这是我参与「第四届青训营 」笔记创作活动的第2天
1 消息队列概述
1.1 消息队列的应用场景
-
MQ 消息通道:发布(Publishes)订阅(Subscribes)模式
- 异步解耦:上游发布消息到消息队列中,下游无需关注上游的变化,只需订阅就行了
- 削峰填谷:下游出现故障时消息可以缓冲在队列中,可以等恢复之后再处理
- 发布订阅:扩展性非常强
- 高可用:大模块解耦成小模块
-
EventBridge 事件总线
- 事件源:将云服务、自定义应用、SaaS应用等应用程序产生的事件消息发布到事件集
- 事件集:存储接收到的事件消息,并根据事件规则将事件消息路由到事件目标
- 事件目标:消费事件消息
-
Data Platform 数据流平台
- 提供 流/批 数据处理能力
- 各类组件提供各类Connect
- 提供 Streaming/Function 能力
- 根据数据 schema 灵活进行数据预处理
1.2 主流消息队列介绍
| RabbitMQ | RocketMQ | Kafka | Pulsar | |
|---|---|---|---|---|
| 推出时间 | 2007 | 2012 | 2010 | 2016 |
| 使用语言 | Erlang | Java | Scala/Java | Java |
| 单机吞吐量 | 一般 | 较高 | 高 | 高 |
| 延迟 | 低 | 低 | 一般 | 低 |
| 可用性(分片) | 高(主从架构) | 高(主从架构) | 非常高(分布式) | 非常高(分布式) |
| 一致性 | 较高 | 高 | 高 | 高 |
| 扩展性 | 较高 | 高 | 高 | 非常高 |
2 Kafka详解
2.1 Kafka架构介绍
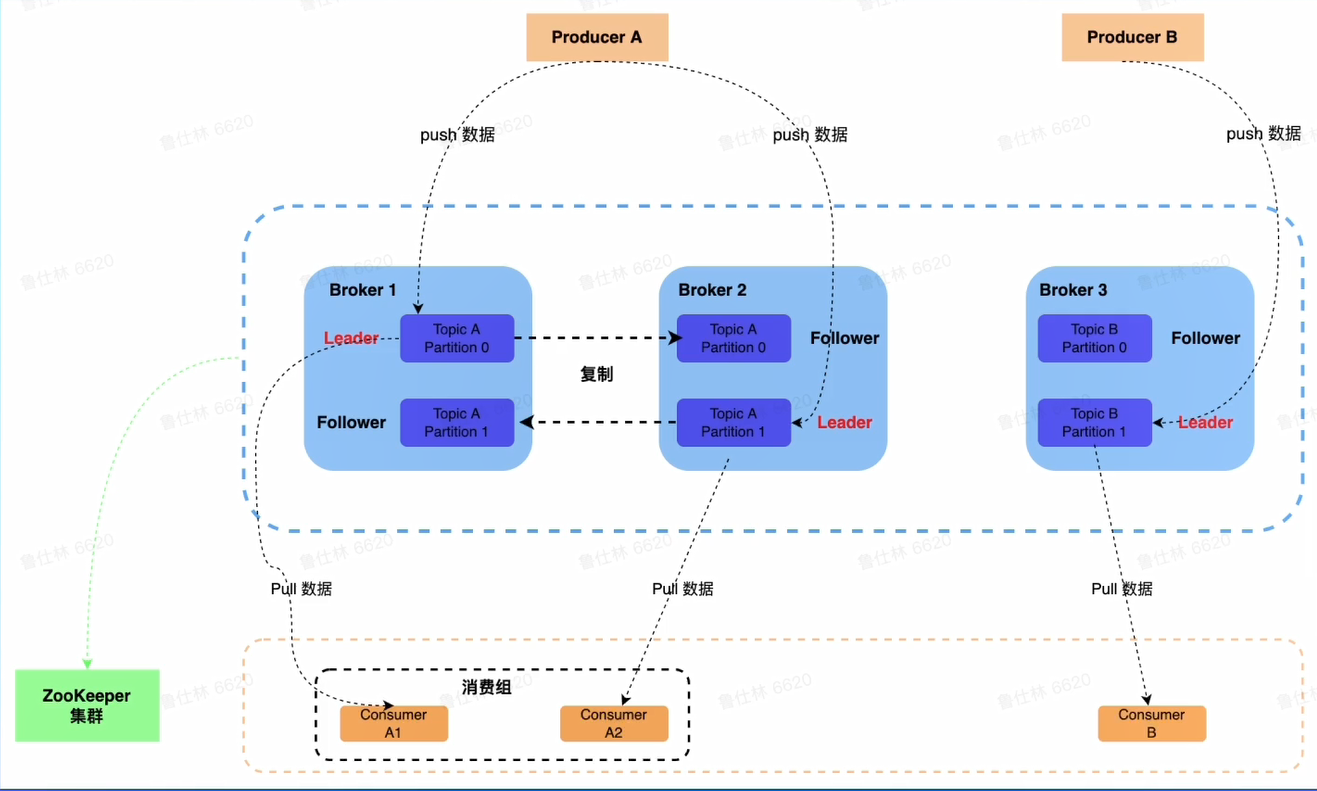
-
Zookeeper
- 选举机制:Paxos算法,即大家投票,少数服从多数
- 提供可用性:一半以上的节点存活即可读写
- 提供功能:watch 机制,持久临时节点能力
下图黄色箭头代表数据流向,紫色箭头代表选举
-
Kafka存储的数据
- Broker Meta 信息(临时节点)
- Controller 信息(临时节点)
- Topic 信息(持久节点)
- Config 信息(持久节点)
-
Broker
- 若干个 Broker节点组成 Kafka 集群
- Broker 作为消息的接收模块,使用 React 网络模型进行消息数据的接收
- Broker 作为消息持久化模块,进行消息的复制以及持久化
- Broker 作为高可用模块,通过副本间的 Failover 进行高可用保证
如下图,每一个 Broker 会有 Leader 节点也会有 Follower 节点。一个 Leader 和一个 Follower 节点往往是分布在两个 Broker 上面的,为了单机节点的宕机容灾。Follower 会从 Leader 处进行数据同步,并且持久化到本地化磁盘中,在网络正常的情况下 Follower 会有 Leader 的大部分数据甚至全量数据的。
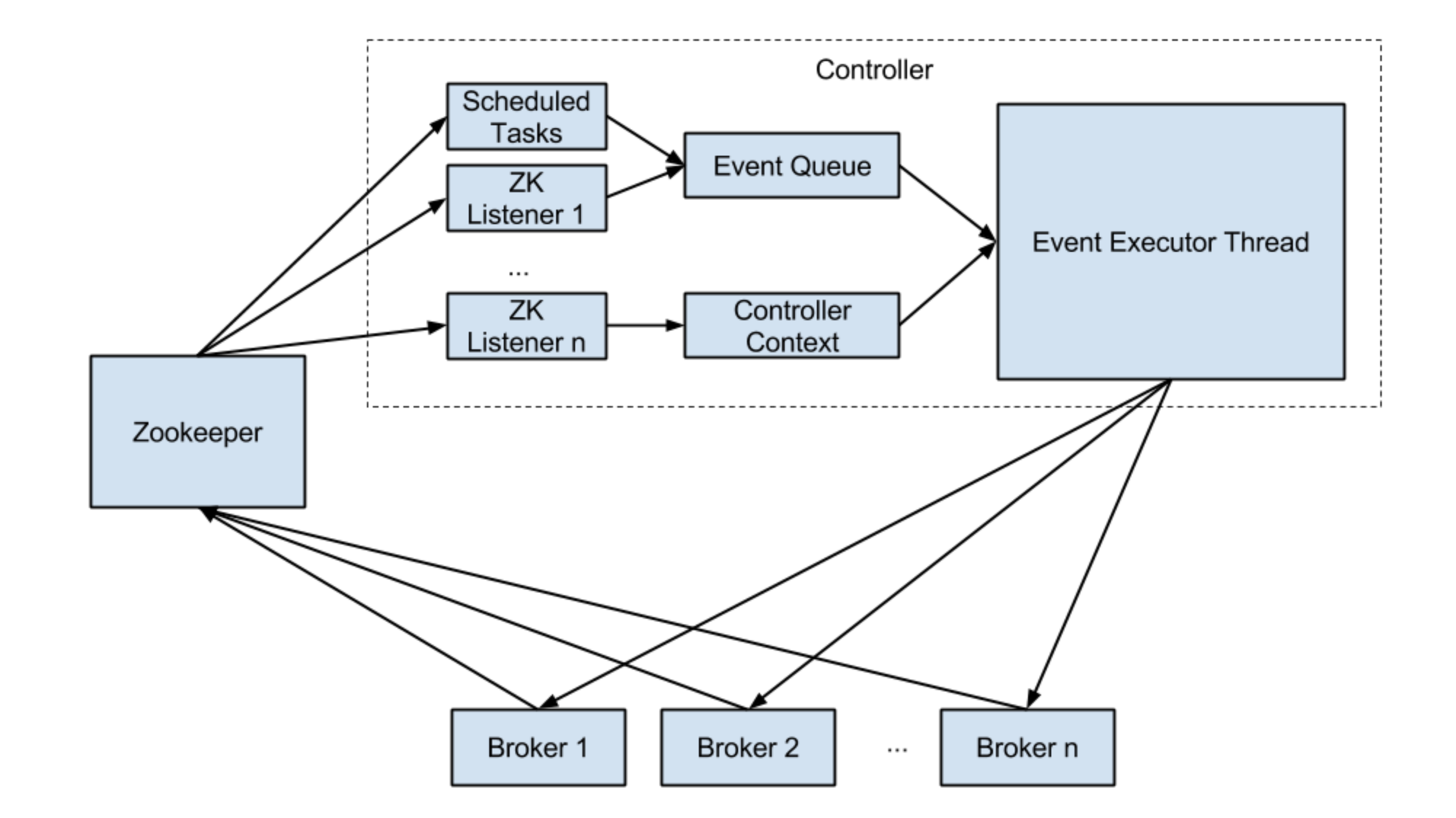
- Controller 选举
分布式系统得有一个中心的节点来掌控集群元数据的变更和决策等,Controller 就是一个比较特殊的 Broker。如下图,broker 启动时会尝试去 zk 中注册 controller 临时节点,zk 提供写能力的强一致性,下面三个节点中只会有一个注册成功,相当于分布式抢锁,抢到的那个节点就会注册成 controller,其余 broker 会 watch controller 节点,节点出现异常则进行重新注册
controller 会监听 zk 的一些事件,加载到 Event Executor 中进行处理,然后广播出去给所有的broker。
controller负责 broker 重启/宕机时副本的 Failover 切换;Topic 创建/删除时,Topic meta 信息的广播;集群扩缩容时状态的控制;Partition/Replica 状态机维护。
-
Coordinator
-
负责 topic-partition <-> consumer 的负载均衡
-
根据不同的场景提供不同的分配策略
- Dynamic Membership Protocol
- Static Membership Protocol
- Incremental Cooperative Rebalance
-
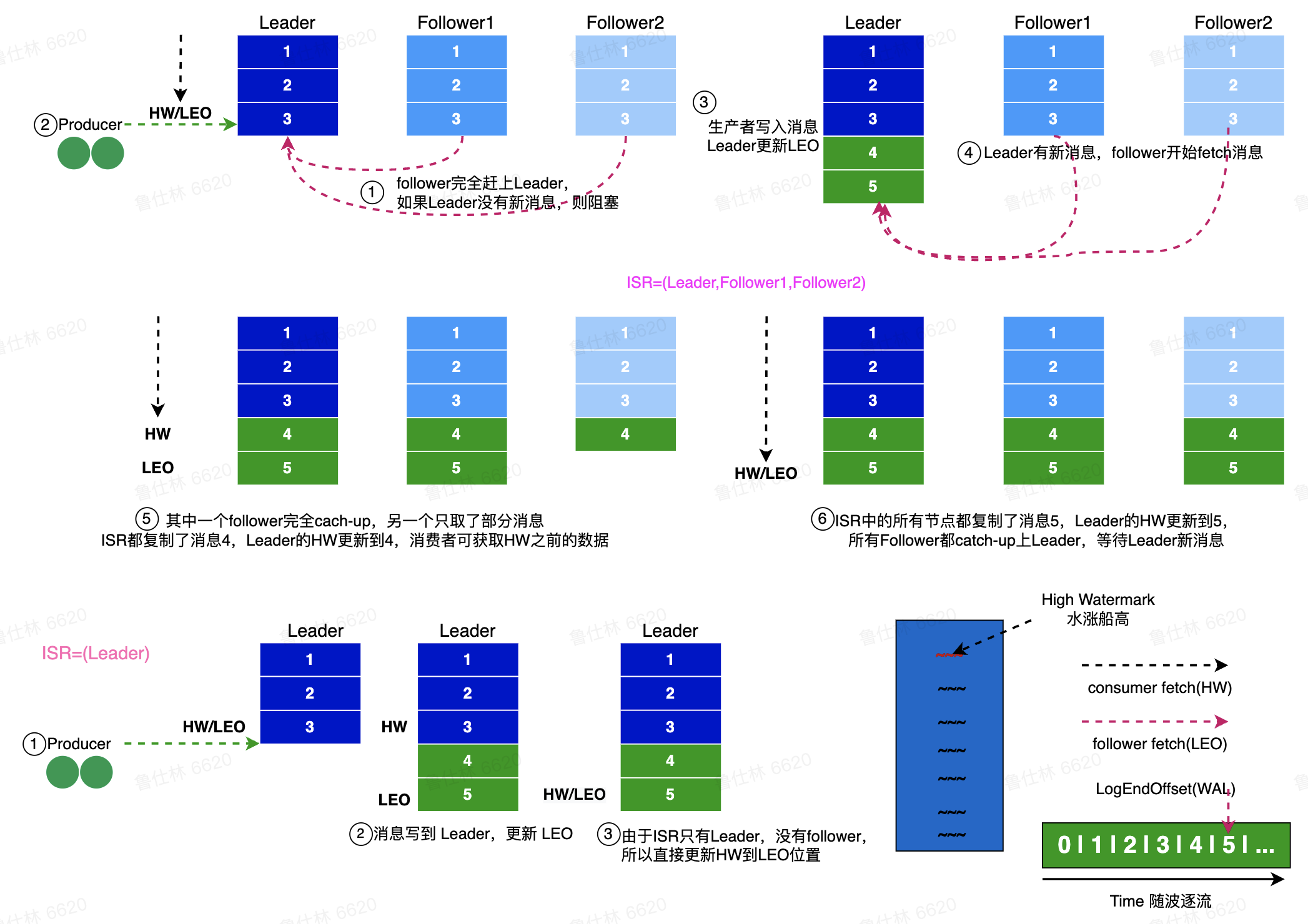
2.2 Kafka高可用
-
副本同步机制
-
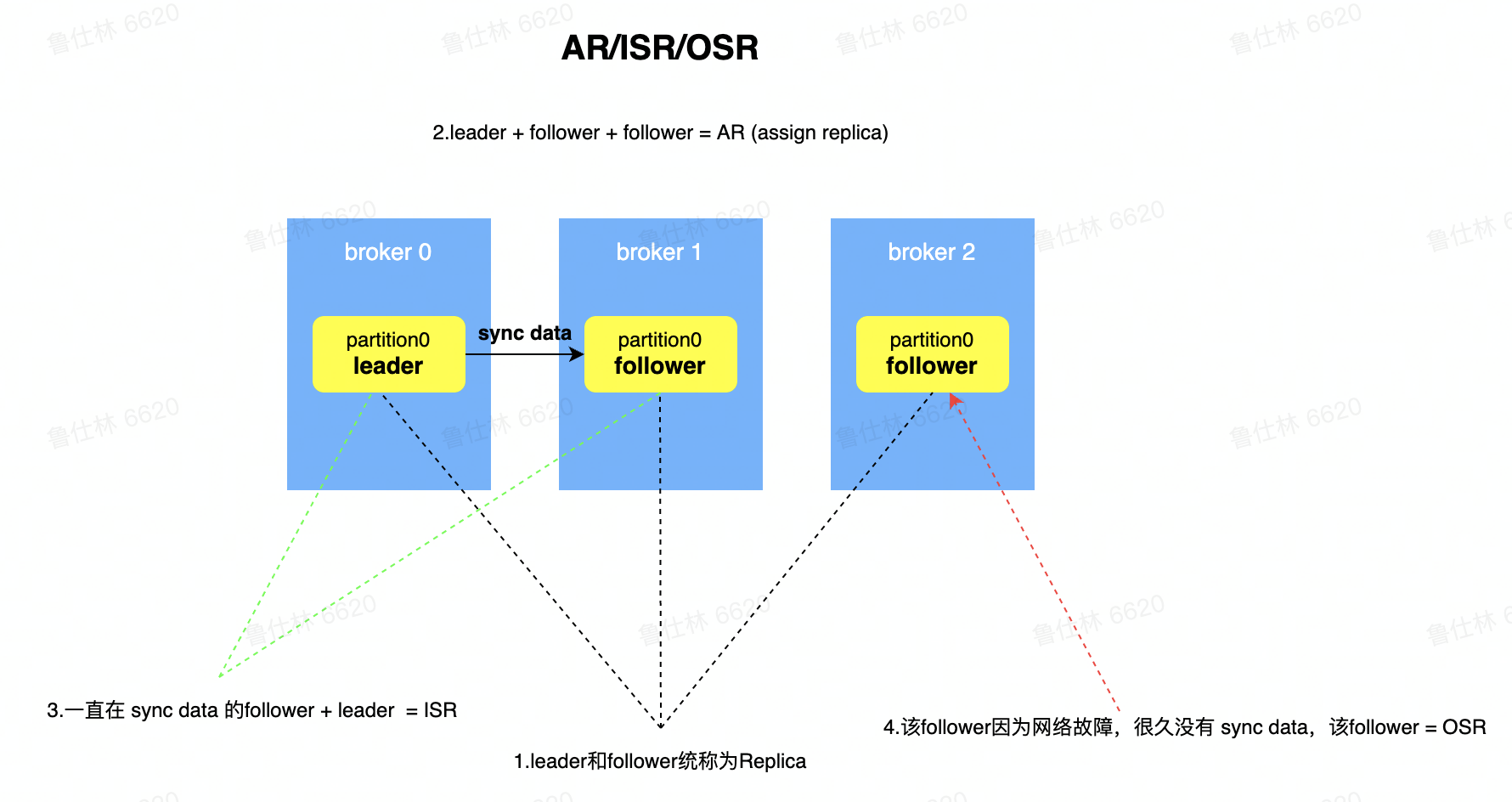
ISR副本复制机制,提供热备功能
- AR(Assign Replica),已经分配的所有副本
- OSR(Out Sync Replica),很久没同步数据的副本
- ISR(In Sync Replica),一直都在同步数据的副本,可以作为热备进行切换
- min.insync.replicas,最少ISR数量配置
-
-
写入端ACK机制,控制副本同步强弱
- ACK=1:Leader 副本写入成功,Producer 即认为写成功
- ACK=0:Producer 发送后即认为成功
- ACK=-1:ISR 中所有副本都成功,Producer 才认为写成功
-
副本切换机制
思考题:
问:3副本情况下,如何配置来保证写入 kafka 系统中的数据不丢失?5副本呢?
答:min.insync.replicas=2,ack=-1,5副本也一样
-
如何进行副本同步,两个数值来保证副本的一致性和可见性
- LEO(Log End Offset),日志最末尾的数据
- HW,ISR 中最小的 LEO,HW 的消息为 Consumer 可见的消息
如下图,下半部分是只有一个副本的情况,只有一个Leader,里面有 3 条数据,LEO 和 HW 都是 3。有新的4、5消息写进来后,LEO 更新为5,由于只有Leader这一个节点,所以HW也直接更新到LEO的位置。
图的上半部分是3副本的情况,