


Pandas MultiIndex简介
Pandas Multiindex的工作是以Multiindex的度数为分段制作一个Dataframe。由于信息驱动的Python捆绑系统的惊人的生物系统,Python是一种难以置信的信息检查语言。Pandas就是其中之一,它简化了对信息的采集和调查。在收益率中应该是很明显的,该能力利用MultiIndex开发了数据框架。注意数据框架的记录是利用MultiIndex的度数来开发的。
语法和参数:
Multiindex.to_frame(index=True)
其中:
- 索引表示将返回的数据框架的文件设置为第一个MultiIndex。
- 它返回之前存在于多索引数据框架中的数据。
Pandas中的多指标是如何工作的?
现在我们来看看Pandas中多索引工作的各种例子。
例子#1
import pandas as pd
mulx = pd.MultiIndex.from_tuples([(15, 'Fifteen'), (19, 'Nineteen'),
(19, 'Fifteen'), (19, 'Nineteen')], names =['Num', 'Char'])
print(mulx)
输出
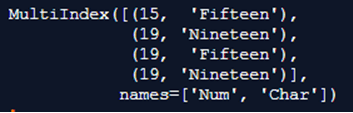
在上面的程序中,我们首先将熊猫的库导入为pd,然后使用multiindex函数来创建一个多索引的数据框架,然后打印出定义好的多索引。
例子 #2
import pandas as pd
mulx = pd.MultiIndex.from_tuples([(15, 'Fifteen'), (19, 'Nineteen'),
(19, 'Fifteen'), (19, 'Nineteen')], names =['Num', 'Char'])
mulx.to_frame(index = True)
print(mulx.to_frame(index = True) )
输出

上面的程序与前面的程序类似,我们首先将pandas导入为pd,然后在multiindex函数里面创建一个数据框架。接下来,我们在数据框架中添加多个索引。然后,我们把index=true的条件放进数据框架中,将数值返回给数据框架。
例子#3
import pandas as pd
mulx = pd.MultiIndex.from_tuples([(15, 'Fifteen'), (19, 'Nineteen'),
(19, 'Fifteen'), (19, 'Nineteen')], names =['Num', 'Char'])
mulx.to_frame(index = False)
print(mulx.to_frame(index = False) )
输出
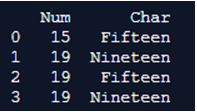
在上面的程序中,我们声明index=false,这样在multiindex函数中定义的指数将被声明为false。因此,当我们打印multiindex时,它会考虑到假值,并打印出如上面快照中所示的输出。
如果你在你的DataFrame的行上做了标记,假设有任何发生这种情况的机会,那么把它们重要地命名是可以接受的。考虑这个测试的一个体面的方法需要为每一列提供一个独特的重要标识符。看一下这些部分,检查是否有符合这些规则的。注意,数据段包含独一无二的数据,所以用数据段来命名每一行是个好兆头。也就是说,你可以利用multiindex()策略使数据段成为DataFrame的记录,如果inplace=True意味着你在原地改变DataFrame df。
这可能会有一点混乱,因为这表示df.columns是Index类型的。这并不意味着这些部分是DataFrame的记录。df的列表不断由df.index给出。这些排序活动有助于照顾到作为数据框架的信息。当我们需要监督大量的信息时,这些pandas的能力是有帮助的,因为我们需要把它改变成数据框架。我们将调查这些能力的句子结构和实例来理解它们的用途。
逾越这一点并存储更高的维度信息是有帮助的,也就是说,由几个以上的键记录的信息。虽然Pandas给出的Panel和Panel4D对象可以在本地处理三维和四维信息,但一个明确的越来越常见的例子是利用各种层次的排序(也叫多排序)来连接一个单独记录内的不同文件层次。像这样,较高维度的信息可以在自然的一维系列和二维DataFrame对象中被最小化地表达。
形成MultiIndex对象,考虑在重复存档的信息中进行排序、切割和登记测量,以及在你的信息的直接和逐步记录的描绘中进行转换的有用时间表,这有助于整个多索引功能和参数的过程。
结语
因此,我想在结束时说,这是由一个单独的部分使用收集完成的。我顺便提一下,你可能需要按几个部分进行收集,在这种情况下,随后的pandas DataFrame就会变成一个多列表或渐进式文件。这篇文章已经让你认识了各种分级列表(或多列表)。你已经感知到它们是如何作为需要一个DataFrame列表来特别和真正地标记你的DataFrame的列的预期结果而出现的。你也已经意识到,当你通过许多分段来组合你的信息时,它们是如何出现的,召唤出分割-应用-合并的准则。我相信你会在你的工作中乱用渐进式列表。
