

数据分析可以为你提供关于一般趋势的洞察力,但在许多情况下,将这些趋势与群体联系起来有更大的价值,例如,使用移动设备的访客与桌面浏览器的访客,或者那些购买金额大于100美元的访客与小于100美元的访客。在一个确定的时间跨度内,按照具有共同特征的群体或 "队列 "来检查数据的过程就是这篇文章的全部内容。
在本教程中,我们将向你展示如何将这种类型的分析应用于一个数据集,该数据集包含了一个特定零售店的销售数据。然后,我们将向你展示如何通过预测为实现某些目标而需要的新客户数量来提供进一步的价值。这个过程将是
- 安装运行环境
- 导入并清理数据集
- 分配群组
- 计算保留率
- 按数量和收入对数据进行分类
- 预测队列数据
最后,我们将做一些可视化处理,以便更容易看到我们的结论。让我们开始吧。
在你开始之前:安装群组分析的Python环境
为了跟上本文的代码,你可以下载并安装我们预先建立的Cohort Analysis环境,其中包含Python 3.9版本和本文中使用的软件包,以及已经解决的依赖关系
为了下载这个随时可用的Python环境,你需要创建一个 ActiveState Platform 账户。只需使用你的GitHub凭证或你的电子邮件地址来注册。注册很简单,它为你解锁了ActiveState Platform的许多好处!
或者你也可以使用我们的 State工具 来安装这个运行时环境。
对于Windows用户,在CMD提示下运行以下程序,可以自动下载并安装我们的CLI、状态工具以及群组分析运行 时到一个虚拟环境中。
powershell -Command "& $([scriptblock]::Create((New-Object Net.WebClient).DownloadString('https://platform.activestate.com/dl/cli/install.ps1'))) -activate-default Pizza-Team/Cohort-Analysis"
对于Linux用户,运行以下程序,自动下载并安装我们的CLI、状态工具以及 Cohort Analysis运行时 到一个虚拟环境中。
sh <(curl -q https://platform.activestate.com/dl/cli/install.sh) --activate-default Pizza-Team/Cohort-Analysis
2-数据准备
让我们看一下我们的样本数据集。
df = pd.read_csv('data/scanner_data.csv')
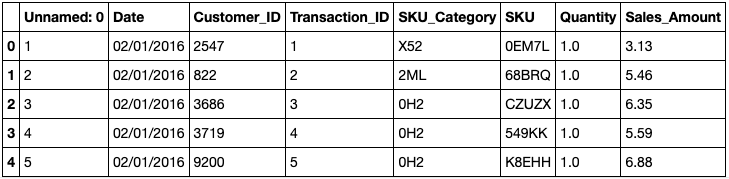
正如你所看到的,它只包含几列。
- 交易编号(标有 "未命名的0 "的那一列)
- 日期
- 客户ID
- 交易ID
- 产品类别
- SKU标识符
- 数量
- 销售金额(即单价乘以数量)。
但是,在我们使用这些数据之前,我们需要对其进行清理,并对日期进行格式化。我们还想把同一客户在同一日期进行的交易放在同一行中,因为我们的演示将基于 交易日期、 数量和 销售金额,而不是 产品类型。下面是方法:
df.drop(['Unnamed: 0'], axis = 1)
输出:
68979
df = pd.DataFrame(df.groupby(["Date","Customer_ID"]).agg({'Transaction_ID':max
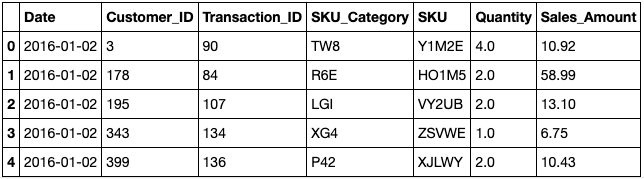
应用这些修改后,数据集的大小被削减了一半。
下一步是 使用熊猫的 groupby 和 agg 函数合并相似的行(例如, 在同一 日期的相同的 customer_id) ,这将:
- 用所有合并的行的总和 来替换 结果行 的数量 和 销售金额
- 对 交易ID、 SKU _**category和 SKU 列使用最大值 。
3-给数据分配队列
为了进行队列分析,我们需要:
- 将数据分成可以根据时间进行分析的组别
- 为每个交易指定一个队列索引
- 创建两个新的列
下面的代码显示了如何对 日期 列 应用一个简单的lambda函数 ,以便:
- 创建 tx_month 列
- 变换 tx_month 以得到 每个客户 的tx_month 的最小值
- 将 每个客户的tx_month分配 给 acq_month 列。
df['tx_month'] = df['Date'].apply(lambda x: dt.date(x.year, x.month,1))
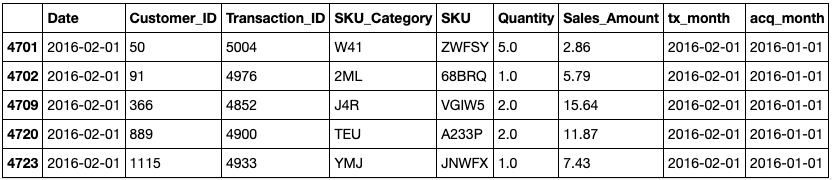
正如你所看到的,50号客户是在2016年1月1日获得的,但是5004号交易是在2016年2月1日才进行。该行的队列索引是 tx_month 和 acq_month之间的时间差 ,日期之间的差异由一个函数计算,该函数在结果中加1,以便从1而不是0开始队列(即与收购同月进行的交易)。
def diff_month(x):
4-计算保留率
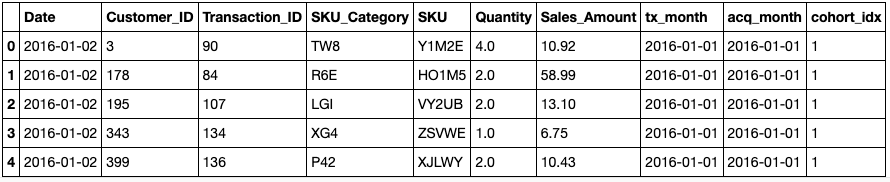
我们现在可以进行一些有趣的计算,比如通过设置 每行的cohort_idx,找出每个队列每月获得多少个独特的客户 。下面的函数接收一个数据框架、一个要分组的变量和一个要用作聚合数据的函数,并返回两个矩阵:
- 第一个显示每个组群每月的绝对值,函数应用在变量上并作为参数传递。
- 另一个则以百分比的形式表示结果。
def get_cohort_matrix(data, var='Customer_ID', fun=pd.Series.nunique):
然后运行:
cc, retention = get_cohort_matrix(df)
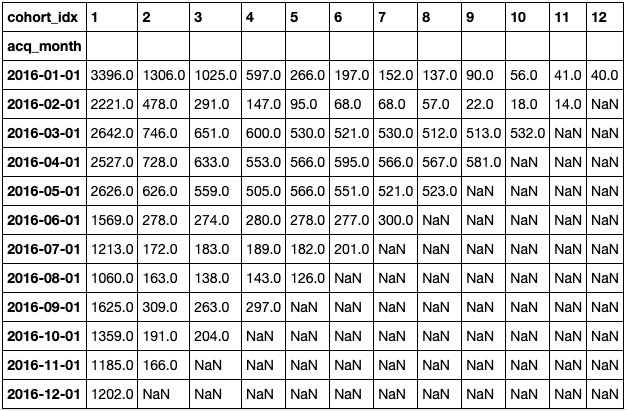
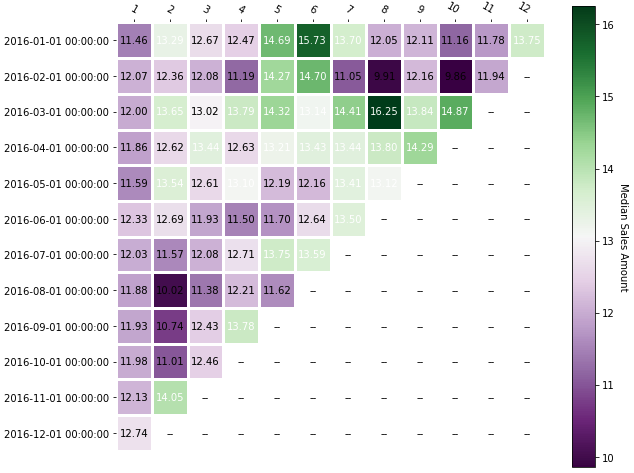
在matplotlib提供的注解热图函数的帮助下 ,我们可以看到每个队列的独特客户数量随时间变化的图形表示。
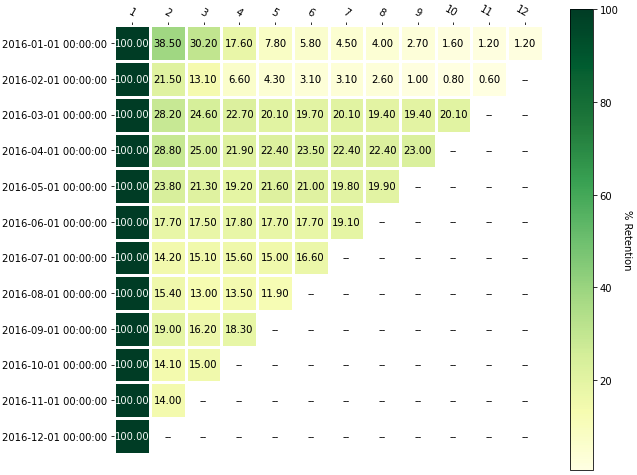
有了这些信息,你就可以进行基于时间的队列分析,也就是通常所说的保留分析。在上面的图片中,你可以看到:
- 在2016年1月获得的客户中,有38.5%在次月返回。
- 2016年2月获得的客户中有21.5%的人返回了
自2016-05-01的队列中获得的客户更不可能返回,这一点应该引起你的注意。
5-按数量和收入划分的数据
你也可以使用之前的函数(get_cohort_matrix)来创建基于平均项目数量的队列。在下面的例子中,变量是 数量 ,聚合函数是平均值。
cc\_q, ret\_q = get\_cohort\_matrix( df, var='Quantity', fun=pd.Series.mean )
cc\_q
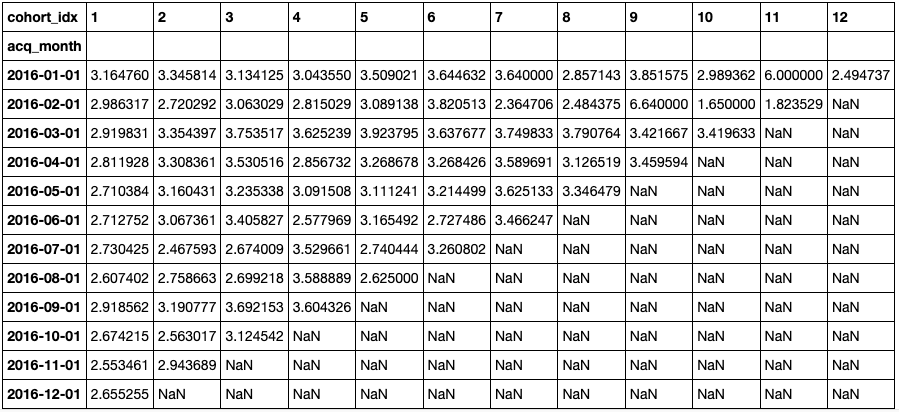
绘制绝对数很容易,它显示了有两个时期的异常行为。通过进一步分析,你应该能够确定一些可能的解释,并假设复制好结果的方法。

你还可以使用 sales_amount 变量来确定某些群组的客户是否比其他客户花更多的钱。在下面的例子中, sales_amount 是变量,聚合函数是中位数。
cc_sa, ret_sa = get_cohort_matrix( df, var='Sales_Amount', fun=pd.Series.median )
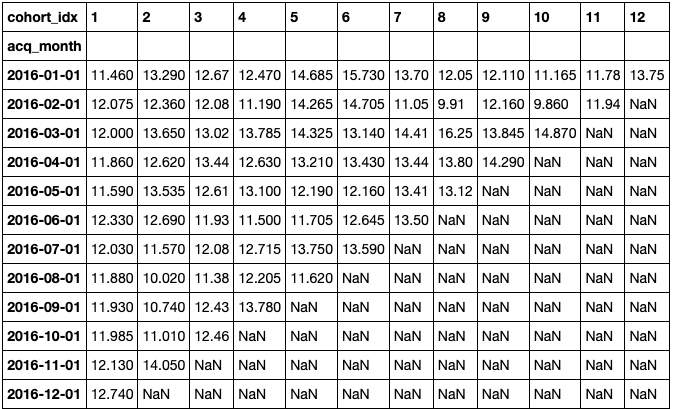
下面的热图显示,2016年3月获得的队列在一段时间内的收入方面是最好的。此外,你可以看到最近的收购带来的资金较少,这也是需要注意的地方。
6-如何预测队列数据
企业也可以通过使用队列分析进行预测来获得价值。The Theseus 库包含许多有趣的方法,可以使用从历史数据和每日收购数字计算出的每日保留率来分析队列。例如,你可以使用前五天的用户数来为模型提供数据。
ret_avg = [80, 70, 50, 45, 30, 25, 21,]
输出:
[135, 68, 163, 190]
然后运行:
th = thg.theseus()
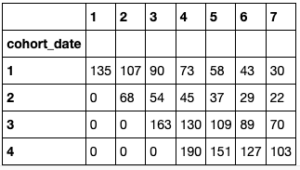
前面的图片显示了如何通过将第一周的留存率和每天的用户数样本输入模型来建立一个公司概况。这个简介可以用来获得日活跃用户(DAU)的堆积图,只需要一行代码,而这是基于模型所拟合的曲线。
th.plot_forward_DAU_stacked( forward_DAU = profile_DAU,
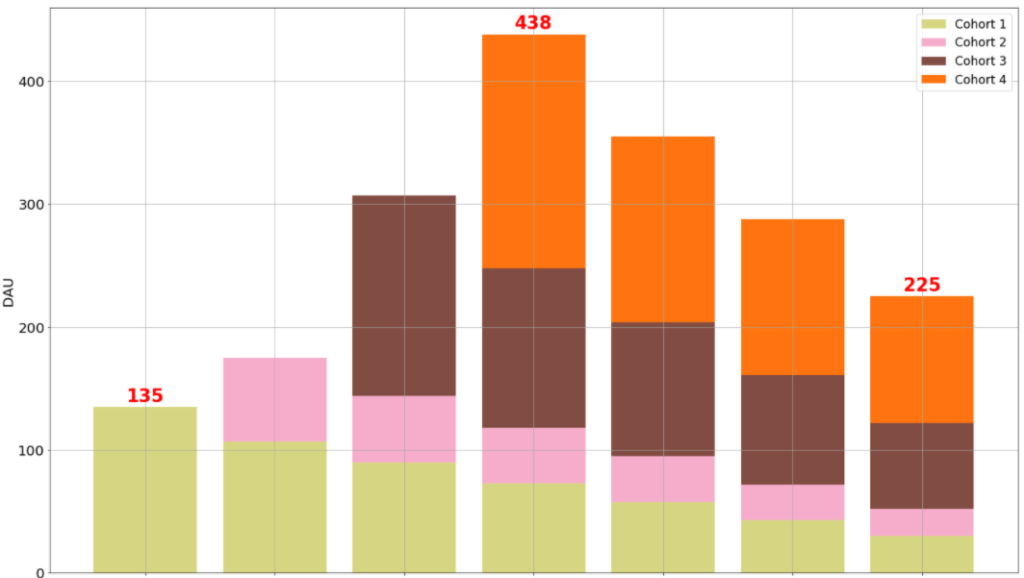
但最有趣的是,你可以设定一个目标,在特定时间段内拥有一定数量的DAU,模型将返回你每天需要的收购数量,以实现这一目标:
expected_DAU = th.project_cohorted_DAU( profile = th_profile, periods = 15, cohorts = new_users_daily,
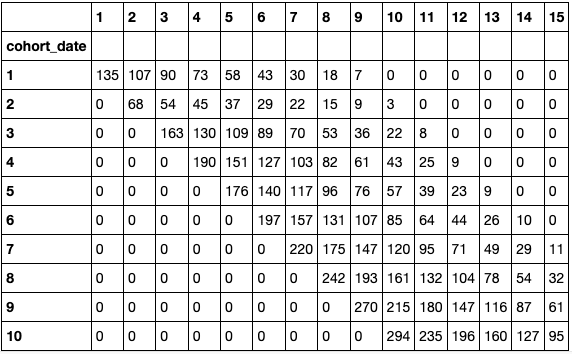
正如你所看到的,该公司必须不断增加收购,以便在给定的保留率和最初的四个值[135, 68, 163, 190]的情况下,在十天内获得1000个DAU。当然,这种分析并不是建立获取和保留策略的唯一方法,但能够轻松地玩转不同的场景,肯定会有帮助。
结论:队列分析在有限的数据下发挥作用
队列分析是最常见的技术之一,用于从 "小 "数据(相对于大数据)中获得价值,而不需要复杂的模型。当然,这并不是唯一的选择,公司也可以进行类似的分析,以建立一个有数据信息的文化,而不必在其他资源上投入大量资金。由于队列分析可以以图形方式显示结果,不过它可以帮助用户轻松地可视化和理解趋势。
