

理解源代码 - 深入代码库,在本地和生产中理解源代码
通过使用调试器深入了解一个新的代码库,以全面了解项目的内部语义和互动。
如果你有一个新的代码库需要研究,或者拿起一个开源项目。你可能是一个经验丰富的开发者,对他来说,这是简历上的另一个项目。或者,你可能是一个初级工程师,这是第一个 "真正的 "项目。
这并不重要。
对于全新的源代码库,我们仍然一无所知......
经验丰富的前辈可能在发现一些东西和识别模式方面有优势。但是我们没有人能够读懂并真正关注一个有100多万行代码的项目。我们翻阅文档,根据我的经验,这些文档通常与实际的代码库只有一线之差。我们对各种模块进行隔离和假设,但要把它们捡起来却很难。
我们使用IDE工具来搜索连接,但这真的很难。这就像在一队猫咪对它进行了一番蹂躏之后,再去追踪一根纱线......
作为一个有十多年经验的顾问,我每周都会接一些新的客户项目。在这篇文章中,我将描述我用来做这件事的方法。
寻找用法
编程语言可以提供很大的帮助。作为Java开发者,我们很幸运,代码库探索工具 非常可靠。我们可以挖掘代码并找到用法。集成开发环境突出显示未使用的代码,它们在这方面做得很好。但这有几个问题:
- 我们需要知道在哪里找,找得有多深
- 代码可能被测试或API所使用,而用户实际上并没有使用这些代码
- 流程很难通过使用来理解。尤其是异步流
- 没有诸如数据之类的背景来帮助解释代码的流程
一定有比随机梳理源文件更好的方法。
UML生成
另一个选择是从源文件中生成UML图表 。我个人对这些工具的经验不是很好。他们应该是帮助 "大局 "的,但我经常觉得这些工具更令人困惑。
它们将次要的实现细节和未使用的代码提升到了一个令人费解的混乱图表中的同等地位。对于一个典型的代码库,我们需要的不仅仅是一个高层视图。魔鬼就在细节中,我们的看法应该是版本控制中的实际代码库。而不是一些理论上的模型。
调试作为一种学习工具
调试器可以立即解决所有这些问题。我们可以立即验证假设,看到 "真实世界 "的使用情况,并跨过一个代码块来了解其流程。我们可以放置一个断点,看看我们是否已经到达了某段代码。如果达到的频率太高,我们无法弄清楚发生了什么,我们可以把这个断点作为条件。
在使用调试器研究代码库的时候,我养成了一个习惯,那就是在观察中读取变量的值。
这个值在这个时间点上有意义吗?
如果没有,那么我就有东西要看,要搞清楚。有了这个工具,我可以迅速了解代码库的语义。在下面的章节中,我将介绍在调试器中和生产中学习代码的技巧。
这个值在这个时间点上有意义吗?
如果没有,那么我就有东西要看,要搞清楚。有了这个工具,我可以迅速了解代码库的语义。在下面的章节中,我将介绍在调试器和生产中学习代码的技巧。
这个值在这个时间点上有意义吗?
如果没有,那么我就有东西要看,要搞清楚。有了这个工具,我可以迅速了解代码库的语义。在下面的章节中,我将介绍在调试器和生产中学习代码的技巧。
这个值在这个时间点上有意义吗?
如果没有,那么我就有东西要看,要搞清楚。有了这个工具,我可以迅速了解代码库的语义。在下面的章节中,我将介绍在调试器和生产中学习代码的技巧。
这个值在这个时间点上有意义吗"?如果没有,那么我就有东西要看,要搞清楚。有了这个工具,我可以迅速了解代码库的语义。在下面的章节中,我将介绍在调试器和生产中学习代码的技巧。
注意,我使用的是Java,但这应该适用于任何其他编程语言,因为这些概念(大部分)是通用的。
字段观察点
我想大多数开发者都知道字段观察点,只是忘记了它们
"谁改变了这个值,为什么",这可能是开发人员最常问的问题。当我们翻阅代码时,可能有几十个代码流触发了一个变化。但是在一个字段上放置一个观察点,会在几秒钟内告诉你一切。
了解状态突变和传播可能是你在研究代码库时能做的最重要的事情。
返回值
在浏览方法时,理解的最重要的事情之一是返回值。不幸的是,在调试器中,当从一个方法返回时,这些信息往往会 "丢失",并可能错过流程中的关键部分。
幸运的是,大多数IDE让我们动态地检查返回值,看到方法执行后返回的内容。在JetBrains的IDE中,如IntelliJ/IDEA,我们可以启用 "显示方法返回值"。
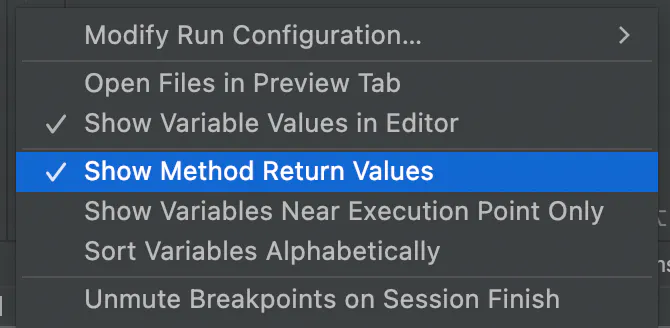
作为学习工具的流程控制
为什么需要这一行?
如果它不在那里会发生什么?
这是一组很常见的问题。通过调试器,我们可以改变控制流,跳转到特定的代码行,或者强制从一个具有特定值的方法中提前返回。这可以帮助我们检查特定行的情况,例如:如果这个方法是以X值而不是Y值被调用的呢?
很简单。只要把执行拖回一点,用不同的值再次调用这个方法。这比阅读深层的层次结构要容易得多。
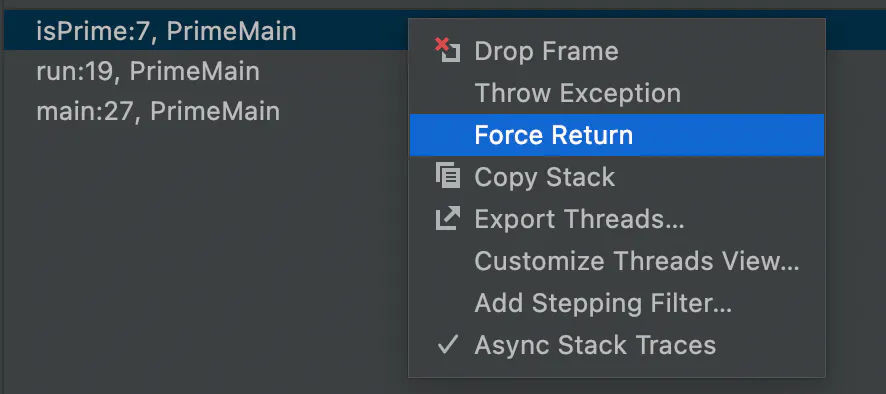
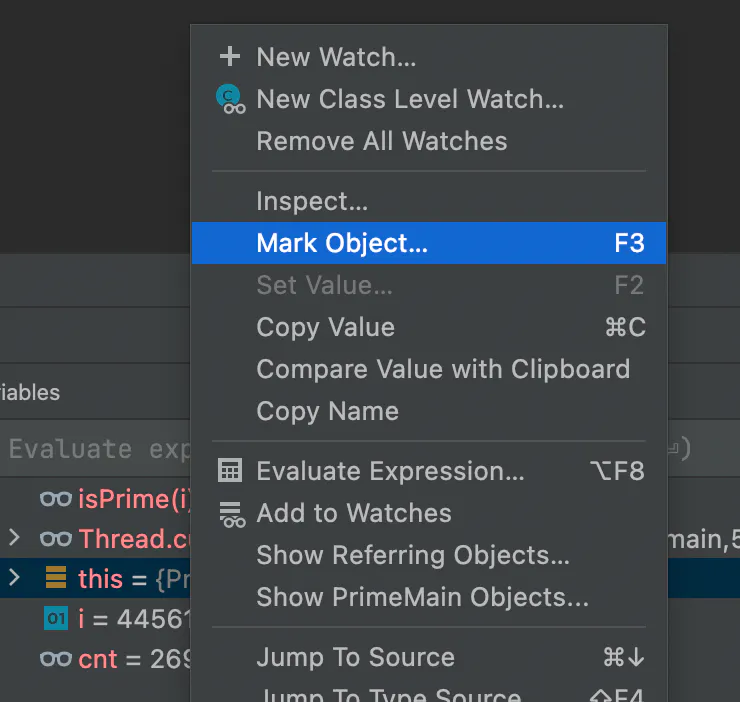
用对象标记保持跟踪
对象标记是那些不为人知的调试器功能之一,它是无价的,而且非常强大。它在理解 "到底发生了什么 "方面有很大作用。
你知道当你调试一个值时,你会写下对象的指针,这样你就可以跟踪 "这个代码块中发生了什么?"。
这就变得非常难以跟踪。所以我们把交互限制在很少的指针上。对象标记让我们跳过这一点,在一个固定的名字下保留对一个指针的引用。即使对象超出了范围,引用标记仍然会有效。我们可以开始跟踪对象,以了解流程,看看事情是如何运作的。例如,如果我们在调试器中看一个用户对象,并想跟踪它,我们可以只保留它的一个引用。然后在用户对象的位置上使用条件断点来检测系统中访问用户的区域。
这在跟踪线程方面也非常有用,这有助于理解线程逻辑复杂的代码。
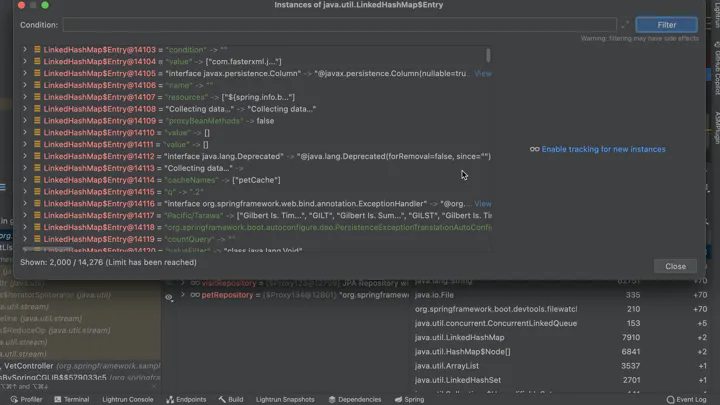
检查内存中的对象
我经常遇到的一个情况是,我在调试器中看到一个组件。但我一直在寻找这个对象的另一个实例。例如,如果你有一个叫做UserMetaData的对象。每个用户对象都有一个对应的UserMetaData对象吗?
作为一个解决方案,我们可以使用内存检查工具,看看内存中保存了哪些给定类型的对象!
看到实际的对象实例值并审查它们有助于将数字/事实放在对象的背后。这是一个强大的工具,帮助我们将数据可视化。
使用Tracepoint语句来跟踪复杂的逻辑
在开发过程中,我们经常只是添加日志来查看 "是否达到这一行"。很明显,断点有优势,但我们并不总是想停止。停止可能会改变线程行为,而且也可能是相当乏味的。
但添加日志可能更糟糕。重新编译,重新运行,不小心就会提交到版本库中。这是一个有问题的调试和研究代码的工具。
值得庆幸的是,我们有 tracepoints,它实际上是让我们打印出表达式的日志,等等。
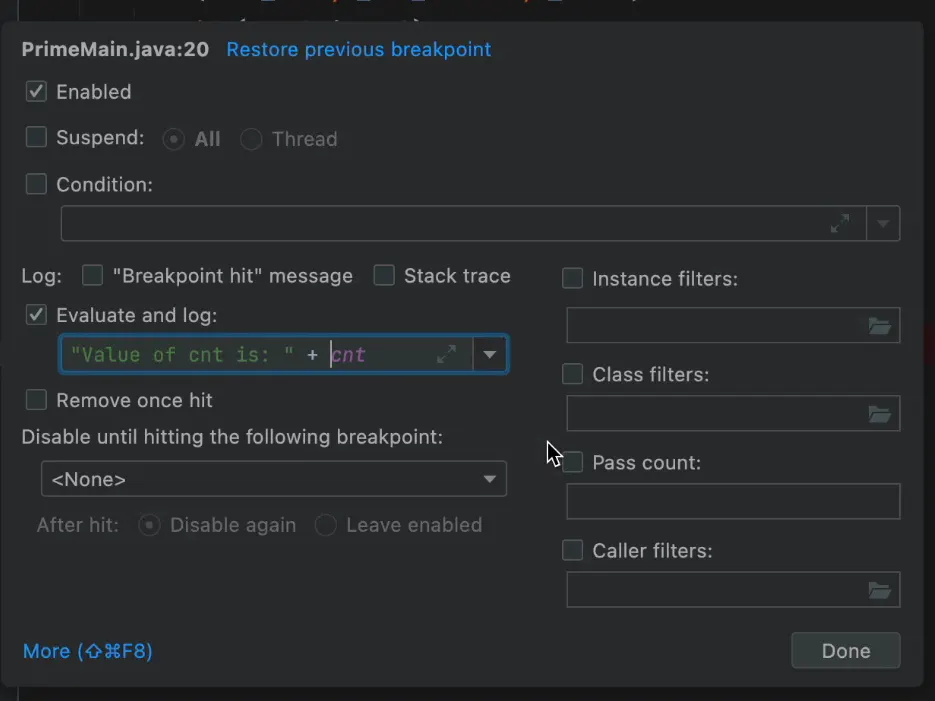 生产中的情况 - 又称 "现实覆盖率"
生产中的情况 - 又称 "现实覆盖率"
这对 "简单 "的系统来说非常有效。但在我们的行业中,有些平台和设置是很难在调试器中重现的。关于我们的代码在本地的工作方式的知识是一回事。它在生产中的工作方式是完全不同的东西。
生产是真正重要的事情,在多人开发的项目中,真的很难评估生产和假设之间的差距。
我们把这称为现实覆盖率。例如,你可以在你的测试中获得80%的覆盖率。但如果你的覆盖率在源代码库中被大量访问的类上很低......那么QA可能就不那么有效了。我们可以一遍又一遍地研究repo。我们可以使用所有的代码分析工具和设置。但他们不会向我们展示真正重要的两件事。
这实际上是在生产中使用的吗?
这在生产中是如何使用的?
没有这些信息,我们可能会浪费我们的时间。例如,在处理 repo 中的数百万行时。你不希望浪费你的学习时间去阅读一个没有被大量使用的方法。
为了深入了解生产情况并对该环境进行调试,我们需要一个开发者观察工具。
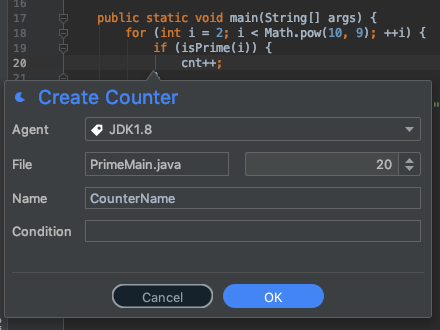
用计数器测量
计数器可以让我们看到某一行代码被达到的频率。这是我们所掌握的最有价值的工具之一。
这个方法是否已经到达?
代码中的这个块是否达到了?多久到达一次?
如果你想了解你的精力首先集中在哪里,计数器可能是你手中最方便的工具。
用条件验证假设
我们经常看着一条语句,并做出各种假设。当代码对我们来说是新的,这些假设可能是我们理解代码的关键所在。一个很好的例子是,大多数使用这个功能的用户已经使用这个系统有一段时间了,应该对它很熟悉。
你可以用条件语句来测试,你可以把这些条件语句附加到任何动作(日志、计数器、快照等)。因此,我们可以使用一个条件,如user.signupDate.getMillis() < … 。
你可以将其添加到一个计数器中,并从字面上计算不符合你期望的用户。
日志和管道,在没有噪音的情况下学习
我想很明显,在运行时注入一个日志可以使我们对系统的理解有很大的不同。但在生产中,这是有代价的。我在研究系统的同时查看日志,而我所有的 "methodX达到值Y "的日志给我们可怜的DevOps/SRE团队增加了噪音。
我们不能有这种情况。研究一些东西应该是孤独的,但根据定义,生产是完全相反的......
有了管道,我们可以把所有的东西都记录在本地的IDE中,让其他人不受噪音的影响。由于逻辑是沙盒式的,如果你记录的太多,就不会有开销。所以,尽情发挥吧!

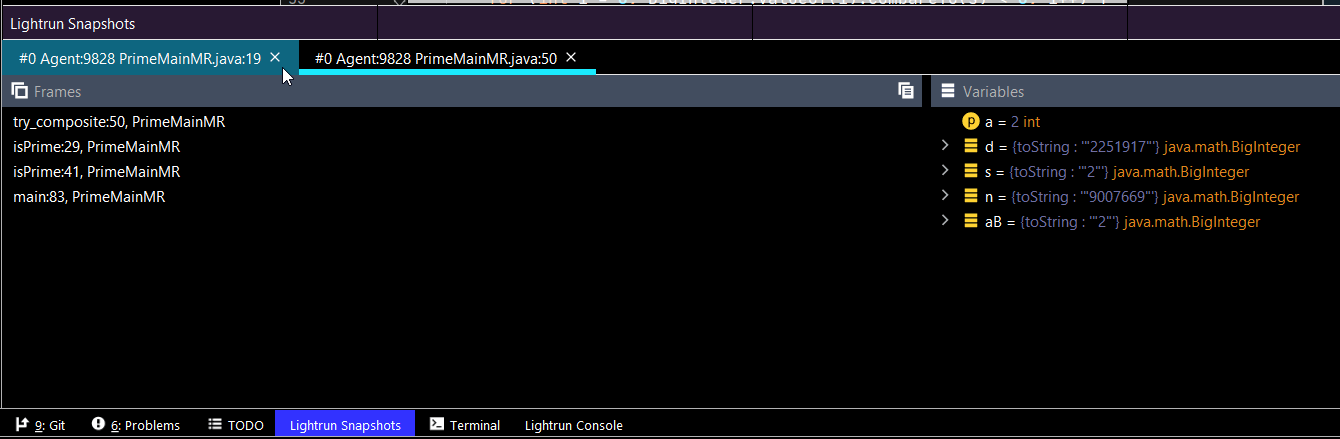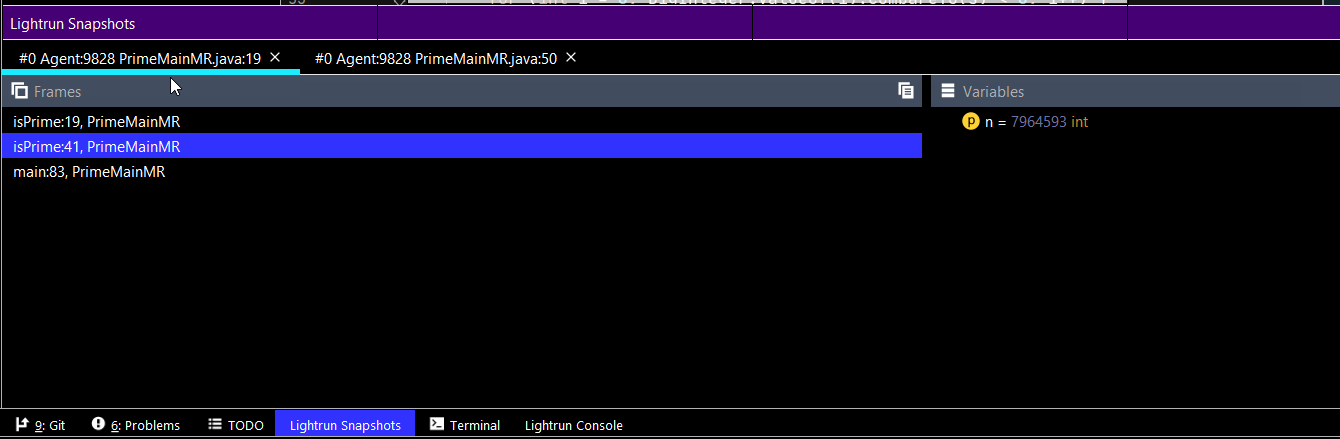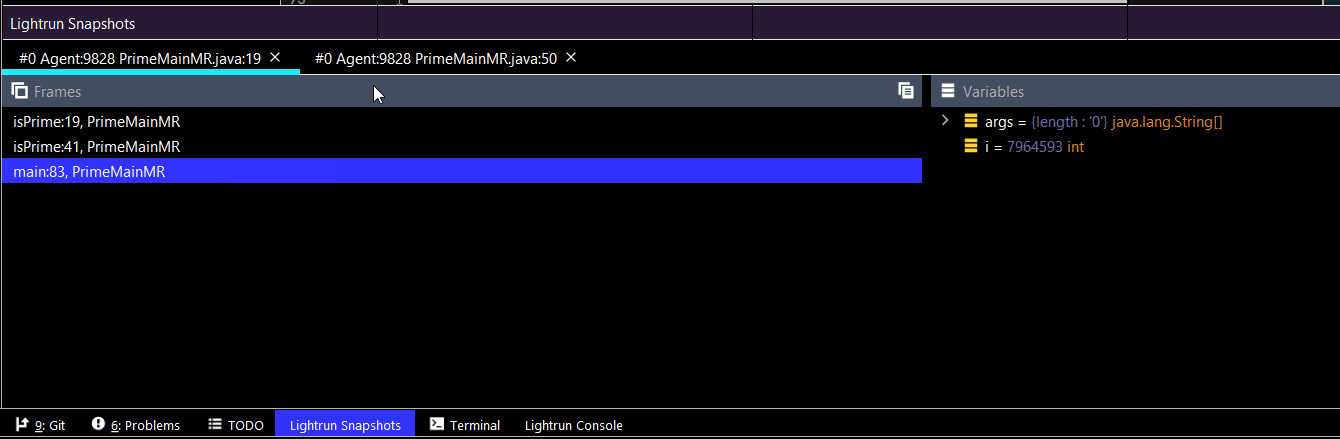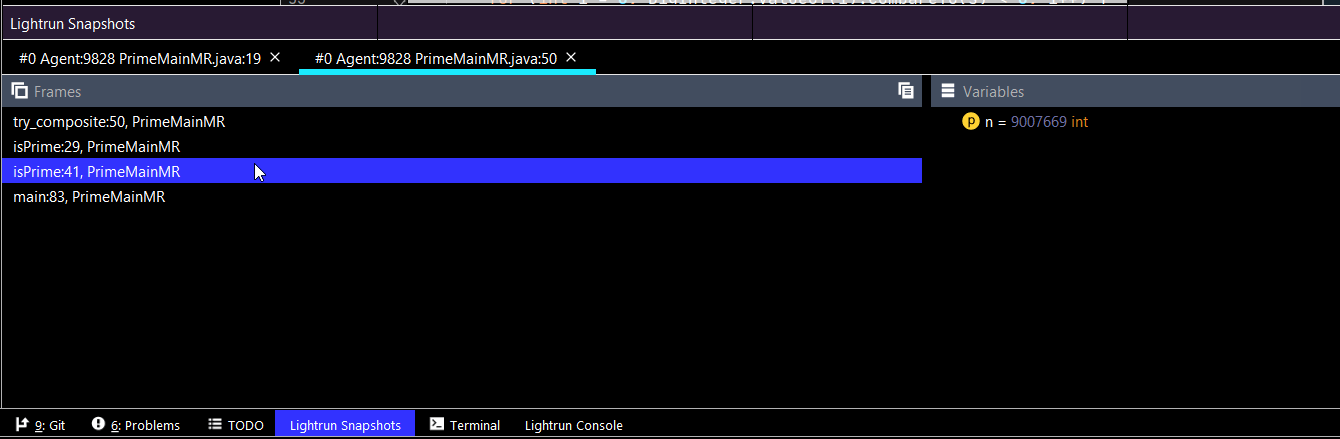
简化学习的快照
学习中的一个巨大挑战是理解我们 "还不知道 "的东西。快照可以帮助我们对代码有一个更全面的认识。快照就像放置任何断点和审查堆栈中的变量值一样,看看我们是否理解了这些概念。它们只是 "不中断",所以你可以得到所有你可以用来研究的信息,但系统仍然照常执行,包括线程行为。
同样,使用条件快照对于准确定位一个特定的问题非常有帮助。例如,当一个拥有X权限的用户使用这个方法时,会发生什么?
很简单,为该权限放置一个条件快照。然后检查产生的快照,看看变量值是如何被沿途影响的。
 开发人员与调试工具的关系往往很紧张。
开发人员与调试工具的关系往往很紧张。
一方面,他们往往是拯救我们的工具,帮助我们找到错误。另一方面,当我们意识到自己在过去的几个小时里完全是个白痴时,他们又是我们看的工具。
我希望这个指南能够鼓励你在没有错误的时候拿起调试器。运行调试器所提供的洞察力,即使在你没有主动调试的时候,也可以 "改变游戏规则"。
