

Grafana Tempo 1.3已经发布了!我们很自豪地增加了搜索后端数据存储的功能。这个功能也将很快出现在Grafana Cloud Traces中。
如果你想深入了解具体细节,你可以随时查看1.3版的更新日志。如果这些内容太多,这篇文章将涵盖大的项目。
你也可以注册参加我们即将举行的网络研讨会 "Grafana中的分布式跟踪。从Tempo OSS到企业"的网络研讨会,我们将在1月27日进行现场演示并与Grafana实验室的专家进行问答。
Grafana Tempo 1.3的新功能
后台数据存储搜索
后台数据存储搜索现在在Tempo 1.3中可用!请参考Grafana的设置文档。Grafana的UI和搜索最近痕迹的UI是一样的:
在我们内部的Tempo集群中,我们目前的摄取速度是~180MB/s。不幸的是,我们的搜索可能感觉更像是批处理工作。搜索几个参数有时需要10-20秒,这并不理想。我们致力于将其减少一个数量级,以提供你在Loki等项目中所习惯的快速搜索。我们的制约因素是我们的后端格式。(期待在即将到来的Tempo版本中得到改善!)。
在内部,我们正在使用无服务器技术来催生每个查询的成千上万个作业,这些作业会破解你的区块,并仔细研究下面的跟踪数据。查看如何在你的安装中用Tempo建立一个无服务器环境。在内部,我们正在冲击数以千计的无服务器实例。
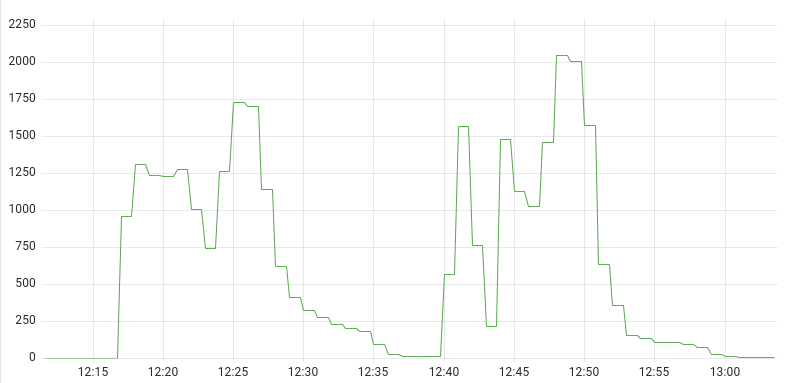
上图:搜索过程中无服务器实例的数量。
请注意,无服务器并不是后端数据存储搜索的必要条件,如果你的负载较小,查询本身可能就能有效地完成工作。
自动遗忘压缩器
Tempo的一些用户一直看到这样的问题:压缩器在其一致的哈希环中保持不健康的状态,甚至在优雅地退出之后。我们在Grafana没有遇到过这个问题,所以很难诊断和解决这个问题。
在Tempo 1.3中,我们更新了我们的环形代码,在两次心跳超时失败后自动遗忘压缩器。这个默认值是两分钟,但它是可以配置的:
compactor:
ring:
heartbeat_timeout: 1m0s
这个变化应该会减少那些看到这个问题的人在运行Tempo时的操作负担。
更好地保护大型跟踪
接近100MB以上的跟踪对Tempo来说有很多挑战。摄取、压缩和查询都会对不同的组件造成压力,因为需要大量的内存来组合这种规模的痕迹。
Tempo试图用下面的配置来限制痕迹的大小,默认为50MB:
overrides:
max_bytes_per_trace: 50000
在Tempo 1.2和以前的版本中,一旦追踪的内存用完了,我们就不再防止摄取一个大的追踪。这通常发生在几秒钟之后,没有收到更多的跟踪数据的时候。
在Tempo 1.3中,我们已经更新了代码,继续拒绝大的跟踪,直到头块被切断,这可能是15-30分钟。因为即使是这样也会被一些团队在数小时或数天内推送巨大的跟踪数据所规避,所以我们也有其他的想法(比如围绕最大跟踪尺寸的对话和改进压实器)。
突破性变化
Tempo 1.3有一些小的突破性变化。对于大多数Tempo操作者和用户来说,这些突破性变化不会有任何影响:
- 对 "Push "GRPC端点的支持已从采集器中移除。这个方法从Tempo v1.0开始就被弃用了。如果你正在运行1.x版本,这对你没有影响。如果你是从0.x版本升级的,我们建议你先升级到Tempo v1.2,然后再升级到Tempo v1.3。
- 我们的 OTel 采集器依赖关系的升级将默认的 OTel GRPC 端口从 55680 改为 4317。如果你在配置中明确指定了你的端口,这个变化不会影响你。
- 在增加完整的后端搜索过程中,两个与搜索相关的配置设置被重新定位了:
query_frontend:
search_default_result_limit:
search_max_result_limit:
被重新定位到了:
query_frontend:
search:
default_result_limit:
max_result_limit:
下一步是什么?
我们需要改进我们的后端跟踪格式。我重复一遍:我们真的需要改进我们的后端跟踪格式。我们目前是将跟踪信息以marshalled to protobuf的形式存储在对象存储中,并以巨大的区块形式排列在一起。这对于通过ID查询痕迹来说效果很好,但对于有效的搜索来说,这不是很合适的形状。
对于新的后端格式,有很多选择,团队正在努力评估和测试它们。我们需要朝着既能从数十亿条数据中检索出一条数据,又能支持基于标签的搜索,并最终支持更具表现力的TraceQL的解决方案发展。你可以参加我们的社区电话会议,以获得关于搜索和其他Tempo进展的最新新闻!
