


Scikit Learn SVM简介
下面的文章提供了一个Scikit Learn SVM的概要。SVM不过是机器学习的一套监督学习算法,基本上用于回归、分类和检测。SVM支持学习方法,用于高维空间,当我们有几个维度比样本的大小更重要时,我们可以使用它。当我们需要比其他分类器或逻辑回归更高的预测精度时,我们可以在scikit中使用SVM。
支持向量机(SVM)是稳健但适应性强的管理型人工智能技术,用于订单、复发和异常识别。SVM在高分层空间中非常有效,而且大体上被用于特征描述问题。SVMs是众所周知的,并具有记忆影响力,因为它们在选择能力中使用了一个准备重点的子集。
SVM的基本目标是将数据集划分为几个类别,以找到最极端的外围超平面(MMH),这在伴随的两个阶段应该是可能的:
- 支持向量机最初会迭代地创建超平面,最有效地隔离类。
- 之后,它将挑选出能准确分离类型的超平面。
支持向量机的几个重要想法如下:
- 支持向量: 它们可能是最接近超平面的数据点。支持向量有助于选择带涂层的隔离。
- 超平面: 选择平面或空间,将一组具有不同类别的项目分割开来。
- 边缘: 多个类别的感兴趣的储藏室数据上的两条线之间的洞被称为边缘。
如何使用Scikit Learn SVM?
让我们看看我们如何在Scikit中使用SVM,如下。 为了实施,我们需要遵循以下不同的步骤。 首先,我们需要导入所有需要的库,如下所示。
代码
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
在下一步,我们需要导入一个所需的数据集;如果我们已经下载了它,那么我们需要根据我们的要求下载它。
让我们假设我们已经下载了数据集,所以我们需要使用下面的代码。
代码
sampledata= pd.read_csv(“required file path”)
现在我们需要编写数据分析的代码。在各种python库的帮助下,有不同的方法来分析数据集。为了简化,在这里,我们可以只检查前几条记录的数据尺寸,并进行分析。
代码
sampledata.shape
如果我们想看到实际的数据,那么我们需要使用下面的命令,如下所示。
代码
sampledata.head()
现在一切都好了,我们需要处理数据,所以我们需要将数据分为不同的属性和标签,以创建训练有素的数据集。
所以为了区分数据,我们需要使用下面的代码,如下所示。
代码
X = sampledata.drop(‘Class’, axis =1)
Y = sampledata[‘Class’]
当信息被划分为特征和名称时,最后一个预处理步骤是将数据分成准备集和测试集。幸运的是,Scikit-Learn库的model_selection库包含training_test_split技术,允许我们将信息完美地隔离成准备集和测试集。我们需要训练算法,使其在训练数据上使用SVM。Scikit-Learn包含SVM库,其中包括用于各种SVM计算的工作类。由于我们将进行分组任务,我们将利用帮助向量分类器类,由Scikit-Learn的SVM库中的SVM组成。
现在一切都好了,我们需要进行预测,所以应用SVC的预测方法,如下图所示,代码如下。
代码
prediction = svclassifier.predict(test_data)
现在让我们看看如何评估算法,所以我们可以使用混淆矩阵,和精度这些最常用的评估技术。
所以我们可以使用下面的代码,如下。
代码
from sklearn.metrics import classification_report, confusion_matrix
print()confusion matrix(tes_date, prediction)
最后,我们可以看到结果。
Scikit Learn分类的SVM
SVM支持以下不同类型的分类:
- LinearSVC: 基本上,它是线性支持向量分类。它提供了两个选项,如损失函数和惩罚措施。通常,LinearSVC用于处理大量的数据。
- NuSVC: 这只不过是Nu支持向量分类。它被用来进行多类分类;NuSVC的工作性质与SVC相同。
- SVC: 它是一种基于C的支持向量分类,支持多类支持和使用的一对一机制。
SVM的分类,可以在我们的数据库上进行二类和多类的分类,如下面的截图所示。
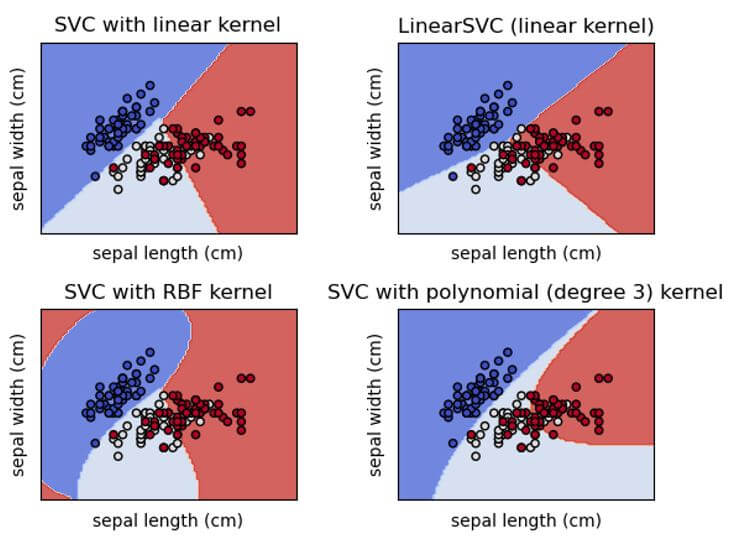
SVC和NuSVC是比较的策略;然而,它们承认各种边界的安排,并有不同的数字计划(见分段数学定义)。然后,LinearSVC是支持向量分类的另一种(更快)执行方式,适用于直件的实例。
以及它需要以下不同的参数:
- C: 这是用来显示误差的。
- kernel(内核): 这是用来指定内核的类型。
- 程度: 它显示聚核函数的程度。
- gamma: 伽玛只不过是内核的系数。
- coef0: 这个独立参数只与poly和sigmoid核类型有关。
SVM还有许多其他参数,我们可以根据分类算法的要求来使用。
Scikit Learn SVM的例子
下面是SVM的例子,不同的分类方法如下。
代码
import numpy as num
x_var = num.array([[-1, -1], [-2, -1], [1, 1], [2, 1]])
y_var = num.array([1, 1, 2, 2])
from sklearn.svm import SVC
SVCClf_data = SVC(kernel = 'linear',gamma = 'scale', shrinking = False,)
SVCClf_data.fit(x_var, y_var)
解释
- 在上面的例子中,我们试图实现SVC分类,其结果显示在下面的截图中。
输出

结论
在这篇文章中,我们试图探索Scikit Learn SVM。在这篇文章中,我们看到了Scikit Learn SVM的基本思想以及这些Scikit Learn SVM的用途和特点。报告的另一个要点是我们如何看到Scikit Learn SVM的基本实现。
