

Apache Kafka模式和反模式
Apache Kafka提供了数据工程师梦想中的操作简单性。作为一个允许客户发布和读取数据流的消息代理,Kafka拥有一个开源组件的生态系统,当这些组件组合在一起时,可以帮助存储、处理数据流,并以安全、可靠和可扩展的方式与系统的其他部分集成。本参考卡深入探讨了横跨Kafka客户端API、Kafka Connect和Kafka流的精选模式和反模式,涵盖了可靠的消息传递、可扩展性、错误处理等主题。
第一节
Apache Kafka 生态系统的概述
Kafka代理(也被称为节点)是运行Kafka JVM进程的基本构建块。虽然一个Kafka经纪人足以满足开发的需要,但生产系统通常有三个或更多的经纪人(奇数5,7等),以实现高可用性和可扩展性。这些Kafka经纪人组构成一个集群,每个集群都有一个领导者,以及从领导者那里复制数据的跟随者节点。
客户端应用程序向Kafka发送消息,每条消息由一个键(可以是null )和一个值组成。这些消息被存储并组织成主题。它们以只附加的方式被写入主题(很像提交日志),也就是说,一个新的消息总是在一个主题的末尾结束。一个主题有一个或多个分区,每个消息根据密钥的哈希函数的结果被放置在一个特定的分区中(如果密钥是null ,消息会以轮流的方式被引导到一个分区)。这些分区中的数据在Kafka集群中被复制。
图1:Kafka中的主题和分区
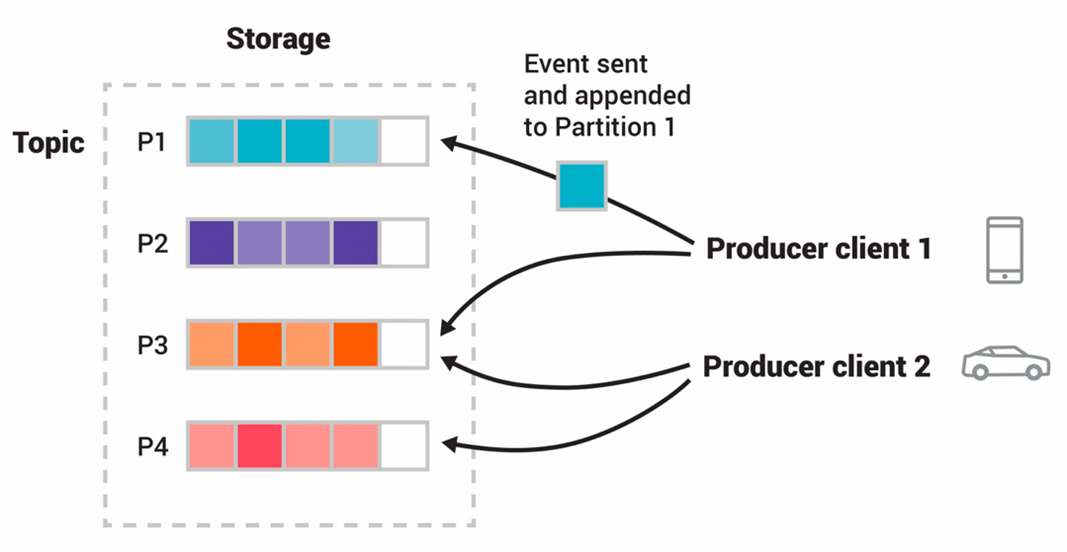
以下是作为核心Kafka一部分的关键项目的总结。
- Kafka客户端API- 生产者和消费者API,允许外部系统分别向Kafka主题写入数据和从Kafka主题读取数据。Kafka有许多编程语言的客户端库,其中Java客户端是Kafka核心项目的一部分。
- Kafka Connect - 提供了一个高层次的框架来构建连接器,帮助Kafka与外部系统集成。它们允许我们将数据从外部系统转移到Kafka主题(Source connector),并从Kafka主题转移到外部系统(Sink connector)。连接器的流行例子包括JDBC连接器和Debezium。
- Kafka Streams - 一个独立的Java库,在Kafka主题的数据之上提供分布式流处理原语。它提供了高层次的API(DSL和Processor),你可以创建拓扑结构,在流数据上执行无状态转换(map、filter等)以及有状态计算(join、aggregations等)。
第二节
常见的Apache Kafka模式和反模式
本节将介绍Kafka生产者和消费者API、Kafka Connect和Kafka Streams的一些常见模式--以及它们各自的反模式。
Kafka客户端API--生产者
Kafka Producer API将数据发送到Kafka集群中的主题。下面是一些需要考虑的模式和反模式。
可靠的生产者
目标 | 在生产消息时,你要确保它已经被发送到Kafka。 |
模式 | 为生产者使用 |
反模式 | 使用默认配置(acks = 1)。 |
acks 属性允许生产者应用程序指定领导者节点在认为请求完成之前应该收到的确认次数。如果你没有明确地提供一个,acks=1 ,默认使用。一旦领导者节点收到消息并将其写入本地日志,客户端应用程序就会收到一个确认。如果消息还没有被复制到跟随者节点和当前的领导者节点,将导致数据丢失。
如果你设置acks=all (或*-1*),你的应用程序只有在集群中所有 同步的复制体都确认了消息时才会收到成功的确认。这里有一个延迟和可靠性/耐用性之间的权衡。等待所有同步复制的确认会产生更多的时间,但只要至少有一个同步复制可用,消息就不会丢失。
一个相关的配置是 min.in.sync.replicas.关于这个主题的指导将在本参考卡的后面介绍。
不再有重复的信息
目标 | 生产者需要是空闲的,因为你的应用程序不能容忍重复的消息。 |
模式 | 设置 |
反模式 | 使用一个默认的配置。 |
生产者应用程序有可能最终向Kafka发送同一消息不止一次。想象一下这样的场景:消息实际上被领导者收到了(如果使用acks=all ,则被复制到同步的副本中),但是由于请求超时,或者领导者节点刚刚崩溃,应用程序没有收到领导者的确认信息。生产者将尝试重新发送消息--如果它成功了,你会在Kafka中出现重复的消息。根据你的下游系统,这可能是不可接受的。
生产者API提供了一个简单的方法,通过使用enable.idempotence 属性(默认设置为false)来避免这种情况。当设置为 "true "时,生产者会给每个消息附上一个序列号。这是由代理验证的,所以一个序列号重复的消息会被拒绝。
从Apache Kafka 3.0开始。 acks=all和 enable.idempotence=true是默认设置的,从而为生产者提供强大的交付保证。
Kafka客户端API - 消费者
通过Kafka Consumer API,应用程序可以从Kafka集群中的主题读取数据。
闲置的消费者实例
目标 | 扩大你的数据处理管道的规模。 |
模式 | 运行你的消费者应用程序的多个实例。 |
反模式 | 消费者实例的数量多于主题分区的数量。 |
Kafka消费者组是一组消费者,他们从一个或多个主题摄取数据。主题分区在组内的消费者之间进行负载平衡。当新的消费者实例被添加或从消费者组中移除时,这种负载分配会被实时管理。例如,如果一个消费者组中有10个主题分区和5个消费者,Kafka将确保每个消费者实例从该主题的两个主题分区中接收数据。
你可能会出现消费者实例的数量与主题分区不匹配的情况。这可能是由于不正确的主题配置,其中分区的数量被设置为一个。或者,也许你的消费者应用程序是用Docker打包的,并在Kubernetes等协调平台上运行,而Kubernetes又可以被配置为自动扩展它们。
请记住。你最终可能会出现实例多于分区的情况。你需要注意的是,这些实例保持不活动,不参与处理来自Kafka的数据。因此,消费者的并行程度与主题分区的数量成正比。在最好的情况下,对于一个有N个分区的主题,你可以在一个消费者组中有N个实例,每个实例处理一个主题分区的数据。
图2:不活跃的消费者

提交偏移量:自动还是手动?
目标 | 在处理来自Kafka的数据时避免重复和/或数据丢失。 |
模式 | 将 |
反模式 | 使用自动偏移管理的默认配置。 |
消费者通过提交他们所读的消息的偏移量来确认收到(和处理)的消息。5 seconds默认情况下,enable.auto.commit 对于消费者应用程序被设置为 "true",这意味着偏移量以固定的时间间隔(由默认为auto.commit.interval.ms property 定义)自动异步提交(例如,由Java消费者客户端的后台线程提交)。虽然这很方便,但它允许数据丢失和/或重复的消息处理。
重复的消息。考虑这样一种情况:消费者应用程序从一个主题分区的偏移量198、199和200读取并处理消息--自动提交过程能够成功提交偏移量198,但之后崩溃/关闭。这将触发对另一个消费者应用程序实例的重新平衡(如果有的话),它将寻找最后提交的偏移量,在这种情况下是198。因此,偏移量199和200的消息将被重新交付给消费者应用程序。
数据丢失。消费者应用程序已经读取了偏移量198、199和200的消息。在应用程序能够实际处理这些消息(也许是通过一些转换并将结果存储在下游系统中)之前,自动提交过程提交了这些偏移量,并且消费者应用程序崩溃了。在这种情况下,新的消费者应用程序实例将看到最后提交的偏移量是200,并将继续从那里读取新消息。来自偏移量198、199和200的消息实际上已经丢失。
为了对提交过程有更大的控制,你需要明确地将enable.auto.commit 设置为false,并手动处理提交过程。手动提交API提供了同步和异步选项,正如预期的那样,每个选项都有其利弊。
下面的代码块显示了如何使用同步API显式提交每个消息的偏移量。
try {
while(running) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(Long.MAX_VALUE));
for (TopicPartition partition : records.partitions()) {
List<ConsumerRecord<String, String>> partitionRecords = records.records(partition);
for (ConsumerRecord<String, String> record : partitionRecords) {
System.out.println(record.offset() + ": " + record.value());
}
long lastOffset = partitionRecords.get(partitionRecords.size() - 1).offset();
consumer.commitSync(Collections.singletonMap(partition, new OffsetAndMetadata(lastOffset + 1)));
}
}
} finally {
consumer.close();
}
Kafka Connect
多亏了Kafka Connect API,有大量现成的连接器。但你需要注意它的一些注意事项。
处理JSON消息
目标 | 使用Kafka Connect从/向Kafka读/写JSON消息。 |
模式 | 使用模式注册表和适当的JSON模式转换器实现。 |
反模式 | 在每个JSON消息中嵌入模式或根本不执行模式。 |
尽管JSON是一种常见的消息格式,但它并没有与之相关的严格的模式。根据设计,Kafka生产者和消费者应用程序是相互解耦的。想象一下这样的场景:你的生产者应用程序为JSON有效载荷/事件引入了额外的字段,而你的下游消费者应用程序没有能力处理,因此失败了--这可能会破坏你的整个数据处理管道。
对于生产级的Kafka Connect设置,你必须使用模式注册表来提供生产者和消费者之间的契约,同时仍然保持它们的解耦。对于源连接器,如果你想从外部系统获取数据,并以JSON的形式存储在Kafka中,你应该将连接器配置为指向模式注册中心,并使用一个适当的转换器。
比如说:
value.converter=<fully qualified class name of json schema converter implementation>
value.converter.schema.registry.url=<schema registry endpoint e.g. http://localhost:8081>
当从Kafka主题读取数据时,sink连接器也需要上述配置。
然而,如果你不使用模式注册中心,下一个最好的选择是使用JSON转换器的实现,这是Kafka的本机。在这种情况下,你将按如下方式配置你的源和汇连接器。
value.converter=org.apache.kafka.connect.json.JsonConverter
value.converter.schemas.enable=true
由于value.converter.schemas.enable=true ,源连接器将为你的每个JSON消息添加一个嵌入式模式有效载荷,而汇连接器也将尊重该模式。这里的一个明显的缺点是,你在每个消息中都有模式信息。这将增加消息的大小,并可能影响延迟、性能和成本等。一如既往,这是一个你需要接受的权衡。
如果上述情况是不可接受的,你将需要通过以下配置做出不同的权衡。
value.converter=org.apache.kafka.connect.json.JsonConverter
value.converter.schemas.enable=false
现在,你的JSON消息将被视为普通字符串,因此容易给你的数据处理管道带来上述的风险。发展你的消息结构将涉及仔细检查和(重新)开发你的消费者应用程序,以确保它们不会因变化而中断--你需要不断保持它们的同步(手动)。
另一件需要注意的事情是为源和汇连接器使用相同的配置。不这样做会导致问题。例如,如果你产生没有模式的消息,并在你的汇配置中使用value. converter.schemas.enable=true ,Kafka Connect将无法处理这些消息。
Kafka Connect中的错误处理
目标 | 处理你的Kafka Connect数据管道中的错误。 |
模式 | 使用一个死字队列。 |
反模式 | 使用默认配置,从而忽略了错误。 |
当你使用Kafka拼接多个系统并构建复杂的数据处理管道时,错误是不可避免的。根据你的具体要求,计划如何处理它们是很重要的。除了特殊情况外,你不希望你的数据管道仅仅因为出现错误而终止。但是,在默认情况下,Kafka Connect被配置为完全这样做:
errors.tolerance=none
它说到做到,不容忍任何错误--Kafka Connect任务一旦遇到错误就会关闭。为了避免这种情况,你可以使用:
errors.tolerance=all
但这在孤立的情况下是没有用的。你还应该配置你的连接器使用一个死字队列,这是一个主题,Kafka Connect可以自动将它未能处理的消息路由到这个主题。你只需要在Kafka Connect的配置中为这个主题提供一个名称:
errors.tolerance=all
errors.deadletterqueue.topic.name=<name of the topic>
由于它是一个标准的Kafka主题,你可以灵活地选择如何反省和潜在地(重新)处理失败的消息。此外,你也希望这些信息能出现在你的Kafka Connect日志中。要启用这一点,请添加以下配置:
errors.log.enable=true
一个更好的选择是将失败原因嵌入到消息中。你所需要的就是添加这个配置:
errors.deadletterqueue.context.headers.enable=true
这将提供关于错误的额外上下文和细节,这样你就可以在你的再处理逻辑中使用它。
Kafka流
本节介绍了一些高级选项,以帮助Kafka Streams库进行大规模流处理的场景。
重新平衡及其对交互式查询的影响
目标 | 大型状态存储,在重新平衡期间尽量减少恢复/迁移时间。 |
模式 | 使用备用副本。 |
反模式 | 使用默认配置。 |
Kafka Streams 提供了状态存储,以支持有状态的流处理语义--这些可以与交互式查询相结合,以建立强大的应用程序,其本地状态可以被外部访问(通过RPC层,如HTTP或gRPC API)。
这些状态存储是容错的,因为它们的数据被复制到Kafka的changelog主题中,对状态存储的更新在Kafka中被跟踪并保持最新。在Kafka Streams应用实例发生故障或重启的情况下,新的或现有的实例会从Kafka中获取状态存储的数据。因此,你可以继续使用交互式查询来查询你的应用程序状态。
然而,根据数据量的不同,这些状态存储可能会变得相当大(以10个GB为单位)。在这种情况下,一个重新平衡事件将导致大量的数据被重放和/或从变化日志主题中恢复 - 这可能需要很多时间。然而,在这个时间框架内,你的Kafka流应用程序的状态是无法通过交互式查询得到的。这类似于JVM垃圾回收期间的 "停止世界 "情况。根据你的使用情况,状态存储的不可用性可能是不可接受的。
为了尽量减少这种情况下的停机时间,你可以为你的Kafka Streams应用程序启用备用副本。通过设置num.standby.replicas 配置(默认为0),你可以要求Kafka Streams维护额外的实例,这些实例只是保持你的活动应用程序实例的状态存储的备份(通过从Kafka的changelog主题中读取)。在由于重启或失败而导致的重新平衡的情况下,这些备用副本作为 "温暖 "的备份,可用于服务交互式查询 - 这减少了故障转移的时间长度。
Kafka流中的流-表连接
目标 | 丰富你的Kafka流应用程序中的流数据。 |
模式 | 使用流表连接。 |
反模式 | 为流中的每个事件调用外部数据存储。 |
流处理应用程序的一个要求是能够经常访问外部SQL数据库,以丰富流数据的额外信息。例如,它将从一个现有的客户表中获取客户的详细信息,以补充和丰富订单信息流。
明显的解决方案是查询数据库以获取信息并将其添加到现有的流记录中。
public Customer getCustomerInfo(String custID) {
//query customers table in a database
}
…..
KStream<String, Order> orders = builder.stream(“orders-topic”); //input KStream contains customer ID (String) and Order info (POJO)
//enrich order data
orders.forEach((custID, order) -> {
Customer cust = getCustomerInfo(custID);
order.setCustomerEmail(cust.getEmail());
});
orders.to(“orders-enriched-topic”); //write to new topic
这不是一个可行的选择,特别是对于中大型应用。流中每条记录的数据库调用所产生的延迟很可能会给下游应用带来压力,影响系统的整体性能SLA。
实现这一目标的首选方法是通过一个流-表连接。
首先,你需要将SQL数据库中的数据(以及随后对它的修改)源源不断地输入到Kafka。这可以通过编写一个传统的客户端应用程序来完成,使用Producer API查询和推送数据到Kafka - 但更好的解决方案是使用Kafka Connect连接器,如JDBC源,甚至更好,基于CDC的连接器,如Debezium。
一旦数据在Kafka主题中,你可以使用KTable ,将这些数据读入本地状态存储。这也解决了更新本地状态存储的问题,因为我们已经创建了一个管道,其中数据库的变化将被发送到Kafka。现在,我们的KStream 可以访问这个本地状态存储,用额外的内容来丰富流式数据--这比远程数据库查询要高效得多。
KStream<String, Order> orders = ...;
KTable<String, Customer> customers = ...;
KStream<String, Order> enriched = orders.join(customers,
(order, cust) -> {
order.setCustomerEmail(cust.getEmail());
return order;
}
);
enriched.to(“orders-enriched-topic”);
一般来说
以下模式适用于一般的Kafka,而不是特定于Kafka流、Kafka Connect等。
自动创建主题--是好事还是坏事?
目标 | 使用创建主题,并牢记可靠性和高可用性。 |
模式 | 禁用自动主题创建,并在创建主题时提供明确的配置。 |
反模式 | 依赖于自动创建话题。 |
Kafka主题配置属性(如复制因子、分区计数等)有一个服务器默认值,你可以选择在每个主题基础上覆盖。在没有明确配置的情况下,会使用服务器默认值。这就是为什么你需要注意你的Kafka代理的auto.create.topics.enable 配置。它默认设置为true ,并且它创建的主题具有默认设置,例如:
- 复制因子被设置为1--从高可用性和可靠性的角度来看,这并不是好事。推荐的复制系数是3,这样你的系统可以容忍两个经纪商的损失。
- 分区数被设置为1--这严重限制了你的Kafka客户端应用程序的性能。例如,你只能有一个消费者应用程序的实例(在一个消费者组中)。
保持自动创建话题的功能也意味着你可能会在集群中出现不需要的话题。原因是被生产者应用引用和/或被消费者应用订阅的主题(尚不存在)将被自动创建。
自动创建的主题,其清理策略设置为delete 。这意味着,如果你想创建一个日志压缩的主题,你将会得到一个惊喜
你需要多少个同步复制?
目标 | 在生产消息的同时,要确保它已经被发送到Kafka。 |
模式 | 在配置acks的同时指定最小的同步复制数。 |
反模式 | 只依赖acks [r1]配置。 |
当调整你的生产者应用程序以获得强大的可靠性时,min.insync.replicas 配置与acks属性(在本Refcard的前面讨论过)携手并进。这是一个经纪人级别的配置,可以在主题级别上被重写,其值默认设置为1。
作为一个经验法则,对于一个有三个经纪人、主题复制系数为3的标准Kafka集群,min.insync.replicas ,应该设置为2。这样,Kafka会等待两个同步复制节点(包括领导者)的确认,这意味着你可以在Kafka停止接受写之前承受一个经纪人的损失(由于缺乏最小同步复制)。
第三节
结论
Apache Kafka有一个丰富的项目和API的生态系统。每一个都以配置选项的形式提供了大量的灵活性,这样你就可以调整这些组件以最适合你的使用情况和要求。本参考卡涵盖了其中的几个。我鼓励你参考Apache Kafka的官方文档,深入了解这些领域。
