

这是我参与「第四届青训营 」笔记创作活动的第3天
3 Pulsar
3.1 Pulsar结构介绍
如上图所示,Pulsar主要分为4个部分,第一部分是客户端(Producer端和Consumer端),进行服务发现,消息的生产和消费,与第二层是Broker进行交互,里面会代理Bookkeeper的Ledger,跟第三部分Bookie进行交互,bookie就是Bookkeeper(一个存储服务)的一个组件,ZK负责Broker和Bookkeeper元数据的存储,下面就分模块详细介绍一下
3.1.1 Pulsar Proxy
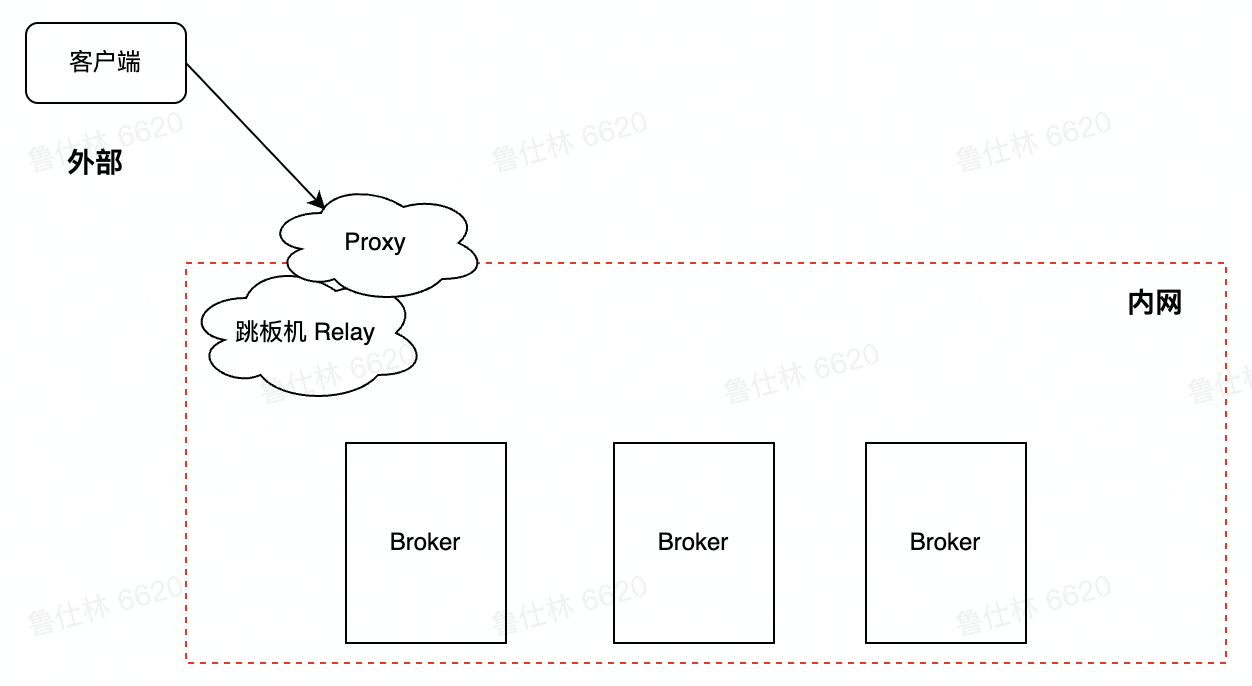
这个模块不是必须部署的,他有以下两个方面的优点
-
Pulsar 客户端连接集群的两种方式
- Pulsar Client -> Broker(大量连接的场景下会被打垮)
- Pulsar Client -> Proxy(无状态,轻量级,能承载更多的连接)
-
云原生体系下的网络隔离
- 云环境或者k8s环境是弹性扩缩容的,这些场景下可能无法知道Broker地址
- Proxy提供类似Gateway代理能力,解耦客户端和Broker,保障Broker安全
3.1.2 Pulsar Broker
-
Pulsar Broker无状态组件,负责运行两个模块
-
Http服务器
- 暴露了restful 接口,提供生产者和消费者topic 查找api
-
调度分发器
- 异步的tcp服务器,通过自定义二进制协议进行数据传输
-
-
Pulsar Broker作为数据层代理
-
Bookie通讯
- 作为Ledger代理负责和Bookie进行通讯
-
流量代理
- 消息写入Ledger存储到Bookie
- 消息缓存在堆外,负责快速响应
-
3.1.3 Pulsar Storage
-
Pulsar数据存储在不同存储中抽象为Segment,定义好抽象之后,即可实现多介质存储
- 分布式Journal系统(Bookeeper)中为Journal/L edger
- 分布式文件系统(GFS/HDFS)中为文件
- 普通磁盘中为文件
- 分布式Blob存储中为Blob
- 分布式对象存储中为对象
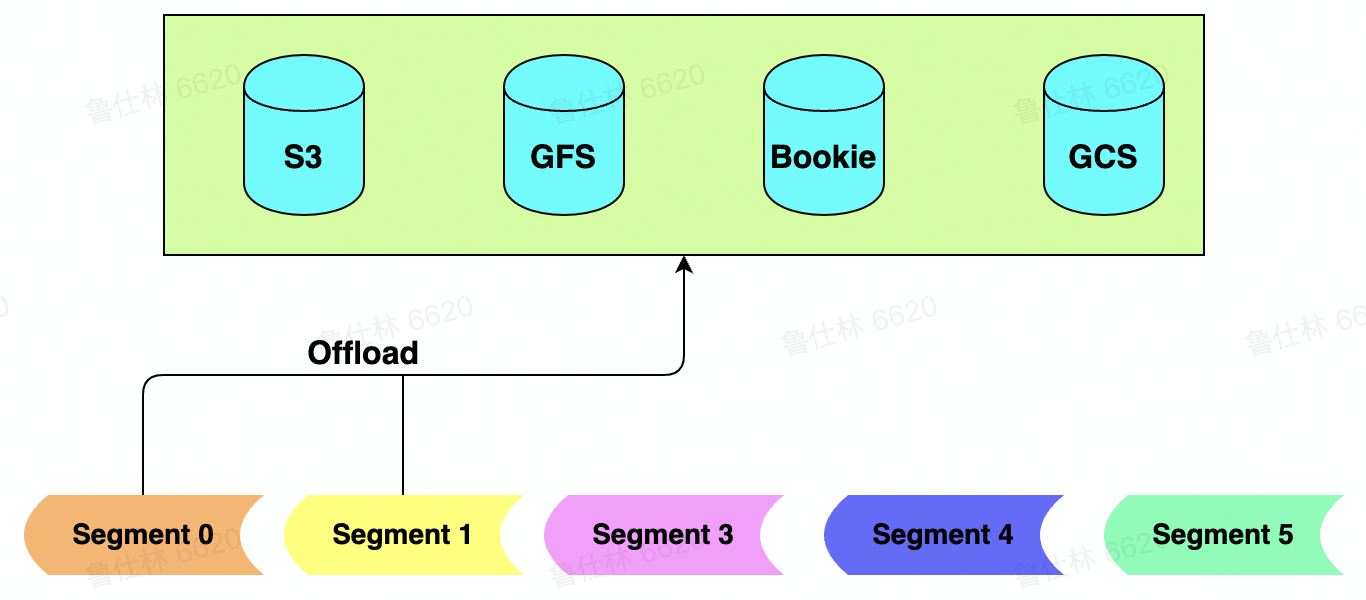
-
可以根据数据实时需求进行多级存储
-
L1(缓存):
- Broker使用堆外内存短暂存储消息
- 适用于Tail-Read读场景
-
L 2(Bookkeeper):
- Bookkeeper使用Qurom写,能有效降低长尾延迟,latency低
- 适用于Catch-Up较短时间内的较热数据
-
L3(S3等冷存):
- 存储成本低,扩展性好
- 适用于Catch-Up长时间内的冷数据
-
3.1.4 Pulsar IO
Pulsar lO分为输入(Input) 和输出(Output) 两个模块,输入代表数据从哪里来,通过Source实现数据输入。输出代表数据要往哪里去,通过Sink实现数据输出。Pulsar提出了IO (也称为 Pulsar Connector),用于解决Pulsar与周边系统的集成问题,帮助用户高效完成工作。目前Pulsar IO支持非常多的连接集成操作:例如HDFS、Spark、 Flink、 Flume、 ES、HBase等。
3.1.5 Pulsar Functions
Pulsar Functions是一个轻量级计算框架, 提供一个部署简单、运维简单、API 简单的FAAS平台。Pulsar Functions提供基于事件的服务,支持有状态与无状态的多语言计算,是对复杂的大数据处理框架的有力补充。使用Pulsar Functions,用户可以轻松地部署和管理function,通过function 从Pulsar topic读取数据或者生新数据到Pulsar topic。
3.2 Bookkeeper介绍
Pulsar中主要还是用Bookkeeper进行存储。Bookkeeper主要分为三个模块,Client模块负责数据的读写,Zookeeper模块负责元数据的存储,bookie模块作为数据的载点。
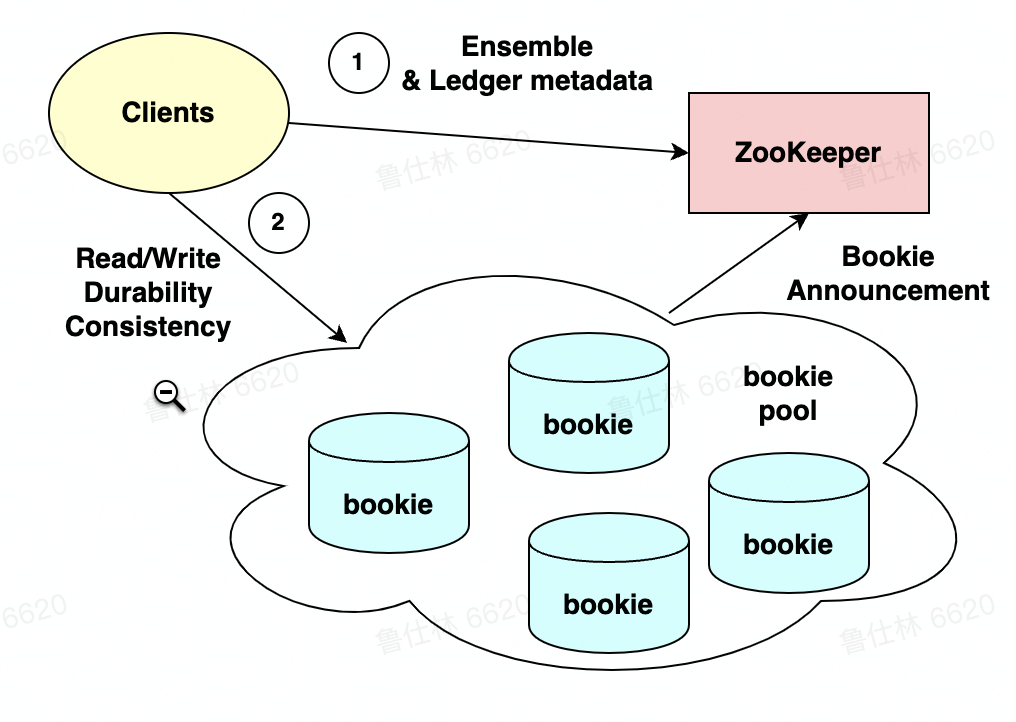
下面这张图是bookie内部的读写流程
3.2.1 Bookkeeper 基本概念
- Ledger: BK的一个基本存储单元,BK Client的读写操作都是以Ledger为粒度的
- Fragment: BK的最小分布单元(实际上也是物理上的最小存储单元),也是Ledger的组成单位,默认情况下一个Ledger会对应的一个Fragment (一个Ledger也可能由多个Fragment组成)
- Entry:每条日志都是一个Entry,它代表一个record,每条record都会有一个对应的entry id
