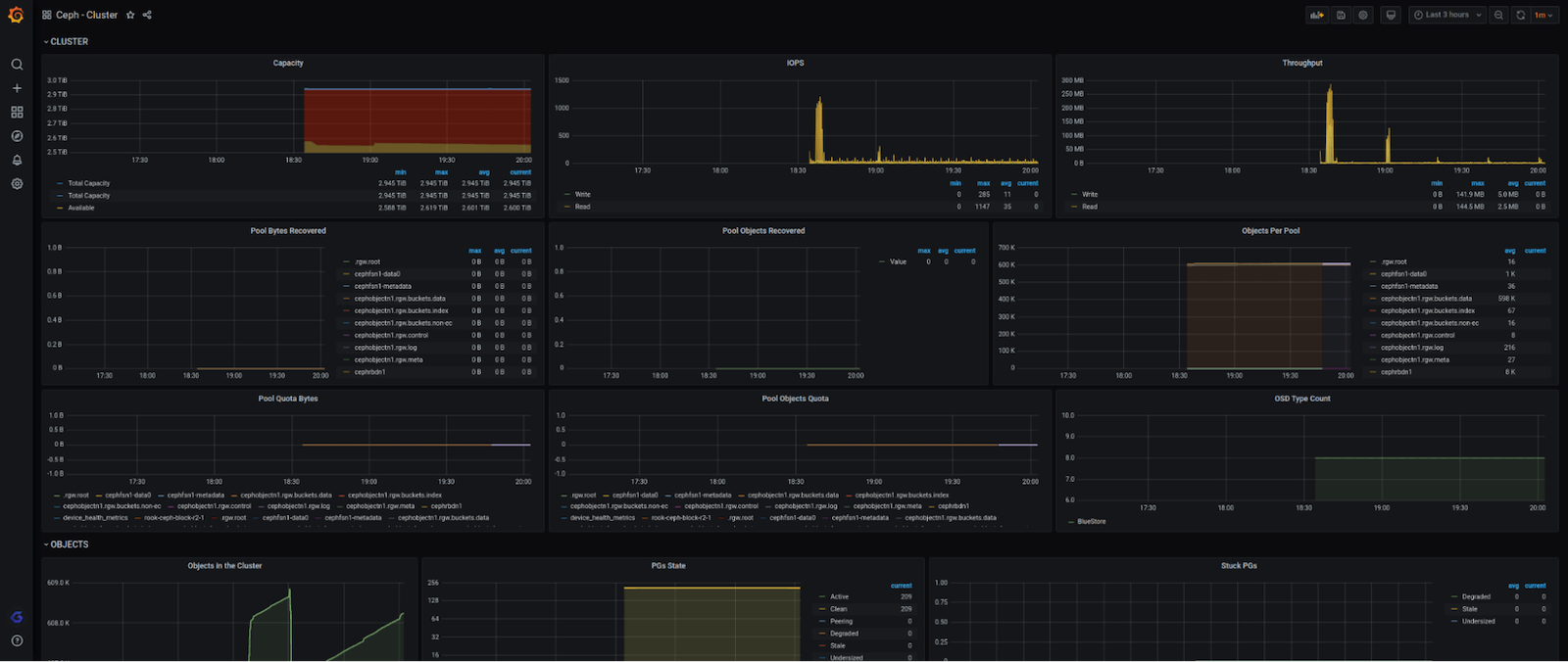
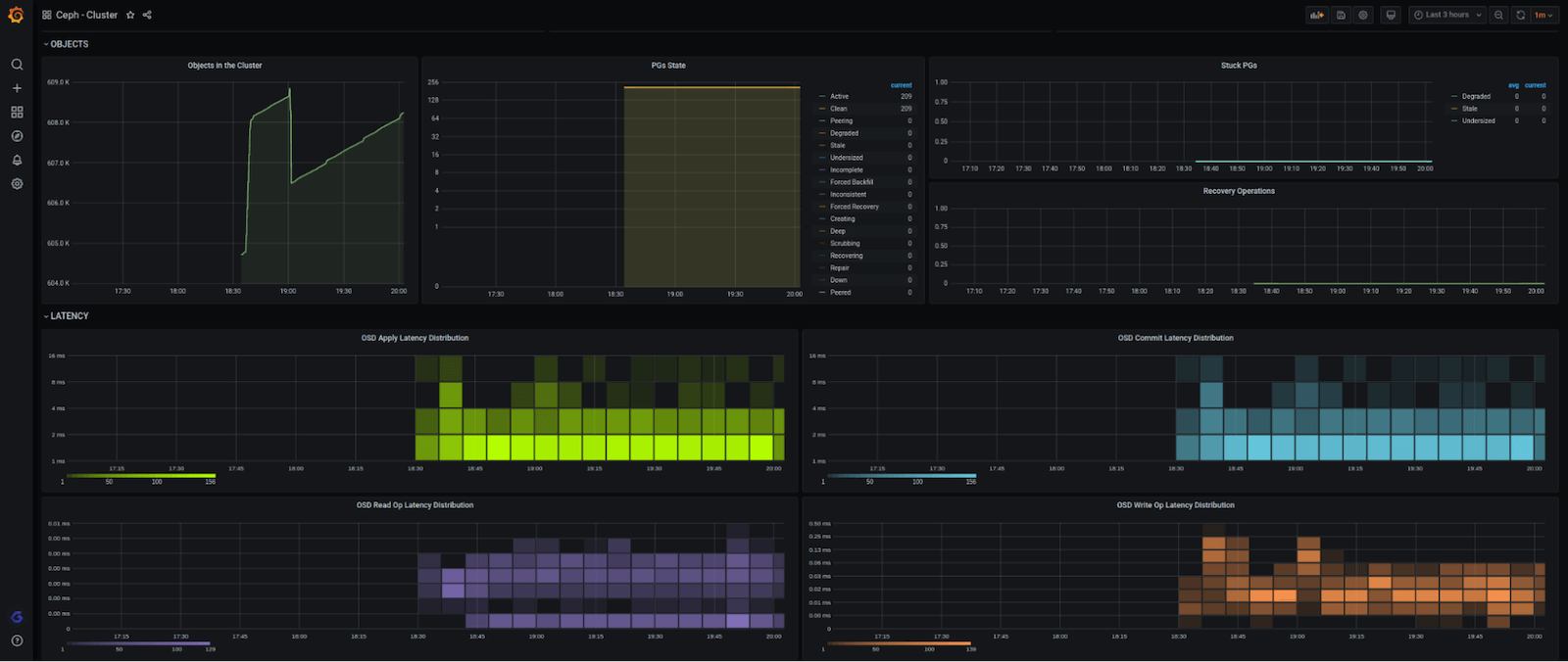
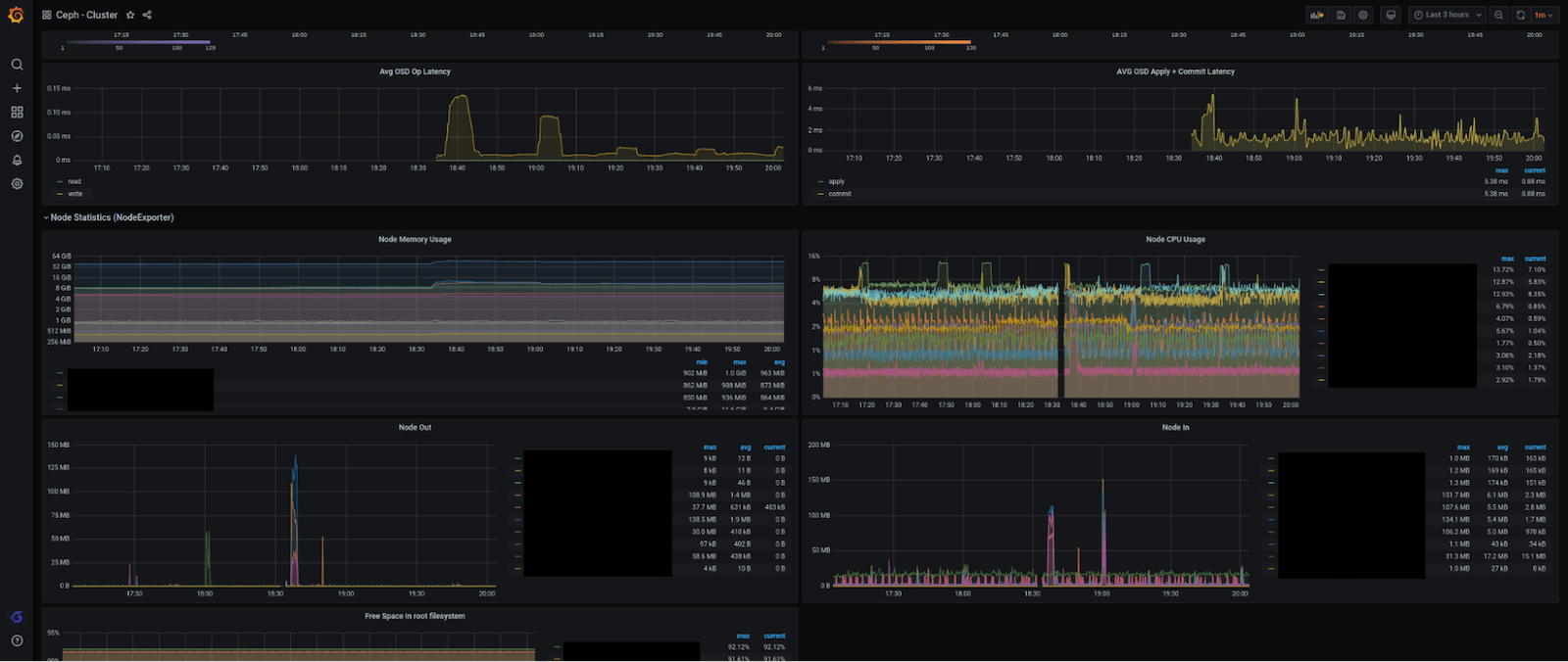
我们还想确保当你的集群出现问题时,你能得到通知,所以我们创建了这些警报:
- CephUnhealthy(基于整体健康度指标ceph_health_status - 如果这个指标不存在或它返回的东西与1不同,集群有关键问题)
- CephDiskLessThan15Left(如果集群中剩下的容量少于15%,就会发出警告)
- CephDiskLessThan5Left(如果集群中剩下的容量少于5%,就会发出关键警报)
- OSDNodeDown(如果任何OSD节点停机,发出警告)。
- MDSDown(如果集群中没有MDS可用,则发出危险警报)
与仪表盘一起,这些警报是一个非常好的方式,以即插即用的方式开始监控你的集群--它只需要你花几分钟的时间就可以让它加速,这是我们的主要目标。
