

NoSQL中SQL的JIT编译
踏上SQL查询的JIT编译之旅。
在我开发各种工具链组件作为教育项目的一年时间里,在导师(Nikita Pettik,Timur Safin, andIgor Munkin)的支持下,我接手了这个项目。在短短的一个夏天里,在Tarantool中建立一个几乎从零开始的SQL查询的JIT编译平台时,我遇到了一些陷阱,并获得了,在我看来,有趣的知识和经验,我想分享一下。这篇文章首先对那些有兴趣进一步维护这个项目的人,以及那些正在考虑在自己的SQL中实施JIT编译的人感兴趣。
我所要做的工作
为了支持SQL语言,Tarantool使用了一个继承自SQLite的虚拟机(VM)。它也被称为虚拟数据库引擎(VDBE)。这个组件的原理图:

实现虚拟机的最流行的方法之一是用字节码的指令流来操作;VDBE就是基于这个原理。在这篇文章中,我们将研究字节码作为虚拟机的中间表示方法及其解释。接下来,在Tarantool中谈到字节码和SQL虚拟机的实现,我将提到VDBE。
字节码的解释是由一个操作码数组(由SQL查询产生的字节码程序)的for循环和操作码类型的切换来表示。
Java
for(pOp = &aOp[p->pc]; 1; pOp++) {
switch (pOp->opcode) {
...
}
}
我们的任务
在应用服务器方面,Tarantool已经有一个虚拟机,LuaJIT。另一个手写的虚拟机(不使用框架来构建执行环境)来支持SQL,从架构的角度看并不是很优雅,更不用说它带来的性能问题了。
该项目建议探索以下可能替代VDBE的方法之一:
预期的结果:
- 测试将VDBE迁移到选定的JIT平台的想法
- 检验在SQL背景下应用JIT编译的不同情况
- 通过不同的SQL基准测量JIT编译的性能
由于在给定的夏季三个月的时间内解决这个问题似乎是不可能的,而Tarantool已经通过一个基于LLVM ORC的三年前的补丁对这个任务有了第一个方法,我决定使用这个框架并继续发展Nikita Pettik的想法。此外,还有Postgres的成功例子,它已经基于这个框架实现了这样一个平台。
而现在也有另一个DBMS,ClickHouse,它也实现了一个基于LLVM ORC的SQL的JIT平台。
SQL的JIT编译
JIT编译绝不是万能的:这种方法有其缺点,并不总是能提供优于字节码解释的结果,这就是为什么JIT编译的应用范围相当有限。
它的主要优点是:
- 更少的跳转指令和本地代码的本地化,这使分支预测器得到了最好的利用
- 分支的数量较少,由于专业化,机器代码较少
- 对字节码热点有更高的性能,这些热点是CPU处理的瓶颈
- 更好地利用CPU缓存
- 为目标处理器生成指令
- 对生成的IR(中间表示法)有优化的空间
在SQL的背景下,我们可以区分使用JIT编译的主要场景:包含大量逻辑和表达式的重型分析性DQL(数据查询语言)查询。
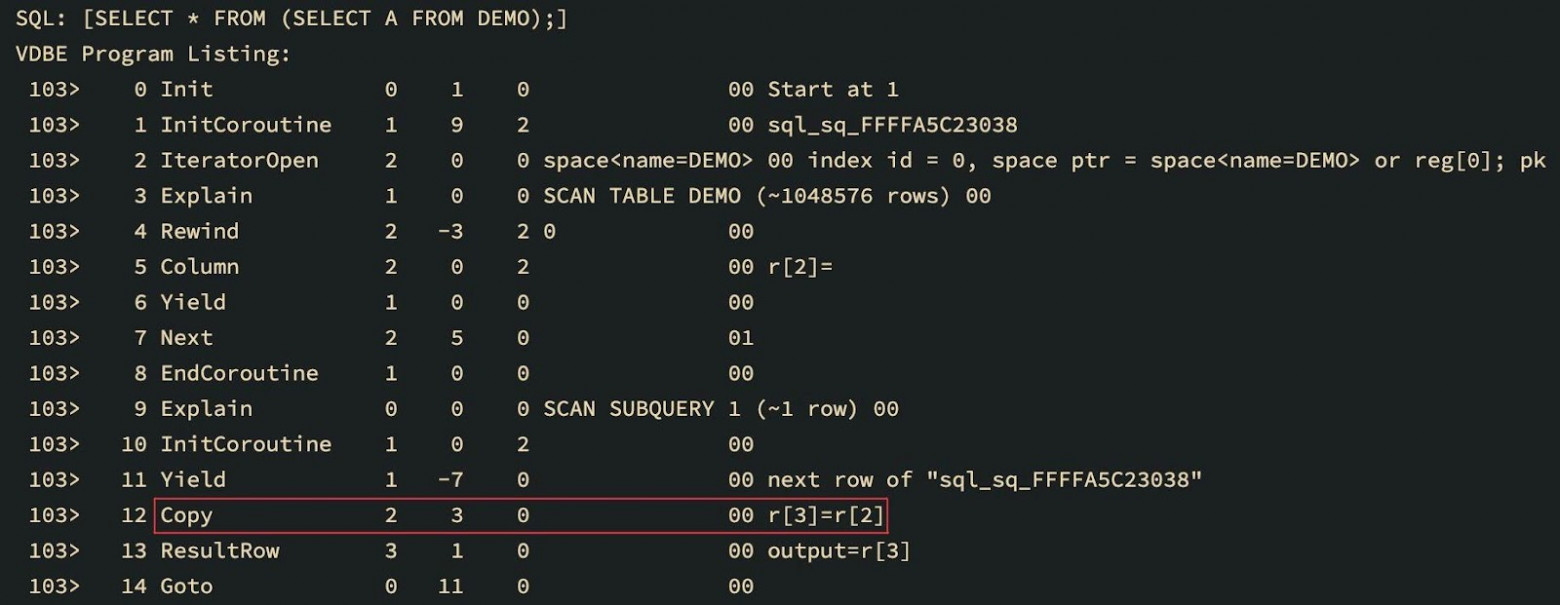
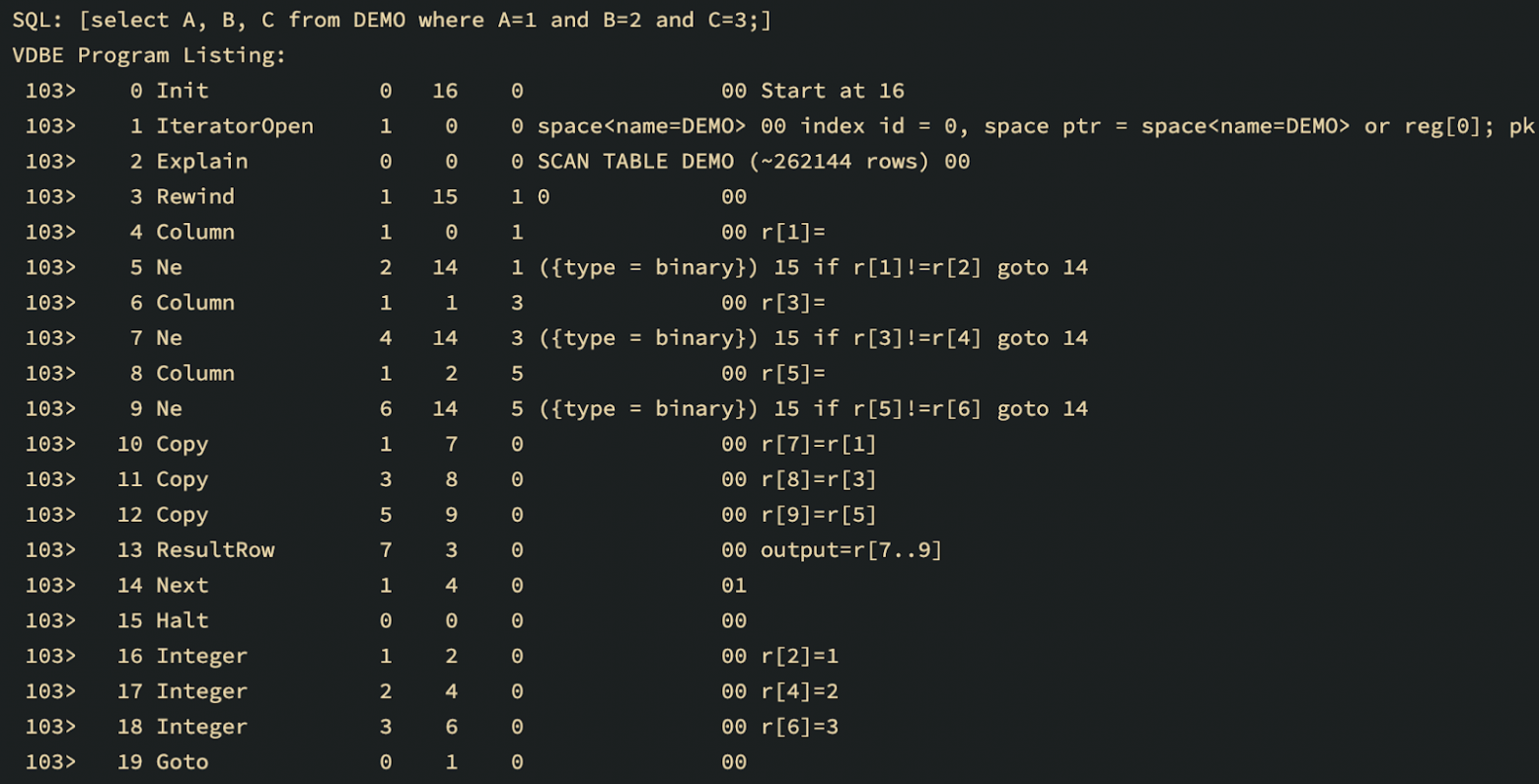 VDBE字节码列表的例子:一条Next指令形成一个循环,从指令号4(Column)开始。
VDBE字节码列表的例子:一条Next指令形成一个循环,从指令号4(Column)开始。
这样的查询只是在一个循环中反复执行的字节码序列。这样的序列可以合并成一个操作码,这将构成对本地代码函数的调用,使得它成为应用JIT编译的理想案例。
我们可以强调一些计算场景,在这些场景中,这将是有用的。
- 解码图元(Tarantool术语为行)
- 各种算术和逻辑表达式
- 聚合函数
在这里,聚合函数是一个特别有趣的情况,因为它们是通过单独的循环计算的--同样,这是一个非常适合JIT编译的条件。
我在GSoC的最终报告中强调了项目的一些额外角度和挑战。
以下是我认为从这个项目的工作中得出的最重要的结论的总结。
LLVM ORC
使用第三方框架进行JIT编译,尽管有自己的IR,可以从生成、优化和存储本地代码的任务中抽象出来。这有助于专注于生成LLVM IR和将JIT编译器嵌入到现有的SQL基础设施中。
内联,还是不内联,这是个问题
在SQL基础设施中嵌入JIT编译提出了一个问题:如何生成LLVM IR,在功能上等同于解释C语言的操作码:
在Postgres中,第二种方法只用于内置函数和操作符。
在我看来,第一种方法等同于编写汇编代码:相当耗时且容易出错。此外,做一些机械性的工作而不是一个创新的暑期项目,那简直是枯燥无味。我选择了以下策略:将现有的SQL操作码的代码块包裹在JIT编译的代码中调用的回调中--这也可以摆脱第一种方法中相当不简单的代码重复。
这里出现了一个合理的问题:代码的专业化和JIT编译的其他优势如何,我们使用这种方法似乎被剥夺了?这就是LLVM的内联功能本应发挥的作用:事实证明,我所使用的C语言API,即LLVM的C++ API的一个小子集,根本就没有这样的功能,而且它们只是在LLVM的第13版中被引入。

此外,即使是应用C++ API,你也需要建立一个完整的基础设施来:
- 存储、索引和加载由clang生成的比特码
- 在比特码模块(LLVM中的翻译单位)中搜索,找到必要的回调,并在模块间传递它们的IR
- 明确地内联回调
如何实现这种基础设施的一个好例子是Postgres。
对生成的LLVM IR进行修补
在Tarantool的SQL的JIT编译中,有一个重要的细节:一些VBDE操作码在字节码生成时被修补。例如,这对优化很有用--直接读表可以被从索引中读出的数据取代。
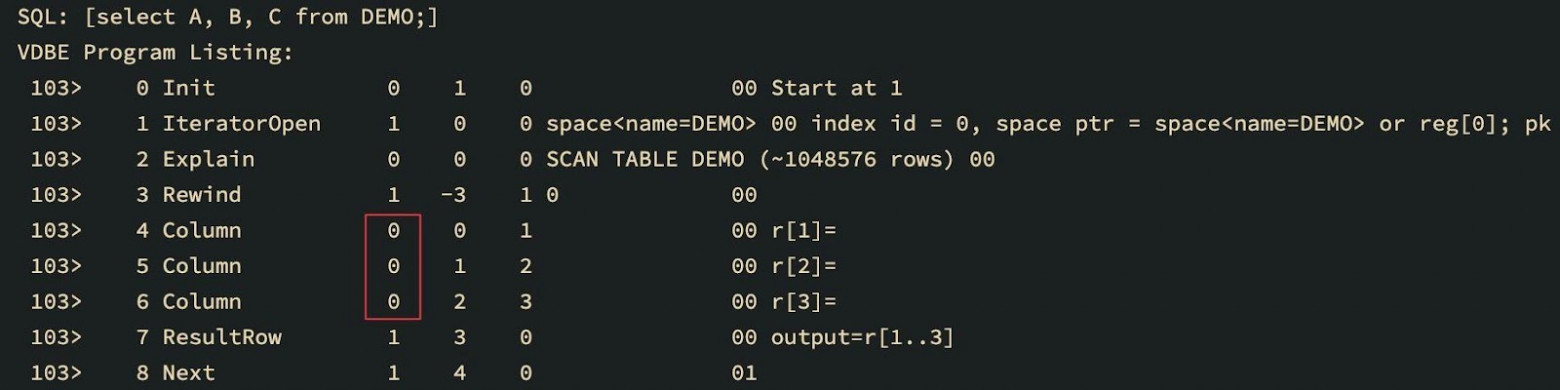 补丁之前和之后的VDBE字节码列表
补丁之前和之后的VDBE字节码列表
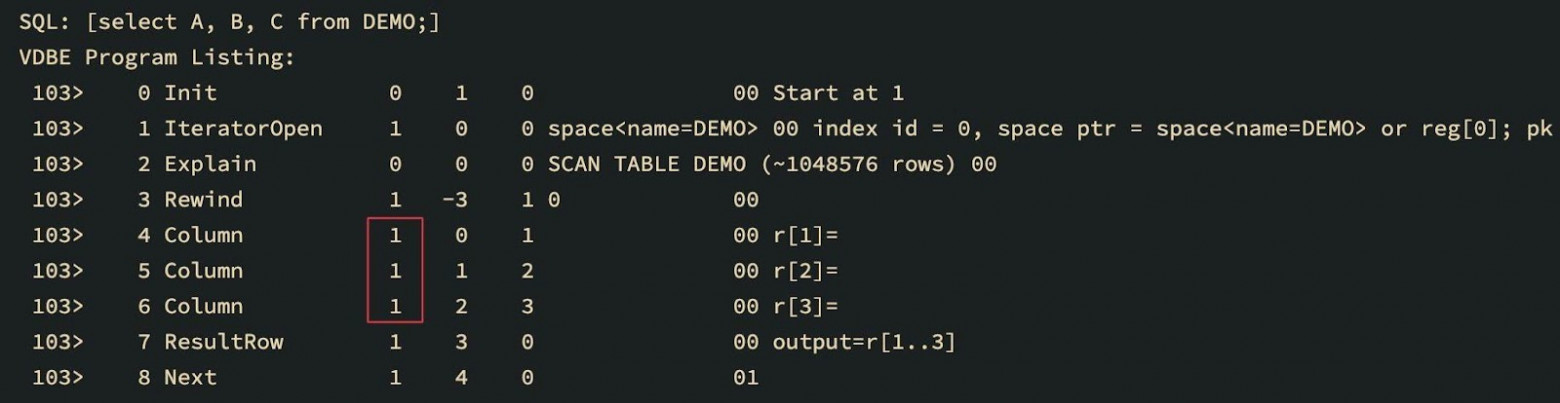 补丁后的VDBE字节码列表
补丁后的VDBE字节码列表
你可以看到对应于游标号的第一个参数在所有的列操作码中都有变化。
另一个修补字节码指令的原因可能是用于子查询的coroutines。从coroutine表中加载列的字节码必须改为从返回coroutine值的寄存器中复制列的字节码。
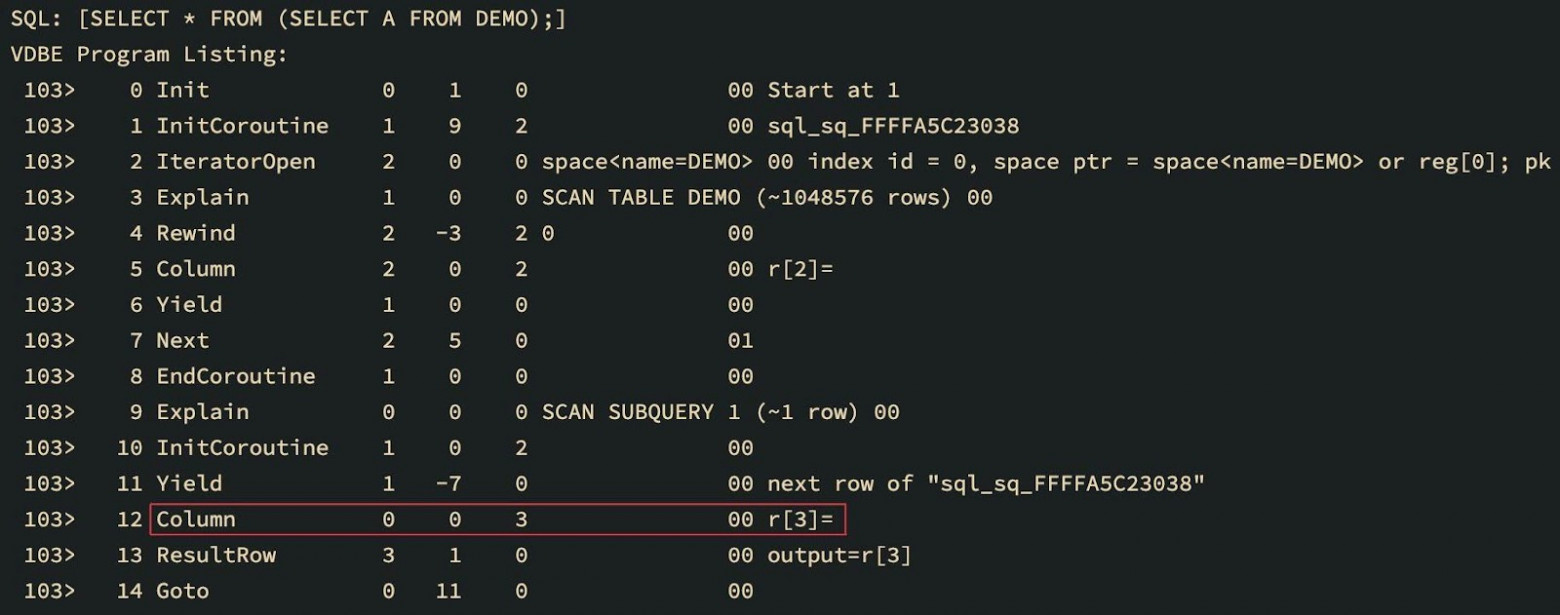 VDBE字节码列表在修补之前和之后
VDBE字节码列表在修补之前和之后
 补丁之后
补丁之后
同样的情况也应该反映在生成的LLVM IR中。从IR的角度来看,这个问题的解决方案是显而易见的:为每个操作码使用一个单独的基础块。这将使分析、搜索和修补所需指令变得更加容易。它甚至可以允许扔掉整个块,用其他块来代替它们。而且所有这些都是非线性的!
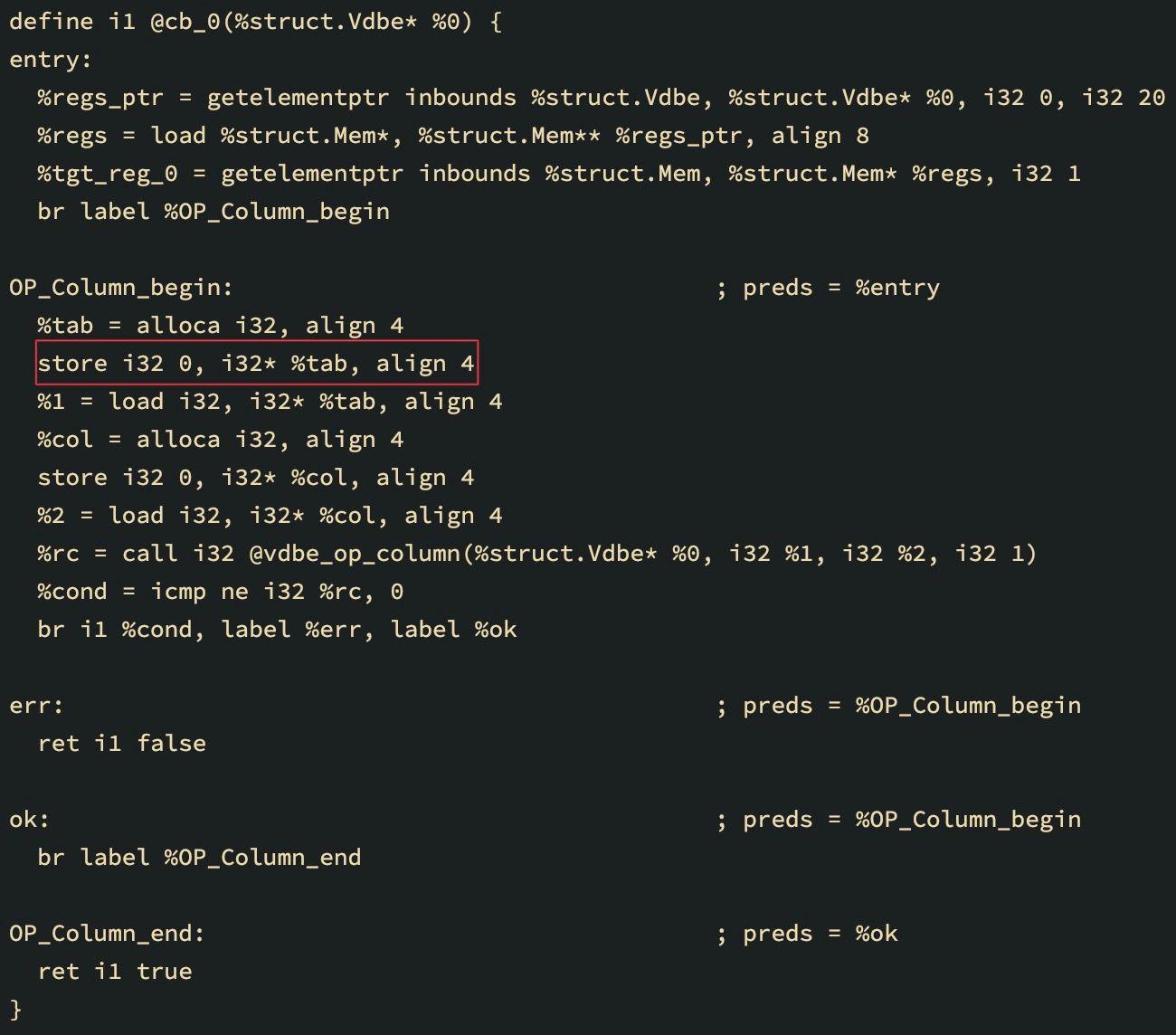 LLVM IR用于加载一个列在修补之前和
LLVM IR用于加载一个列在修补之前和
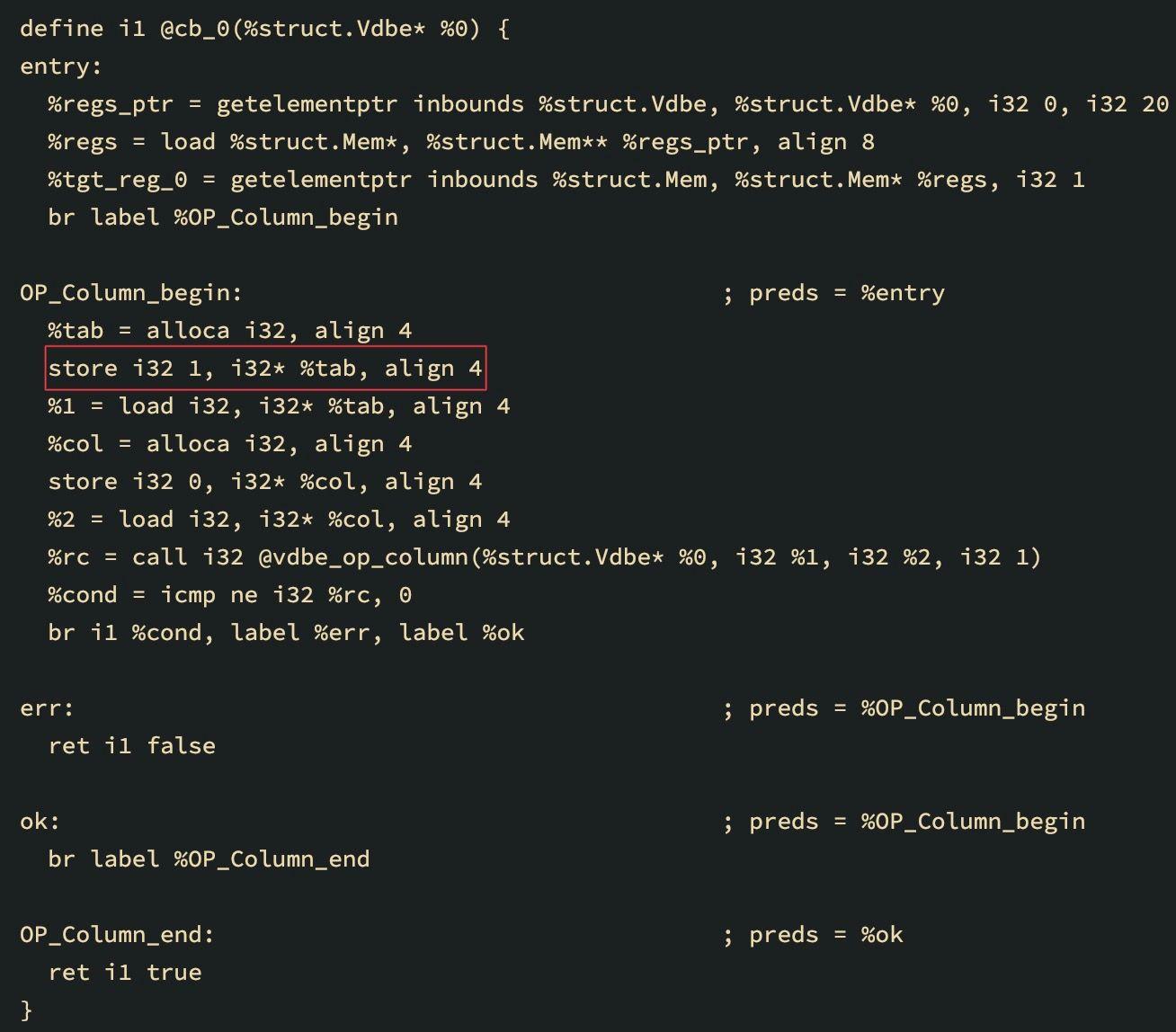 补丁之后
补丁之后
上面的LLVM IR用于select A from DEMO查询,对应于将一列加载到寄存器。你可以看到基本块OP_Column_begin中存储指令参数的值是如何变化的。
store i32 1, i32* %tab, align 4
下面的LLVM IR是使用一个coroutine为select * from(select A from DEMO)查询生成的:
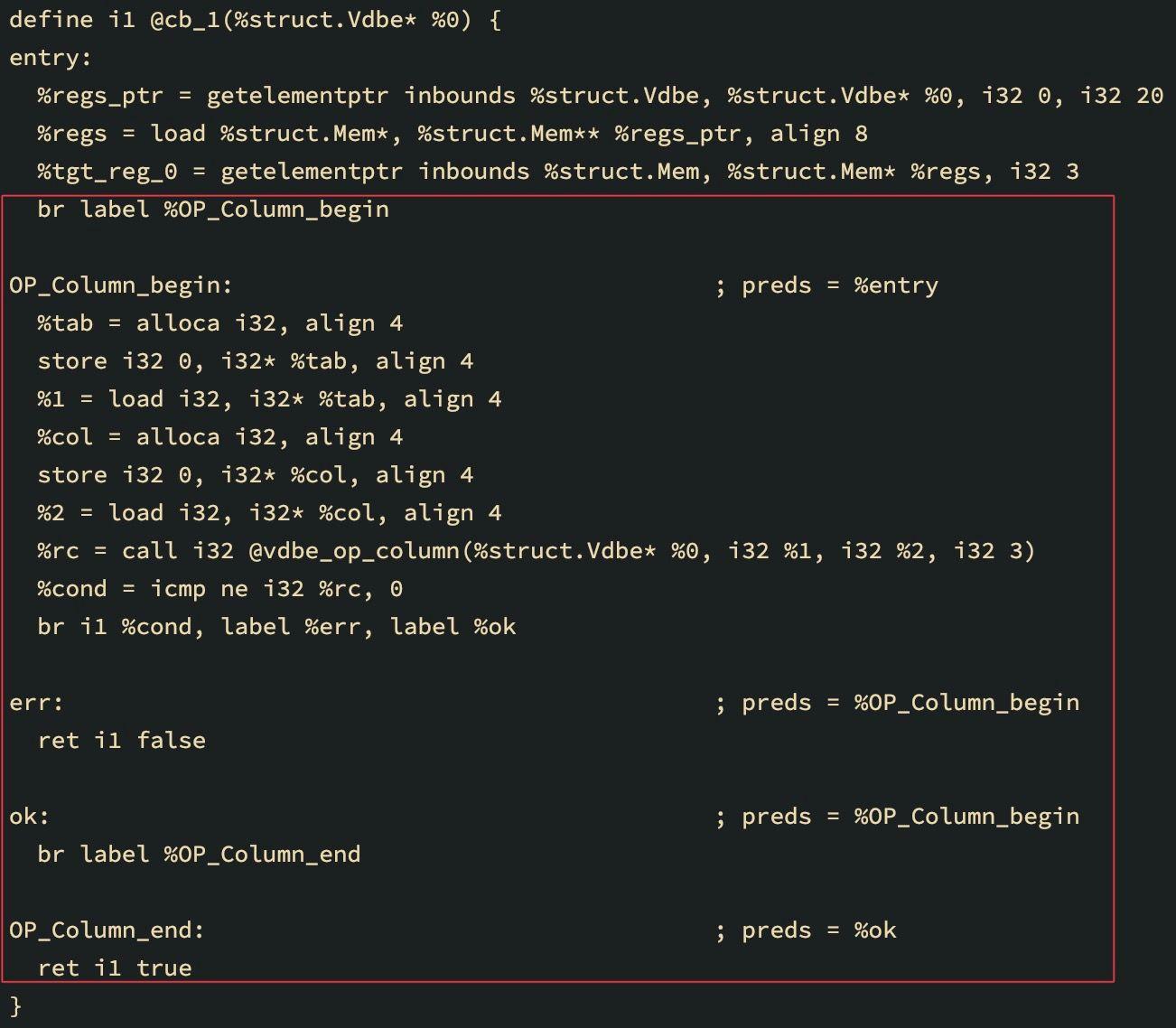 LLVM IR用于在修补前从coroutine表中加载一个列。
LLVM IR用于在修补前从coroutine表中加载一个列。
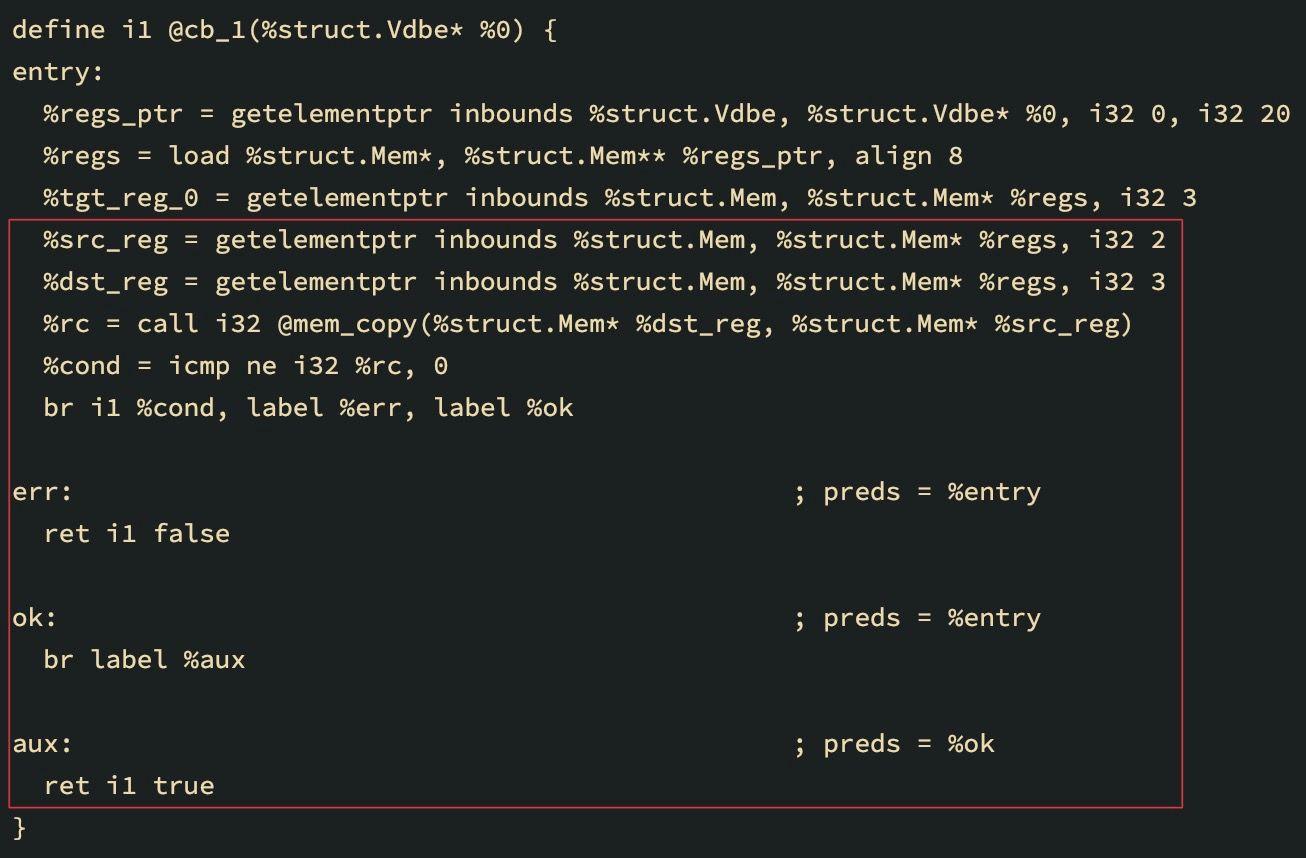 打完补丁后,LLVM IR用于从coroutine的返回值寄存器中复制一列。
打完补丁后,LLVM IR用于从coroutine的返回值寄存器中复制一列。
SQL基准测试
项目的最后一部分是测量标准SQL基准的性能。我把TPC-H作为最有代表性的:它反映了典型的分析性SQL查询。
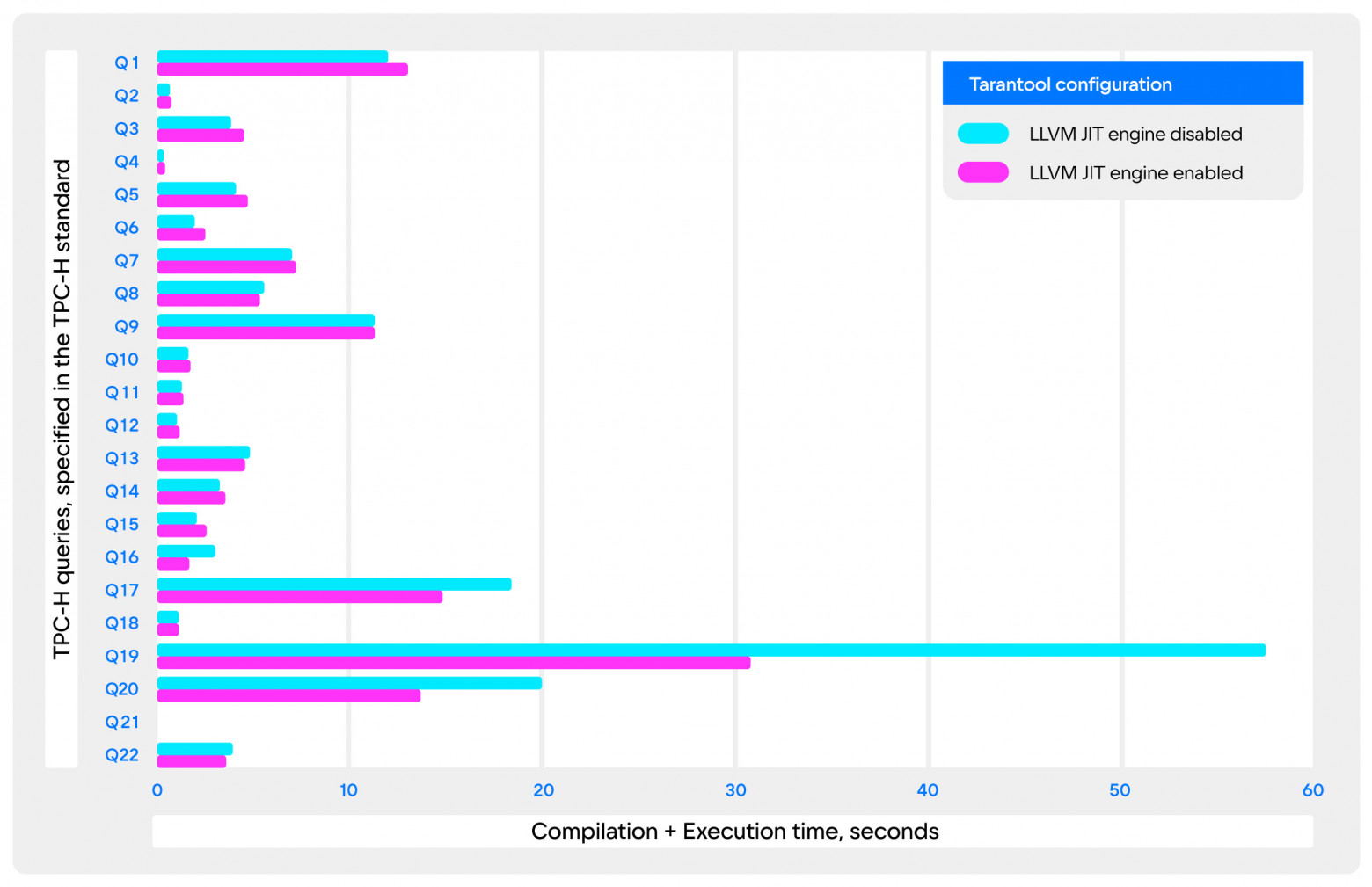 这些测量也考虑到了查询的分析和编译时间,而通常JIT编译应该只用于准备好的查询。如果我们忽略这些开销,我们可以认为JIT编译没有性能损失。
这些测量也考虑到了查询的分析和编译时间,而通常JIT编译应该只用于准备好的查询。如果我们忽略这些开销,我们可以认为JIT编译没有性能损失。
不幸的是,由于我没有时间对算术表达式进行JIT编译,而TPC-H中的大多数查询都含有大量的算术表达式,所以没有什么可以看到的实际情况。只有Q17、Q19和Q20查询是合适的。其中最引人注目的是Q19:它包含了大量的列链接和字面意义--性能的提高几乎是2倍!
结果:
