

LSMT 存储引擎浅析| 青训营笔记
这是我参与「第四届青训营 」笔记创作活动的的第14天
LSMT与存储引擎介绍
- LSMT是Log-Structured Merge-Tree的缩写,由Patrick O "Neil etc.在 1996 年的论文, The Log-Structured Merge-Tree(LSM-Tree),提出。
- 相较而言,B-Tree 出现就早得多了,在 1970 年由 Bayer, R.; McCreight, E.提出。
- 早期的数据库系统一般都采用 B-Tree 家族作为索引,例如 MySQL。2000年后诞生的数据库大多采用LSMT 索引1, 例如 Google BigTable, HBase, Canssandra 等。
- MySQL,PostgresQL 默认均采用 B+Tree(B-Tree 变种)索引。较新的数据库产品,如 TiDB,CockroachDB,默认均采用 LSMT 存储引擎(RocksDB / Pebble)。LSMT 和 B-Tree 看起来是一个时代的产物,其实二者差了 26 年。
LSMT 是什么?
一言以蔽之,通过 Append-only Write + 择机 Compact 来维护索引树的结构。
数据先写入 MemTable,MemTable 是内存中的索引可以用 SkipList / B+Tree 等数据结构实现。当 MemTable 写到一定阈值后,冻结,成为 ImmemTable,任何修改只会作用于 MemTable,所以 ImmemTable 可以被转交给 Flush 线程进行写盘操作而不用担心并发问题。Flush 线程收到 ImmemTable ,在真正执行写盘前,会进一步从 ImmemTable 生成 SST(Sorted String Table),其实也就是存储在硬盘上的索引,逻辑上和 ImmemTable 无异。
新生成的 SST 会存放于 L0(Layer 0),除了 L0 以外根据配置可以一直有 Ln。SST 每 Compact 一次,就会将 Compact 产物放入下一层。Compact 可以大致理解为 Merge Sort,就是将多个 SST 去掉无效和重复的条目并合并生成新的 SST 的过程。Compact 策略主要分为 Level 和 Tier 两种,会在课中进行更详细的描述。
存储引擎是什么?
以单机数据库MySQL为例,大致可以分为:
- 计算层
- 存储层(存储引擎层)
计算层主要负责SQL 解析/ 查询优化/计划执行。
数据库著名的ACID 特性,在 MySQL 中全部强依赖于存储引擎。
- Atomicity: Write-Ahead Log(WAL) / Redo Log
- Consistency(Correctness): 依赖于数据库整体
- lsolation: Snapshot/2PL(Phase Lock)
- Durability: Flusher 遵循 Sync 语意
除了保障 ACID 以外,存储引擎还要负责:
- 屏蔽 IO 细节提供更好的抽象
- 提供统计信息与 Predicate Push Down 能力
存储引擎不掌控 IO 细节,让操作系统接管,例如使用 mmap ,会有如下问题:
- 落盘时机不确定造成的事务不安全
- IO Stall
- 错误处理繁琐
- 无法完全发挥硬件性能
LSMT 存储引擎的优势与实现
LSMT 与 B+Tree 的异同
**B+Tree: **
有一 Order 为 5 的 B+Tree,目前存有 (10, 20, 30, 40),继续插入 15,节点大小到达分裂阈值 5,提取中位数 20 放入新的内部节点,比 20 大的 (30, 40) 移入新的叶节点。这个例子虽然简单,但是涉及了 B+Tree 最核心的两个变化,插入与分裂。
- 在B+Tree 中,数据插入是原地更新的
- B+Tree 在发生不平衡或者节点容量到达阈值后,必须立即进行分裂来平衡。装有 (10, 20, 30, 40) 的节点在插入和分裂后,原节点覆写成 (10, 15)。此外,B+Tree 在发生不平衡或者节点容量到达阈值后,必须立即进行分裂来平衡。
- 反观 LSMT,数据的插入是追加的(Append-only),当树不平衡或者垃圾过多时,有专门 Compact 线程进行 Compact,可以称之为延迟(Lazy)的。
LSMT 与 B+Tree可以用统一模型描述
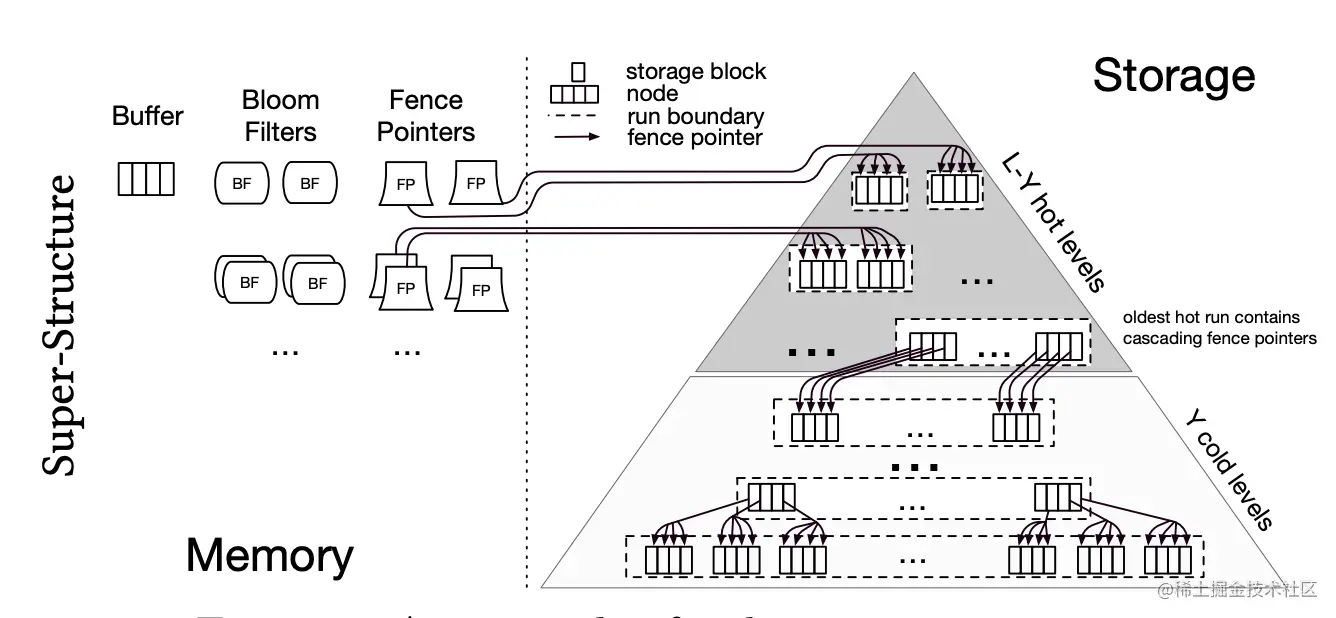
- 从高层次的数据结构角度来看,二者没有本质的不同,可以互相转化,根据 Workload 的不同互相转换。
- 工程实践上还是用 LSMT来表示一个Append-only 和 Lazy Compact 的索引树,B+Tree来表示一个 Inplace-Update和Instant Compact 的索引树。
- Append-only 和 Lazy Compact这两个特性更符合现代计算机设备的特性。
B+Tree 中内部节点指向其它节点的指针,被称之为 Fence Pointers。在 LSMT 也有,只不过是隐式表达的。B+Tree 直接通过 Fence Pointer 一层一层往下找,而 LSMT 是有一个中心的 Meta 信息记录所有 SST 文件的 Key 区间,通过区间大小关系,一层一层向下找。
再看 LSMT 的 SST,其实和 B+Tree 的 Node 也没有本质差别,逻辑上就是一个可查询的有序块,统一模型中称之为 Run。B+Tree 为了支持随机修改,结构会比较松散和简单,LSMT 则因为不需要支持随机修改,利用压缩技术,结构可以更紧凑。
为什么要采用 LSMT 模型?
All problems in computer science can be solved by another level of indirection
From Butler Lampson
在计算机存储乃至整个工程界都在利用 Indirection 处理资源的不对称性,比方说内存价格上升了,就要想办法 offload 数据到别的廉价介质上。存储引擎面对的资源不对称性在不同时期是不同的。
- HDD 时代:顺序操作和随机操作的不对称性,由于机械硬盘需要磁盘旋转和机械臂移动来进行读写,工程上一般估计机械硬盘的点查(主要开销是 Seek 寻道)延迟是 1ms,顺序写吞吐是随机读的 25 倍。
- SSD 时代:顺序写和随机写的不对称性,由于SSD随机写会给主控带来GC 压力,顺序写吞吐是随机写的 6 倍。
SSD 是基于 NAND Flash 颗粒的构建的,称之为 DIE,DIE 上有多个 Plane,每个 Plane 能单独提供读写能力,Plane 包含多个 Block,Block 包含多个 Page。擦除的电路实现比较复杂,出于成本的考量,写入的最小单位是 Page,而擦除的最小单位是 Block。
随着用户不断写入和删除,有可能出现有很多 Page 已经被删除了,逻辑上有可用空间,但是物理上 Block 还有别的有效 Page,无效 Page 无法回收。这样用户就写不进数据了。因此,SSD 主控必须执行 GC(Garbage Collection),将有效的 Page 从要回收的 Block 中挑出来,写到另一个 Block 上,再整体回收旧 Block。因此如果用户长期都是随机写,大量 Block 都会处于一部分 Page 是有效,一部分 Page 是无效的状态,SSD 主控不得不频繁 GC。
这二者的共性是顺序写是一个对设备很友好的操作,LSMT 符合这一点,而 B+Tree 依赖原地更新,导致随机写。
LSMT存储引擎的实现,以 RocksDB 为例
RocksDB 是一款十分流行的开源 LSMT 存储引擎,最早来自 Facebook(Meta),应用于 MyRocks,TiDB,在字节内部也有 Abase,ByteKV,ByteNDB,Bytable 等用户。因此接下来将会以 RocksDB 为例子介绍 LSMT 存储引擎的经典实现。
Write
- RocksDB 写入流程主要有两个优化,批量 WAL写入(继承自LevelDB)与并发 MemTable更新
- RocksDB 在真正执行修改之前会先将变更写入 WAL, WAL 写成功则写入成功。
为了确保操作的原子性,RocksDB 在真正执行修改之前会先将变更写入 WAL(Write Ahead Log),WAL 写成功则写入成功。因为即使这时候程序 crash,在重启阶段可以通过回放 WAL 来恢复或者继续之前的变更。操作只有成功和失败两种状态。
RocksDB WAL 写入流程继承自 LevelDB。LevelDB 在 WAL 写入主要做的一个优化是多个写入者会选出一个 Leader,由这个 Leader 来一次性写入。这样的好处在于可以批量聚合请求,避免频繁提交小 IO。
但很多业务其实不会要求每次 WAL 写入必须落盘,而是写到 Kernel 的 Page Cache 就可以,Kernel 自身是会聚合小 IO 再下刷的。这时候,批量提交的好处就在于降低了操作系统调度线程的开销。
批量提交时,Leader 可以同时唤醒其余 Writer。
- 多个写入者会选出一个 Leader,由这个Leader来一次性写入 WAL,避免小IO。
- 不要求WAL强制落盘 (Sync)时,批量提交亦有好处,Leader 可以同时唤醒其余Writer,降低了系统线程调度开销。
如果没有批量提交就只能链式唤醒了,链式唤醒加大前台延迟。
写完 WAL 实际还要写 MemTable,这步相比于写 WAL 到 Page Cache 更耗时而且是可以完全并行化的。RocksDB 在 LevelDB 的基础上主要又添加了并发 MemTable 写入的优化,由最后一个完成 MemTable 写入的 Writer 执行收尾工作。完整 RocksDB 写入流程如下:
RocksDB 为了保证线性一致性,必须有一个 Leader 分配时间戳,每条修改记录都会带着分配到的时间戳,也必须有一个 Leader 推进当前可见的时间戳。目前的写入流程已经相当优化了。
- WAL 一次性写入完成后,唤醒所有Writer 并行写入MemTable
- 由最后一个完成 MemTable写入的writer执行收尾工作
Snapshot & SuperVision
- RocksDB 的数据由 3 部分组成,MemTable / ImmemTable / SST。直接持有这三部分数据并且提供快照功能的组件叫做 SuperVersion。
- RocksDB 的 MemTable 和 SST 的释放与删除都依赖于引用计数,SuperVersion 不释放,对应的 MemTable 和 SST 就不会释放。对于读取操作来说,只要拿着这个 SuperVersion,从 MemTable 开始一级一级向下,就能查询到记录。那么拿着 SuperVersion 不释放,等于是拿到了快照。
如果所有读者开始操作前都给 SuperVersion 的计数加 1,读完后再减 1,那么这个原子引用计数器就会成为热点。CPU 在多核之间同步缓存是有开销的,核越多开销越大。
一般工程上可以简单估计,核多了之后 CAS 同一个 cache line,性能不会超过 100W/s。为了让读操作更好的 scale,RocksDB 做了一个优化是 Thread Local SuperVersion Cache。
每个读者都缓存一个 SuperVersion,读之前检查下 SuperVersion 是否过期,如果没有就直接用这个 SuperVersion,不需要再加减引用计数器。如果 SuperVersion 过期了,读者就必须刷新一遍 SuperVersion。为了避免某一个读者的 Thread Local 缓存持有一个 SuperVersion 太久导致资源无法回收,每当有新的 SuperVersion 生成时会标记所有读者缓存的 SuperVersion 失效。
没有 Thread Local 缓存时,读取操作要频繁 Acquire 和 Release SuperVersion
有 Thread Local 缓存时,读取只需要检查一下 SuperVersion 并标记缓存正在使用即可,可以看出多核之间的交互就仅剩检查 SuperVersion 缓存是否过期了。
Get & BloomFilter
- RocksDB 的读取在大框架上和 B + Tree 类似,就是层层向下。
- 相对于 B +Tree, LSMT点查需要访问的数据块更多。为了加速点查,一般 LSMT 引擎都会在SST中嵌入 BloomFilter。例如 RocksDB 默认的 BlockBasedTable。BloomFilter 可以 100% 断言一个元素不在集合内,但只能大概率判定一个元素在集合内。
[1, 10] 表示这个索引块存储数据的区间在 1 - 10 之间。索引块可以是 MemTable / ImmemTable / SST,它们抽象上是一样的。查询 2,就是顺着标绿色的块往下。如果索引块是 SST,就先查询 BloomFilter,看数据是否有可能在这个 SST 中,有的话则进行进一步查询。
除了 BloomFilter 外,BlockBasedTable 还有额外两个值得提的实现。一个是两层索引:
浅黄部分是 DataBlock,绿色部分是 IndexBlock。DataBlock 记载实际数据,IndexBlock 索引 DataBlock。假如要查询 3,先从 IndexBlock 中找到 >= 3 的第一条记录是什么,发现是 4,对应的 value 是 data_block_0 的 offset,直接定位到 Data Block 0。然后可以在 Data Block 0 中进行搜索。
另一个是前缀压缩
// BlockBuilder generates blocks where keys are prefix-compressed:
//
// When we store a key, we drop the prefix shared with the previous
// string. This helps reduce the space requirement significantly.
// Furthermore, once every K keys, we do not apply the prefix
// compression and store the entire key. We call this a "restart
// point". The tail end of the block stores the offsets of all of the
// restart points, and can be used to do a binary search when looking
// for a particular key. Values are stored as-is (without compression)
// immediately following the corresponding key.
//
// An entry for a particular key-value pair has the form:
// shared_bytes: varint32
// unshared_bytes: varint32
// value_length: varint32
// key_delta: char[unshared_bytes]
// value: char[value_length]
// shared_bytes == 0 for restart points.
//
// The trailer of the block has the form:
// restarts: uint32[num_restarts]
// num_restarts: uint32
// restarts[i] contains the offset within the block of the ith restart point.
Compact
Compact 在 LSMT 中是将 Key 区间有重叠或无效数据较多的 SST 进行合并,以此来加速读取或者回收空间。Compact 策略可以分为两大类。
Level
Level 策略直接来自于 LevelDB,也是 RocksDB 的默认策略。每一个层不允许有 SST 的 Key 区间重合。当用户写入的 SST 加入 L0 的时候会和 L0 里区间重叠的 SST 进行合并。当 L0 的总大小到达一定阈值时,又会从 L0 挑出 SST,推到 L1,和 L1 里 Key 区间重叠的 SST 进行合并。Ln 同理。
由于在 LSMT 中,每下一层都会比上一层大 T 倍(可配置),那么假设用户的输入是均匀分布的,每次上下层的合并都一定是一个小 SST 和一个大 SST 进行 Compact。这个从算法的角度来说是低效的,增加了写放大,具体理论分析会在之后阐述,这里可以想象一下 Merge Sort。Merge Sort 要效率最高,就要每次 Merge 的时候,左右两边的数组都是一样大。
实际上,RocksDB 和 LevelDB 都不是纯粹的 Level 策略,它们将 L0 作为例外,允许有 SST Key 区间重叠来降低写放大。
Tier
Tier 策略允许 LSMT 每层有多个区间重合的 SST,当本层区间重合的 SST 到达上限或者本层大小到达阈值时,一次性选择多个 SST 合并推向下层。Tier 策略理论上 Compact 效率更高,因为参与 Compact 的 SST 大小预期都差不多大,更接近于完美的 Merge Sort。
Tier 策略的问题在于每层的区间内重合的 SST 越多,那么读取的时候需要查询的 SST 就越多。Tier 策略是用读放大的增加换取了写放大的减小。
LSMT 模型理论分析
Cloud-Native LSMT Storage Engine - Hbase
RocksDB 是单机存储引擎,那么现在都说云原生,HBase 比 RocksDB 就更「云」一些,SST 直接存储于 HDFS 上,Meta 信息 RocksDB 自己管理维护于 Manifest 文件,HBase 放置于 ZK。二者在理论存储模型上都是 LSMT。
LSMT 模型算法复杂度分析
- T: size ratio,每层 LSMT 比上一层大多少,L0 大小为 1,则 L1 大小为 T,L2 为 T^2,以此类推
- L: level num,LSMT 层数
- B: 每个最小的 IO 单位能装载多少条记录
- M: 每个 BloomFilter 有多少 bits
- N: 每个 BloomFilter 生成时用了多少条 Key
- 是 BloomFilter 的 false positive rate
- S:区间查询的记录数量
Level
- Write:每条记录抵达最底层需要经过 L 次 Compact,每次 Compact Ln 的一个小 SST 和 Ln+1 的一个大 SST。设小 SST 的大小为 1,那么大 SST 的大小则为 T,合并开销是 1+T,换言之将 1 单位的 Ln 的 SST 推到 Ln+1 要耗费 1+T 的 IO,单次 Compact 写放大为 T。每条记录的写入成本为 1/B 次最小单位 IO。三者相乘即得结果。
- Point Lookup:对于每条 Key,最多有 L 个重叠的区间,每个区间都有 BloomFilter,失效率为,只有当 BloomFilter 失效时才会访问下一层。因此二者相乘可得读取的开销。注意,这里不乘 1/B 的原因是写入可以批量提交,但是读取的时候必须对齐到最小读取单元尺寸。
Tier
-
Write:每条记录抵达最底层前同样要经过 L 次 Compact,每次 Compact Ln 中 T 个相同尺寸的 SST 放到 Ln+1。设 SST 大小为 1,那么 T 个 SST Compact 的合并开销是 T,换言之将 T 单位的 Ln 的 SST 推到 Ln+1 要耗费 T 的 IO,单次 Compact 的写放大为 T / T = 1。每条记录的写入成本为 1/B 次最小单位 IO。三者相乘即得结果。
-
Point Lookup:对于每条 Key,有 L 层,每层最多有 T 个重叠区间的 SST,对于整个 SST 来说有 T *
L 个可能命中的 SST,乘上 BloomFilter 的失效率,即可得结果。
注意,这里不乘 1/B系数的原因是写入可以批量提交拉低成本,但是读取的时候必须对齐到最小读 取单元尺寸。
总结,Tier 策略降低了写放大,增加了读放大和空间放大,Level 策略增加了写放大,降低了读和空间放大。
LSMT 存储引擎调优案例与展望
LSMT存储引擎调优案例 - TerarkDB
TerarkDB aka LavaKV 是字节跳动内部基于 RocksDB 深度定制优化的自研 LSMT 存储引擎,其中完全自研的 KV 分离功能,上线后取得了巨大的收益。
KV 分离受启发于论文 WiscKey: Separating Keys from Values in SSD-conscious Storage,www.usenix.org/system/file… 较长的记录的 Value 单独存储,避免 Compact 过程中频繁挪动这些数据。做法虽然简单,但背后的原理却十分深刻。存储引擎其实存了两类数据,一类是索引,一类是用户输入的数据。对于索引来说,随着记录不断变更,需要维护索引的拓扑结构,因此要不断 Compact,但对于用户存储的数据来说,只要用户没删除,可以一直放着,放哪里不重要,能读就行,不需要经常跟着 Compact。只要 Value 足够长,更少 Compact 的收益就能覆盖 KV 分离后,额外维护映射关系的开销。
这里分享两个字节内部真实案例。
Abase 图存储场景使用 TerarkDB
-
图存储场景描述
- Key size :20B ~ 30B
- Value size:数十 KB 级别
- 写多读少
-
收益结论:延迟大幅度降低,长尾消失,扛住了比 RocksDB 高 50% 的负载。
Flink 流计算场景使用 TerarkDB
- 收益结论:
-
平均 CPU 开销在 3个作业上降低了 26%~39%
-
峰值 CPU 开销在广告作业上有明显的收益,降低了 67%
-
live_feed_head 作业上峰值 CPU 开销降低 43%
-
multi_trigger 受限于分配的CPU 资源,没有观察到峰值 CPU 收益( 平均 CPU 开销降低 39% )
-
-
平均容量开销在 3 个作业上降低了17%~31.2%
-
直播业务某集群容量不收缩,TerarkDB 的 schedule TTL GC 彻底解决了该问题
- 收益说明:
-
平均 CPU 收益主要来自于,开启 KV 分离,减少写放大
-
容量收益主要来自于 schedule TTL GC,该功能可以根据 SST 的过期时间主动发起Compaction,而不需要被动的跟随 LSM-tree 形态调整回收空间
| multi_trigger 4620 corelive_feed_head (3600core : 3000core)ad_online_joiner (786core ) | RocksDB | TerarkDB | 收益描述 | |||
|---|---|---|---|---|---|---|
| Max | Average | Max | Average | |||
| multi_trigger(4/12 15点~4/13 15点) | Application Used CPU | 4.68K | 2.51K | 4.76K | 1.54K | 平均 CPU 开销降低 39% |
| Application Used Memory | 10.4TB | 10.1TB | 9.97TB | 9.35TB | 内存开销降低 3.1% | |
| Total CheckPoint State Size | 19.3TB | 12.7TB | 16.3TB | 8.74TB | 平均容量降低 31.2% |
存储引擎最新发展趋势
新硬件
随着硬件的发展,软件设计也会随着发生改变。近年来,出现了许多新的存储技术,例如 SMRibD, Zoned SSD / OpenChannel SSD, PMem等。如何在这些新硬件上设计/改进存储引擎是一大研究热点。
e.g. MatrixKV: Reducing Write Stalls and Write Amplification in LSM-tree Based KV Stores with Matrix Container in NVM
这篇论文中的设计将 LO整个搬进了PMem,降低了写放大。
新模型
经典 LSMT模型是比较简单的,有时候不能应对所有工况,可以提出新的模型来解决问题
e.g. WiscKey: Separating Keys from Values in ssD-conscious Storage 通过额外增加一个 Value Store 来存储大 Value 的记录来降低总体写放大。
e.g.REMIX: Efficient Range Query for LSM-trees 通过额外增加一种SST的类型来加速范围查询的速度
新参数 / 新工况
已有的模型,在新的或者现有工况下,参数设置的不合理,可以通过更精确的参数设置来提升整体性能。
e.g. The Log-Structured Merge-Bush & the Wacky Continuum 在最后一层使用 Level Compaction,之上使用 Tier Compaction,通过在除了最后一层以外的 SST 加大 BloomFilter 的 bits 数来规避Tier Compaction带来的点查劣化。
总结
- 单机数据库的 ACID 特性依赖于存储引擎 LSMT存储引擎的顺序写特性更适合现代计算机体系结构
- LSMT和B+Tree可以用同一模型描述并互相转化
- Level Compaction 策略,降低了读放大和空间放大,增加了写放大
- Tier Compaction 策略,降低了写放大,增大了读放大和空间放大
- 分布式 KV 存储,如 HBase,背后的理论模型与单机存储引擎RocksDB 一样都是 LSMT
