

优化CQL查询性能的5种方法
与准备好的语句、分页、过滤等有关的专业提示
你已经完成了你的twitter杀毒软件的开发。你听说过NoSQL数据库,并决定使用ScyllaDB,因为它具有亚毫秒级的写入和高可用性。该应用程序看起来也很不错!但后来,你收到同事的邮件,告诉你负载测试有问题。
 ScyllaDB监控仪表板:CQL
ScyllaDB监控仪表板:CQL
上面的截图是ScyllaDB监控仪表盘,更具体的是来自Scylla CQL仪表盘。我们可以清楚地看到红色仪表,表明应用程序中有一些问题。
如何进一步优化你的代码以面对数百万次的操作?这里有五种方法可以让你的CQL查询得到最大的收益。
1.准备好你的语句
我们可以从ScyllaDB CQL仪表板上看到,在我的测试过程中,99%的查询是没有准备好的语句。为了理解这意味着什么以及它是如何影响性能的,让我们来谈谈在ScyllaDB中如何执行查询。
 ScyllaDB CQL仪表板上的非预处理语句
ScyllaDB CQL仪表板上的非预处理语句
你可以像这样使用execute函数运行一个查询。
CQL
rows = session.execute(‘SELECT name, age, email FROM users’)
for user_row in rows:
print user_row.name, user_row.age, user_row.email
上面的查询是一个简单语句的例子。当执行时,ScyllaDB将再次解析查询字符串,而不使用缓存。如果你经常运行相同的查询,这是不高效的。
 如果你经常执行相同的查询,可以考虑使用Prepared Statements来代替。
如果你经常执行相同的查询,可以考虑使用Prepared Statements来代替。
CQL
user_lookup_stmt = session.prepare(“SELECT * FROM users WHERE user_id=?”)users = []
for user_id in user_ids_to_query:
user = session.execute(user_lookup_stmt, [user_id])
users.append(user)
当你准备语句时,ScyllaDB将解析查询字符串,缓存结果并返回一个唯一的标识符。当你执行准备好的语句时,驱动程序将只发送标识符,这允许跳过解析阶段。此外,你可以保证你的查询将被持有数据的节点执行。
 第1步:解析查询并返回语句ID
第1步:解析查询并返回语句ID
 第2步:发送id和值
第2步:发送id和值
2.分页你的查询
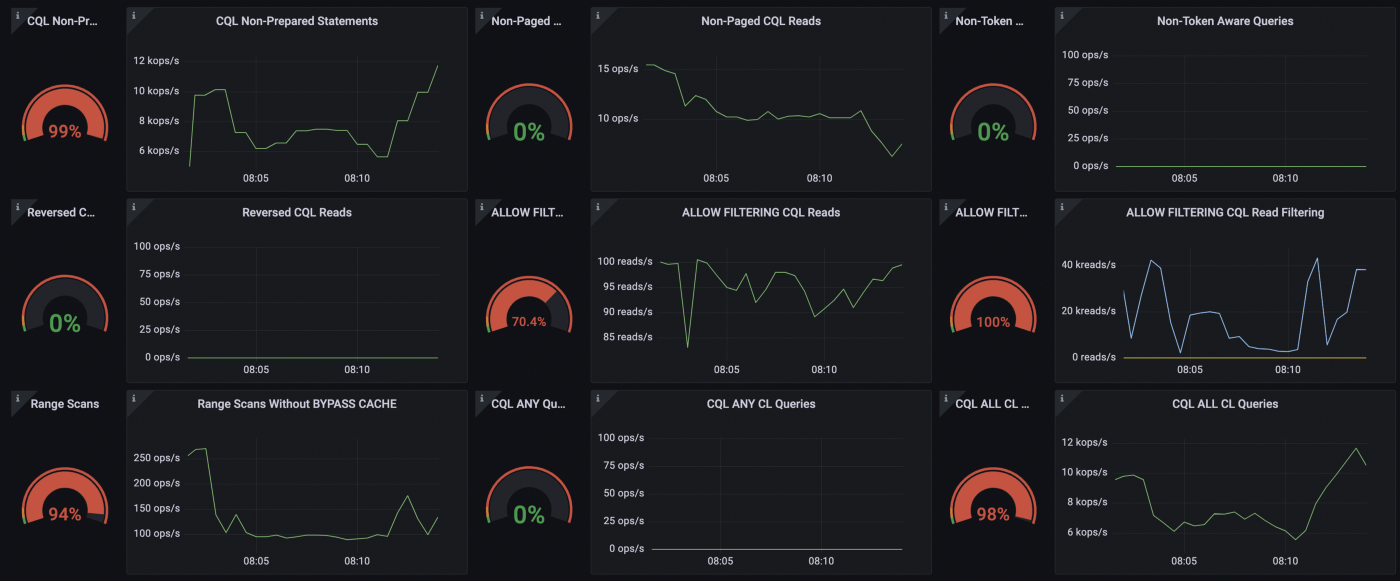
我们可以从下图中观察到,我的查询中只有很少一部分是不分页的。然而,如果我们考虑到每个查询都会触发对整个表的扫描,而客户可能不需要整个数据,我们就可以理解这是不高效的。
 ScyllaDB仪表板非分页CQL读取
ScyllaDB仪表板非分页CQL读取
这个可能听起来很明显。如果你的用户持续查询整个表,分页可以极大地改善延迟。要做到这一点,你可以在语句中添加fetch_size参数。
CQL
query = "SELECT * FROM users"
statement = SimpleStatement(query, fetch_size=10)
for user_row in session.execute(statement):
process_user(user_row)
3.避免允许过滤
下面的查询选择所有具有特定名字的用户。
CQL
query = "SELECT * FROM users WHERE name=%s ALLOW FILTERING"
让我们更详细地看看上面的做法。
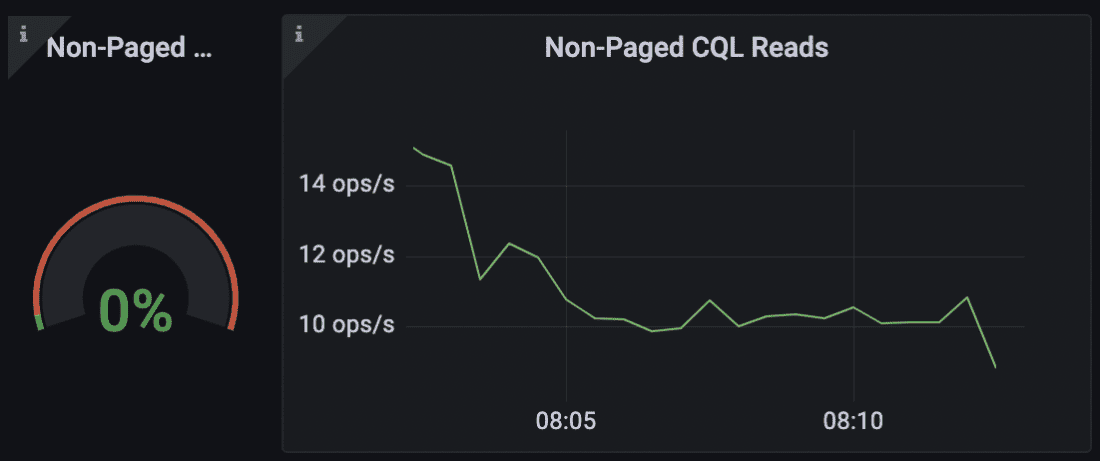
从仪表盘上,我们可以看到,我们每秒只有大约100个读数,理论上可以认为是可以忽略不计的。
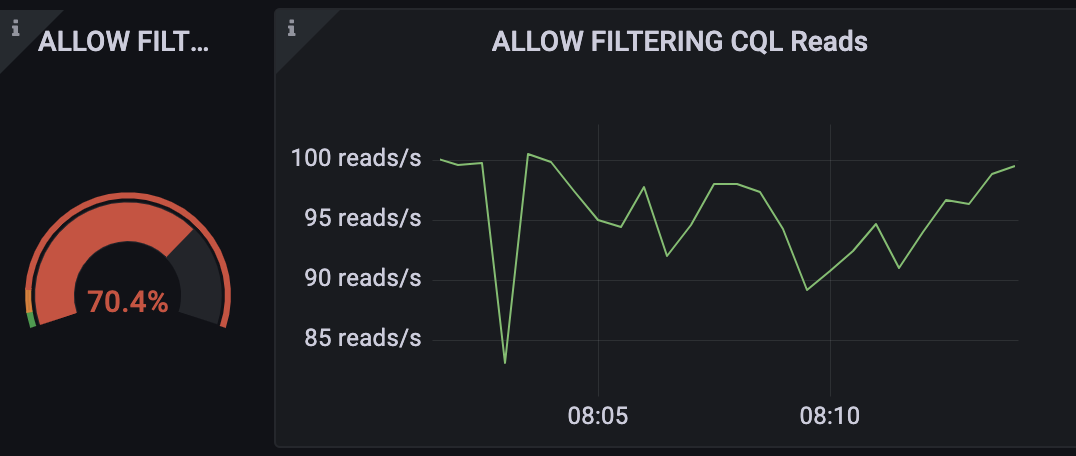 允许过滤cql
允许过滤cql
然而,该查询触发了对整个表的扫描。这意味着查询读取整个用户表只是为了返回几个,这是很低效的。
 由于ScyllaDB的设计方式,使用索引进行查询要有效得多。因此,你的查询将总是找到持有数据的节点,而不需要扫描整个表。
由于ScyllaDB的设计方式,使用索引进行查询要有效得多。因此,你的查询将总是找到持有数据的节点,而不需要扫描整个表。
CQL
query = "SELECT * FROM users WHERE id=%s"
如果你觉得这还不够,你可以考虑重新审视你的模式。
4.绕过缓冲区
出于低延迟的目的,ScyllaDB首先在缓存中寻找你的查询结果。如果数据不在缓存中,数据库将从磁盘上读取。我们使用BYPASS CACHE来避免在缓存中进行不必要的查找,并直接从磁盘上获取数据。
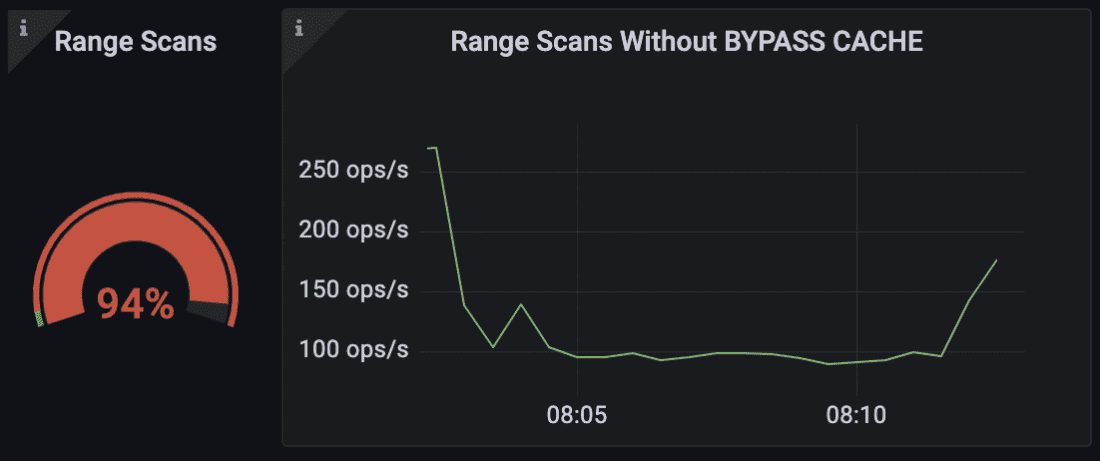 ScyllaDB CQL仪表板范围扫描,没有BYPASS CACHE
ScyllaDB CQL仪表板范围扫描,没有BYPASS CACHE
你可以对罕见的范围扫描使用BYPASS CACHE来通知数据库,数据不太可能在内存中,需要直接从磁盘中获取。这将避免在缓存中进行不必要的查找。
CQL
SELECT * FROM users BYPASS CACHE;
SELECT name, occupation FROM users WHERE userid IN (199, 200, 207) BYPASS CACHE;
SELECT * FROM users WHERE birth_year = 1981 AND country = 'US' ALLOW FILTERING BYPASS CACHE;
5.使用CL=QUORUM
 CL代表的是一致性级别。为了更好地理解它是什么,让我们回顾一下INSERT查询的过程。
CL代表的是一致性级别。为了更好地理解它是什么,让我们回顾一下INSERT查询的过程。
ScyllaDB是一个分布式数据库。集群是由一组节点(或机器)组成的,它们之间相互通信。当客户端发送一个插入查询时,它首先被发送到一个随机节点(协调者),该节点将把数据传递给其他节点以保存其副本。数据被复制到的节点的数量被称为复制因子(Replication Factor)。
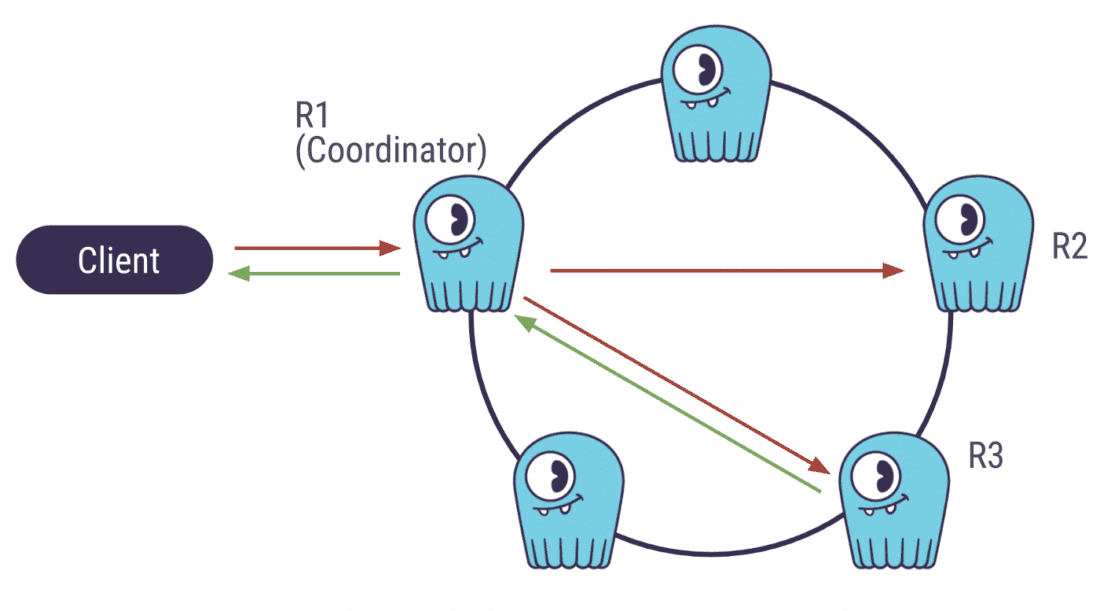 ScyllaDB集群,复制因子=3,一致性级别=Quorum
ScyllaDB集群,复制因子=3,一致性级别=Quorum
QUORUM:它提供了比ONE更好的可用性,比ALL更好的延迟。
当客户端等待数据库的响应时,协调者也需要从复制数据的节点那里获得响应。协调器等待的节点数量被称为一致性级别。
现在让我们回到QUORUM。QUORUM的意思是,协调器在向客户发送自己的响应之前,需要大多数节点发送响应。多数是(复制因子/2)+1。在上述情况下,它将是2。
为什么要使用QUORUM?因为它提供了比ONE更好的可用性,比ALL更好的延迟。
在CL=ONE的情况下,协调器以插入数据的速度向客户端发送响应,而无需等待其他节点。在节点宕机的情况下,数据没有被复制,因此没有高度可用性。
在CL=ALL的情况下,协调器需要所有节点的响应,以便对客户端作出响应,这就增加了延迟。
结论
一个在开发中表现良好的应用程序在生产中可能面临更多的问题。ScyllaDB监控仪表板描述了你的集群节点的健康状况,并让你很好地了解你的CQL查询的质量以及它们在规模上的表现。考虑在早期阶段使用它,用于开发或测试,以捕获您的代码中的潜在问题,并在它们到达您的用户之前修复它们。
