

这是我参与「第四届青训营 」笔记创作活动的第6天
Flink作业示例——一个Flink作业在Flink中的处理流程、DataFlow Model设计思想
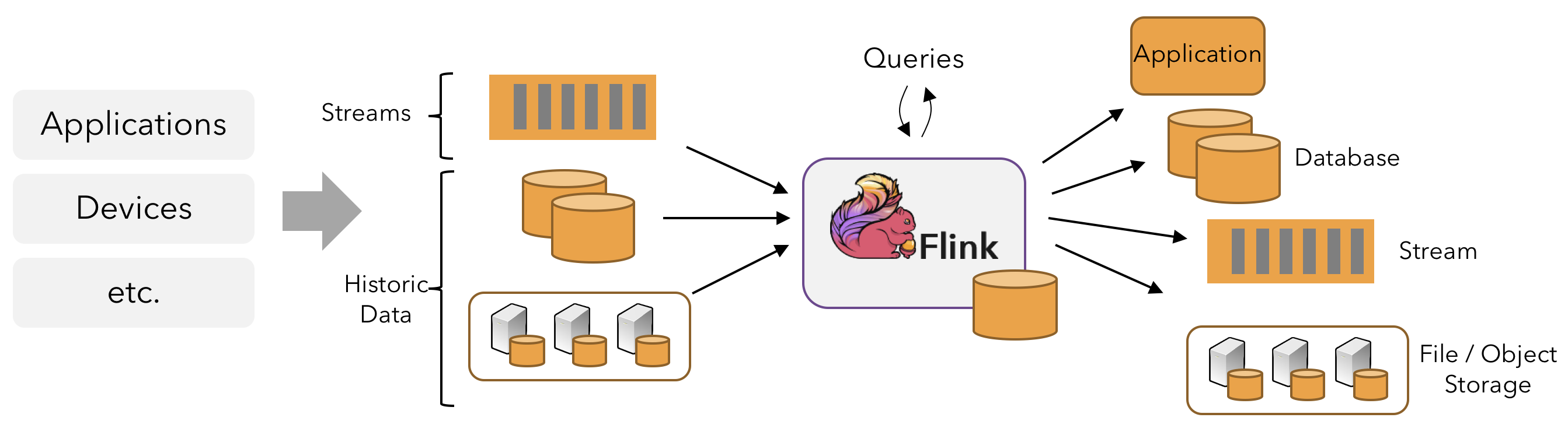
在 Flink 中,应用程序由流数据流组成,这些数据流可能由用户定义的运算符进行转换。这些数据流形成有向图,从一个或多个源开始,以一个或多个接收器结束.
流式的WorkCount示例,从kafka中读取一个实时数据流,每10s统计一次单词出现次数
DataStream实现代码如下:
业务逻辑转换为一个Streaming DataFlow Graph.
通常,程序中的转换与数据流中的运算符之间存在一对一的对应关系。但是,有时一个转换可能由多个运算符组成。
应用程序可能会使用来自流源(如消息队列或分布式日志,如 Apache Kafka 或 Kinesis)的实时数据。但 flink 还可以使用来自各种数据源的有界历史数据。同样,Flink 应用程序产生的结果流可以发送到各种可以作为接收器连接的系统。
假设作业的sink算子的并发配置为1,其余算子并发为2
紧接着会将上面的Streaming DataFlow Graph 转化Parallel Dataflow(内部叫Execution Graph):

最后将上面的Task调度到具体的TaskManager中的slot中执行,一个slot只能运行同一个task的subTask
每个 worker(TaskManager)都是一个 JVM 进程,可以在单独的线程中执行一个或多个 subtask。为了控制一个 TaskManager 中接受多少个 task,就有了所谓的 task slots(至少一个)。
每个 task slot 代表 TaskManager 中资源的固定子集。例如,具有 3 个 slot 的 TaskManager,会将其托管内存 1/3 用于每个 slot。分配资源意味着 subtask 不会与其他作业的 subtask 竞争托管内存,而是具有一定数量的保留托管内存。注意此处没有 CPU 隔离;当前 slot 仅分离 task 的托管内存。
通过调整 task slot 的数量,用户可以定义 subtask 如何互相隔离。每个 TaskManager 有一个 slot,这意味着每个 task 组都在单独的 JVM 中运行(例如,可以在单独的容器中启动)。具有多个 slot 意味着更多 subtask 共享同一 JVM。同一 JVM 中的 task 共享 TCP 连接(通过多路复用)和心跳信息。它们还可以共享数据集和数据结构,从而减少了每个 task 的开销。
默认情况下,Flink 允许 subtask 共享 slot,即便它们是不同的 task 的 subtask,只要是来自于同一作业即可。结果就是一个 slot 可以持有整个作业管道。允许 slot 共享有两个主要优点:
- Flink 集群所需的 task slot 和作业中使用的最大并行度恰好一样。无需计算程序总共包含多少个 task(具有不同并行度)。
- 容易获得更好的资源利用。如果没有 slot 共享,非密集 subtask(source/map() )将阻塞和密集型 subtask(window) 一样多的资源。通过 slot 共享,我们示例中的基本并行度从 2 增加到 6,可以充分利用分配的资源,同时确保繁重的 subtask 在 TaskManager 之间公平分配。

Flink如何做到流批一体——流批一体的业务场景及挑战、Flink如何做到流批一体
为什么需要流批一体
上述架构有一些痛点:
1.人力成本比较高:批、流两套系统,相同逻辑需要开发两遍;
2.数据链路冗余:本身计算内容是一致的,由于是两套链路,相同逻辑需要运行两遍,产生一定的资源浪费;
3.数据口径不一致:两套系统、两套算子、两套UDF,通常会产生不同程度的误差,这些误差会给业务带来非常大的困扰。
流批一体的挑战
流和批业务场景的特点如下表:
批式计算相比于流式计算核心的区别如下表:
