

讨论用于前端的后端
了解更多关于讨论前端的后端
在过去的好日子里,应用程序很简单。浏览器向网络应用端点发送请求;后者从数据库中获取数据并返回响应。
移动客户端的兴起和与其他应用程序的整合破坏了这种简单性。我想在这篇文章中讨论一个处理复杂性的解决方案。
系统架构的复杂性增加
让我们首先对上述简单的架构进行建模。
 移动客户端改变了这种方法。移动客户端的显示区域更小:对平板电脑来说只是更小,对手机来说则小得多。
移动客户端改变了这种方法。移动客户端的显示区域更小:对平板电脑来说只是更小,对手机来说则小得多。
一个可能的解决方案是返回所有数据,让每个客户端过滤掉不必要的数据。不幸的是,手机客户端也受到较差带宽的影响。不是每部手机都有5G功能。即使是这样,如果它位于荒郊野外,连接点只提供H+,那也没有用。
因此,过度获取不是一个选项。每个客户需要不同的数据子集。有了单体,根据每个客户端提供多个端点是可以管理的。
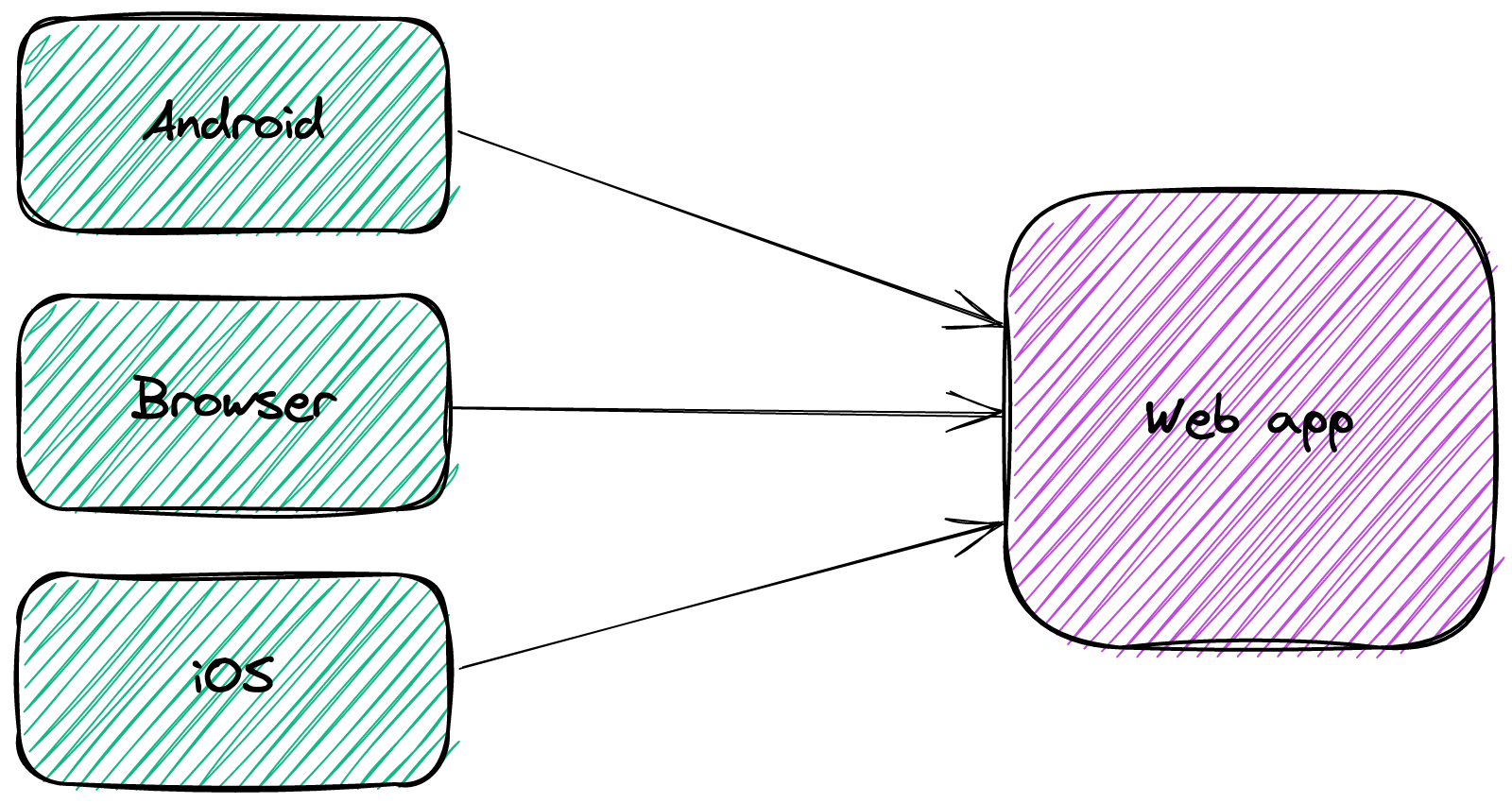 人们可以用一个特定的层来设计一个网络应用,并把它放在最前面。这样一个层可以检测到请求来自哪个客户端,并在响应中过滤掉不相关的数据。网络应用中的过度获取就不是问题了。
人们可以用一个特定的层来设计一个网络应用,并把它放在最前面。这样一个层可以检测到请求来自哪个客户端,并在响应中过滤掉不相关的数据。网络应用中的过度获取就不是问题了。
如今,微服务是风靡一时的。每个人和他们的邻居都想实现一个微服务架构。
在微服务的背后,隐藏着双披萨团队的想法。每个团队都是自主的,负责单个微服务--或单个前端应用。为了避免开发工作之间的耦合,每个微服务团队发布其API合同,并非常谨慎地处理变化。
 每个微服务需要为每一种客户端提供严格必要的数据,以避免上述过度获取的问题。对于少量的微服务,让每个微服务根据客户端过滤掉数据是不方便的;对于大量的微服务,这完全是不可能的。因此,微服务的数量和不同客户端的数量之间的笛卡尔系数使得每个微服务上的专用数据端点的成本呈指数增长。
每个微服务需要为每一种客户端提供严格必要的数据,以避免上述过度获取的问题。对于少量的微服务,让每个微服务根据客户端过滤掉数据是不方便的;对于大量的微服务,这完全是不可能的。因此,微服务的数量和不同客户端的数量之间的笛卡尔系数使得每个微服务上的专用数据端点的成本呈指数增长。
解决方案:前台的后端
BFF背后的想法是将逻辑从每个微服务转移到一个专门的可部署的端点。后者负责:
- 从每个需要的微服务中获取数据
- 提取相关部分
- 聚合它们
- 最后以与特定客户相关的格式返回。
同一团队负责开发客户端及其相关的BFF。BFF提供了与微服务相同的权衡:通过增加系统的复杂性来提高开发速度。
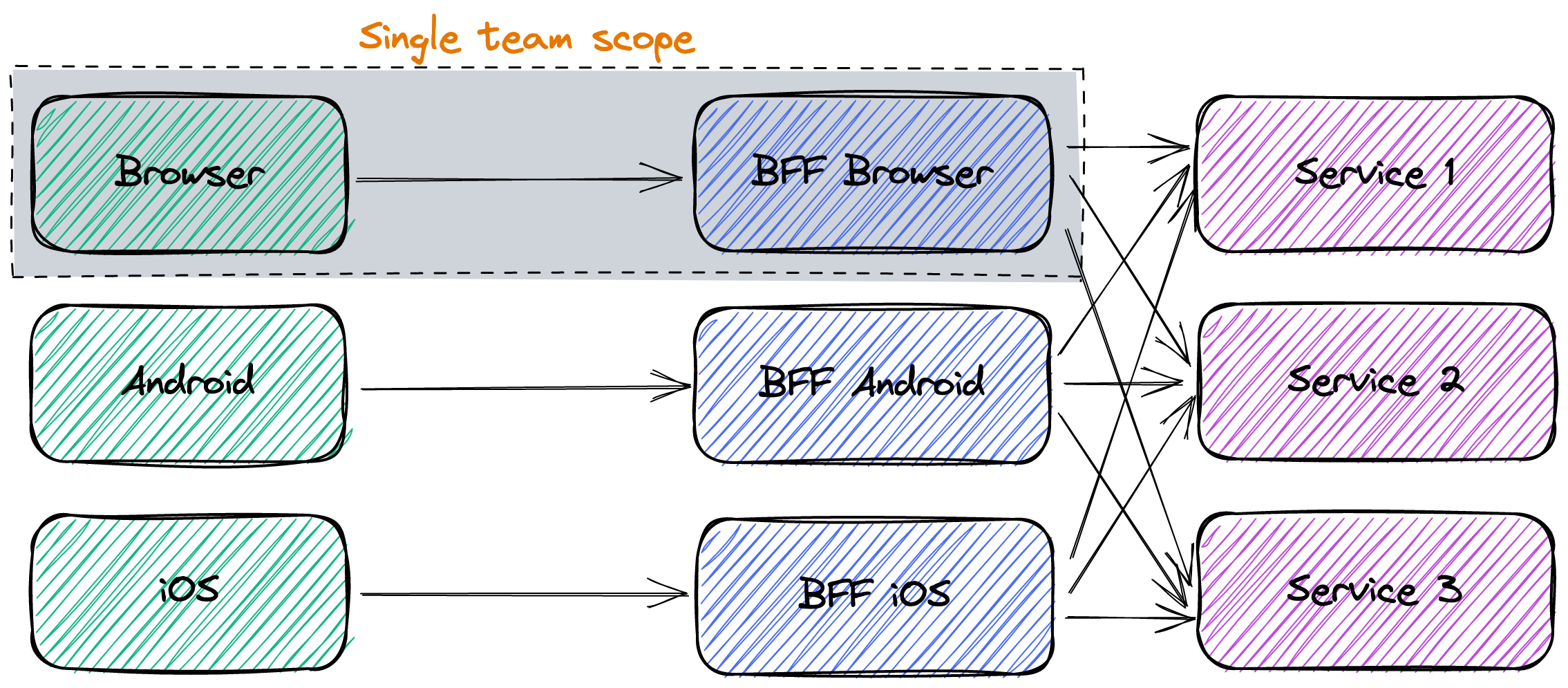 独立的部署单元与API网关
独立的部署单元与API网关
关于BFF的文献意味着专门的部署单元,如上图所示。一些帖子,比如这篇,反对BFF与API网关。但概念图不一定要与部署图一一对应。
像许多领域一样,人们应该更多地关注事物的组织方面,而不是技术方面。在这种情况下,最关键的一点是,负责前端的团队也要对BFF负责。不管它是一个单独的部署单元还是API网关配置的一部分,都是一个实施细节。
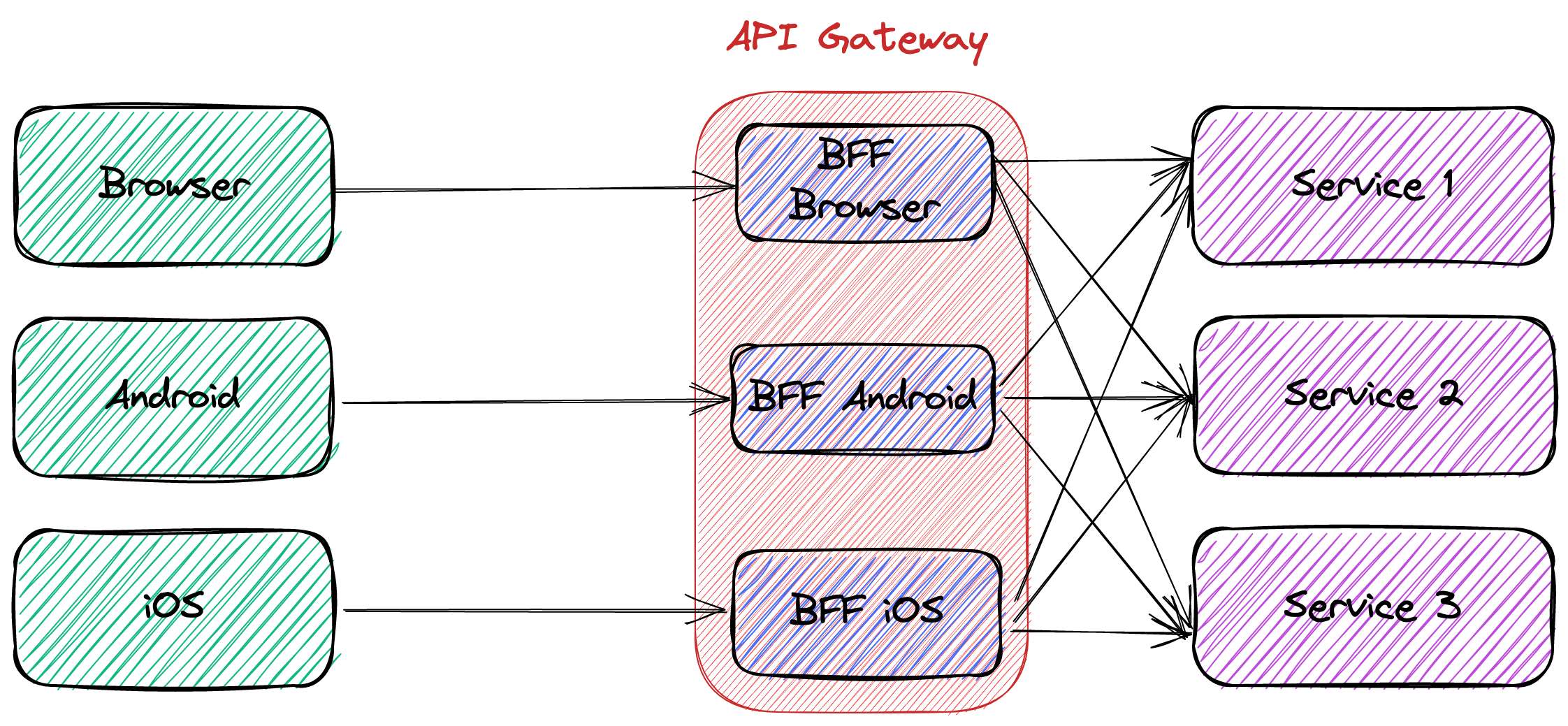 例如,使用Apache APISIX,每个团队可以将他们的BFF代码作为一个单独的插件独立部署。
例如,使用Apache APISIX,每个团队可以将他们的BFF代码作为一个单独的插件独立部署。
性能方面的考虑
对于单片机来说,情况如下:
- 从客户端到单片机的请求需要一个特定的时间T,它通过互联网,而T可能很长。
- 与T相比,对数据库的不同内部调用是可以忽略不计的。
一旦迁移到微服务,客户就需要依次调用每个服务。因此,连续调用的时间变成了Σ (T1, T2, Ti, Tn)。 由于这是不可以接受的,所以客户端一般使用并行调用。时间变成了max(T1, T2, Ti, Tn)。注意,即使这样,客户端也需要执行n个请求。
在BFF的情况下,我们又回到了一个请求,在T时间内,不管是什么实现。与单体相比,从BFF到微服务有额外的请求t1,t2,ti,tn ,但它们可能位于一起。因此,总体时间会比单体的时间长,但由于每个t ,比T 短得多,所以不会对用户体验有太大影响。
结论
你可能不应该实施微服务。如果你这样做,微服务不应该返回整个数据并让客户负责清理它们。因此,微服务需要返回必要的确切数据,这取决于客户端。这在微服务和它的客户端之间引入了一个强耦合。
你想消除这种耦合。为了实现这一点,Backend For Front-end方法将清洁逻辑从每个服务中提取出来,放到一个专门的组件中,也负责聚合数据。每个客户团队也负责其专用的BFF:当客户改变其数据要求时,该团队可以部署一个适应新需求的新BFF版本。
BFF是一个概念性的解决方案。没有任何东西强制要求获取/清理/汇总逻辑必须位于一个特定的位置。它可以是一个专门的部署单元或API网关中的一个插件。
在未来的一篇文章中,我将演示本篇文章中描述的不同步骤。
