

在我之前的文章中,我展示了标记化、词根化和词组化是如何帮助提供我们人类所讲的自然语言的特征的。
但这并不是最好的方法。
还有两种方法在优化方面非常有用,使模型有效和准确。它们是
- 词包(Bag Of Words
- TF-IDF
词包(Bag Of Words
通俗地说,Bag Of Words将记录最常使用的词语的总出现次数。这些词将被视为特征,可以提供给一个算法。
它创建了一个文本中出现的所有单词的字典。
这就是我们拥有的文本。
Sentence 1: He is a good boy
这项任务将有两个步骤,即收集停顿词和降低句子的情况。因此,在执行该任务后,句子将像......
Sentence 1: good boy
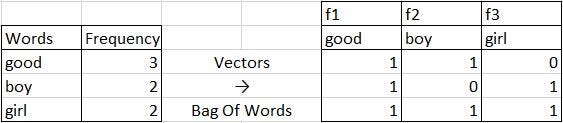
词语袋的实施。
这就是句子中的单词将被转换为向量,其中f1、f2和f3是独立的特征。
正如我们在之前的博客中所看到的,有特定的方法调用来执行干化和词法等任务。Bag Of Words的方法有点不同。
首先,为了从文本中获得独特的词,我们将进行词干化或词缀化,然后,我们将在此基础上实现一个词包。
Scikit Learn有一个叫做Count Vectorizer的类,它将使我们的工作更容易,叫做Count Vectorizer。
from sklearn.feature_extraction.text import CountVectorizer
这个Python代码将把句子转换为向量。这里的文本将以列表的形式出现在 "语料库 "变量中。
这种方法可用于情绪分析,我们只需预测该句子是否有积极情绪或消极情绪。
术语频率--逆向文档频率(TF-IDF)
术语频率-逆向文档频率(TF-IDF)是一种统计方法,它将对每个词在文档中进行排名。
这是通过两个指标相乘来实现的:一个词在文档中出现的次数,以及该词在一组文档中的反文档频率。
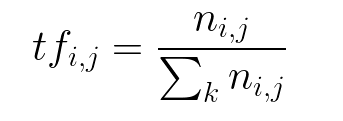
术语频率(TF)= 句子中的重复词数/句子中的词数
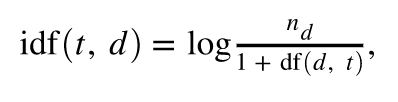
反文档频率(IDF)=对数(句子数量/包含单词的句子数量)

TF-IDF = tf * idf
这就是在数学上,单词将被赋予其在文档中出现的等级。
在我们的例子中,TF-IDF矢量化的实现将如下。

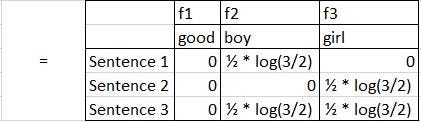
TF-IDF的实现
所有这些条件都将在引擎盖下完成,只需编写一个小代码,它将使用Scikit Learn的TF-IDF向量器。
from sklearn.feature_extraction.text import TfidfVectorizer
我们将创建一个TfidfVectorizer类的对象,该对象将被提供一个经过Lemmatized或Stemmed的句子语料库。
特别感谢Aayush Jain对本文的帮助。这里有一个NLP项目的链接,可以帮助你用现实生活中的数据进行尝试。
