

今年早些时候,我们向世界介绍了Grafana Mimir,一个用于Prometheus的高度可扩展的开源时间序列数据库。
Mimir的保证之一是与PromQL 100%兼容,它通过重用Prometheus PromQL引擎实现了这一点。然而,在Prometheus PromQL引擎中,查询的执行只在一个单线程中进行,所以无论你向它投入多少个CPU核心,它都只会使用一个核心来运行一个查询。这使得引擎的实施和维护随着时间的推移更加容易,但不幸的是,对于一些高cardinality或CPU密集型的查询来说,它的速度很慢,通常查询评估时间的增加与需要处理的样本数量直接相关。
Mimir有一个基于微服务的架构,Mimir的所有组件都是可以横向扩展的。其中一个组件是查询器,它是评估PromQL查询的部分,通过存储网关从摄取器中获取最新的时间序列数据和从长期存储中获取历史数据。
随着我们规模的扩大和摄取越来越多的指标,确保我们能够有效地查询这些指标也变得非常重要。也就是说,不仅仅是能够进行更多的查询(这是增加查询器副本数量的传统做法),而且还能够在不影响性能的情况下处理更大和更高标准的查询。
为了克服在单线程中运行的局限性,同时也为了继续使用相同的PromQL引擎以获得兼容性,我们在Grafana Mimir中引入了两种分片技术。时间分割和查询分片允许我们在多个CPU核心和机器上并行执行一个查询,对于高卡度和CPU密集型查询来说,执行时间通常会减少10倍。
时间分割是相当直接的,正如其名称所示。该方法需要按时间分割一个范围查询,并分别执行每个部分的查询,从而平衡多个查询器的负载。然后,这些结果可以被连接到一起,成为一个连续的时间。
一个查询是按-query-frontend.split-queries-by-interval ,默认是24小时分割的。因此,一个简单的查询,如跨越三天的sum(rate(metric[5m])) ,将在三个不同的查询器上运行(每天一个),然后将结果串联起来。
Grafana Mimir中的查询分片
查询分片的工作方式是将查询分布在多个查询器上(每个分片一个),并针对系列的一个子集执行每个部分的查询。然后可以根据查询中的聚合类型,用方法将结果重新连接起来。碎片的分割和连接是由查询前端执行的,然后将每个部分查询分发到querier 。
一个查询的每个可分片的部分可以被分割成-query-frontend.query-sharding-total-shards 个部分查询。例如,如果这被设置为3 ,那么sum(rate(metric[1m])) 可以被执行为:
sum(
concat(
sum(rate(metric{__query_shard__="1_of_3"}[1m]))
sum(rate(metric{__query_shard__="2_of_3"}[1m]))
sum(rate(metric{__query_shard__="3_of_3"}[1m]))
)
)
然后一个单独的查询器可能会收到一个部分查询,如sum(rate(metric{__query_shard__="2_of_3"}[1m])) 。concat()注解用于显示部分查询结果何时被查询前台连接/合并。
当查询器为metric{__query_shard__="2_of_3"} ,它知道只寻找三个分片中的第二个分片的度量。检查一个系列是否属于给定分片的算法是:series.hash() mod 3 == (2-1) 。因此,查询器会返回由分片决定的部分系列。
一旦所有的部分查询完成,结果就会被重新连接在一起。
查询分片也与分割和合并压实器所分片的存储块一起工作。先进的压实器将系列分块,以克服Prometheus的TSDB格式的限制。
查询器知道存储中的分块,并能够只查询包含该分块指标的块。这种技术使我们能够进一步加快查询的执行速度,因为它更好地在存储-网关之间分配负载。你可以在我们的博文中阅读更多关于Mimir压缩器的工作原理,并了解为查询分片提供的好处。
对分片存储的例子进行扩展。当运行对分片2_of_3的查询时,如果存储中有6个分片,查询器将只查询块2和5,因为它保证它们是唯一包含查询分片2_of_3的指标的。
查询分片和分片存储示意图:

可分片查询的类型
并非所有的查询都是固有的可分片存储。然而,即使完整的查询不能被分片,查询的内部部分仍然可以被分片。特别是,关联聚合(如sum、min、max、count、avg)是可舍弃的,而一些查询函数(如absent、absent_over_time、histogram_quantile)则不是。
上面的sum(rate(metric[5m])) 例子是一个完全可存储的查询。下面,我们将看一下两个碎片计数为3的例子。所有包含标签选择器__query_shard__的部分查询都是并行执行的。
例子。内部部分是可分片的
histogram_quantile(0.99, sum by(le) (rate(metric[1m])))
被执行为:
histogram_quantile(0.99, sum by(le) (
concat(
sum by(le) (rate(metric{__query_shard__="1_of_3"}[1m]))
sum by(le) (rate(metric{__query_shard__="2_of_3"}[1m]))
sum by(le) (rate(metric{__query_shard__="3_of_3"}[1m]))
)
))
例子 :查询有两个可分片的部分
sum(rate(failed[1m])) / sum(rate(total[1m]))
被执行为:
sum(
concat(
sum (rate(failed{__query_shard__="1_of_3"}[1m]))
sum (rate(failed{__query_shard__="2_of_3"}[1m]))
sum (rate(failed{__query_shard__="3_of_3"}[1m]))
)
)
/
sum(
concat(
sum (rate(total{__query_shard__="1_of_3"}[1m]))
sum (rate(total{__query_shard__="2_of_3"}[1m]))
sum (rate(total{__query_shard__="3_of_3"}[1m]))
)
)
Grafana Mimir中时间分割和查询分片的例子
现在让我们看一下这两种技术一起应用的例子,sum(rate(metric[5m])) 。
如果你在过去三天内运行这个,Mimir将查询分成3个一天的查询,每个查询都是在不同的一天。每个每日查询都使用查询分片来进一步加速。我们通过哈希值对指标进行分片,使用分裂和合并压缩器使用的相同哈希值函数,并且只在各自的分片上运行查询。
所有生成的部分查询(本例中为9个)都可以在查询器池中并行执行。
Grafana Mimir中并行执行的查询图:

你可能会注意到,即使在这个例子中-query-frontend.query-sharding-total-shards 被设置为3,总共也有9个部分查询被生成和执行。这是因为它与时间分割相乘,但也可能与查询的类型和使用的方法相乘。因此,-query-frontend.query-sharding-max-sharded-queries ,以限制生成的部分查询的总数(其中查询首先按时间分割,其次按分片分割)。
Grafana Mimir中的查询性能优势
仅仅通过查询分片,我们就能观察到高cardinality和CPU密集型查询的执行时间减少了10倍。
Grafana仪表盘显示,在Grafana Mimir中使用查询分片,执行时间减少了10倍:
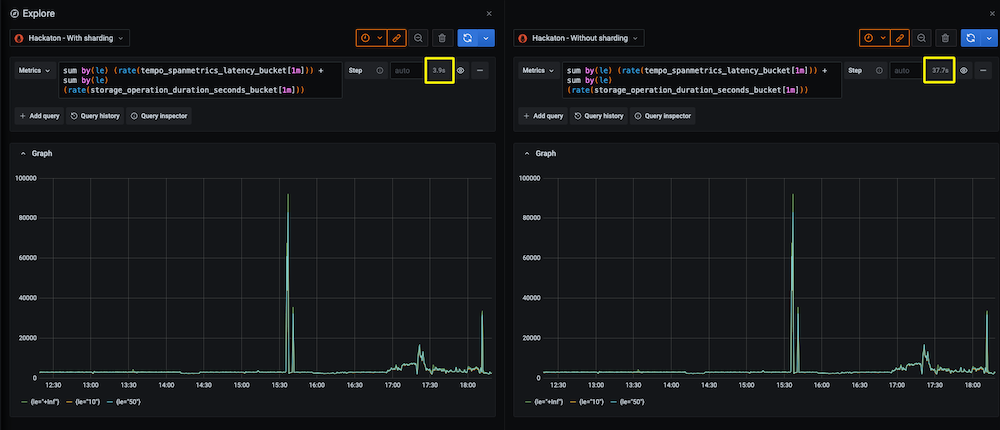
例如,上面的截图显示了相同的高cardinality查询,在同一Mimir集群上运行,启用和未启用查询分片。在这种情况下,执行时间从大约38秒减少到4秒。
在Grafana实验室,我们使用Grafana Mimir来支持Grafana Cloud Metrics。虽然不是所有的查询都可以分片,但在Grafana Cloud上运行的所有客户查询中,大约有60%是分片的,这代表了巨大的性能优势。
Grafana仪表盘显示Grafana云中被分片的查询比例:

上面的Grafana仪表板显示了Grafana云中被分片的查询的百分比。因此,我们可以看到平均有多少查询是可分片的,因此我们获得性能优势的频率。
