

这是我参与「第四届青训营」笔记创作活动的的第13天
01.YARN概述
初识调度系统–场景导入
- 学校为改善学生生活新建了一所美食餐厅,餐厅座位有限且只能堂食;
- 各学院需缴纳一定管理费用后学生才能在该餐厅用餐,缴纳费用与分配的座位数成正比;
- 因餐厅物美价廉、环境干净,来该餐厅就餐的人络绎不绝;
如何进行高效座位分配在保障就餐公平性的前提下让尽可能多的学生都能够及时就餐、尽可能多的座位被有效使用?
一种简易分配模型
- 各个学院:获得座位数
- 学院学生:按照学院组织
- 餐厅经理:分配餐厅座位
- 餐厅座位:有序排列放置
优化的分配模型
-
保障公平性
- 学院间:低分配座位满足率优先
- 学院内:先来先服务
-
保障高效性
- 配备餐厅助手
- 用餐小组负责人
-
保障高可用
- 配置备用经理
-
如何满足“尽可能多”?
- 座位超售:分配座位大于总座位数
- 学院超用:学院可以超分配座位
- 座位超发:“—个座位坐两个人”
- 鼓励快餐:鼓励快速就餐离开
-
如何满足就餐学生个性化需求?
- 用餐小组必须坐一个桌子
- 用餐小组必须坐不同桌子
- 用餐小组必须靠窗位置坐
- 有重要活动同学需靠前就餐
调度系统演进
调度系统发展的背景
- IT到DT时代的变革,注重数据价值;
- 数据计算方式的变革,注重计算效率;
- 企业对外服务需数以万计的硬件资源;
- 灵活调度、提高利用率是降本增效的关键问题;
调度系统演进
调度系统解决的问题
- 用有限资源解决有限资源无法满足的需求时就需要调度;
- 调度系统主要解决资源请求和可用资源间的映射(Mapping)问题;
调度系统预达的目标
- 严格的多租户间公平、容量保障
- 调度过程的高吞吐与低延迟
- 高可靠性与高可用性保障
- 高可扩展的调度策略
- 高集群整体物理利用率
- 满足上层任务的个性化调度需求
- 任务持续、高效、稳定运行
调度系统范型
-
集中式
- 融合资源管理调度和任务控制;
-
两层式
- 资源管理调度和任务控制解耦;
-
共享状态式
- 多个调度茄最于乐观并发共享全局资源视图;
-
分布式
- 多个调度茄基于先验知识进行最快调度决策;
-
混合式
- 多种类型调度器共存,共同分配;
YARN设计思想
演化背景
-
Hadoop 1.0时代:
- 可扩展性差
- 可靠性差
- 资源利用率低
- 无法支持多种计算框架
-
Hadoop 2.0时代:
- 资源管理和任务控制解耦
- YARN(Yet Another Resource Negotiator)支持多种计算框架的统一资源管理
离线生态
面临挑战
- 公平性:各租户能够公平的拿到资源运行任务
- 高性能:高调度吞吐、低调度延迟,保障资源快速流转
- 高可用:集群要具备很强的容错能力
- 大规模:单集群规模提升(原生YARN 5K)
- 高集群资源利用率
- 高任务运行质量保障
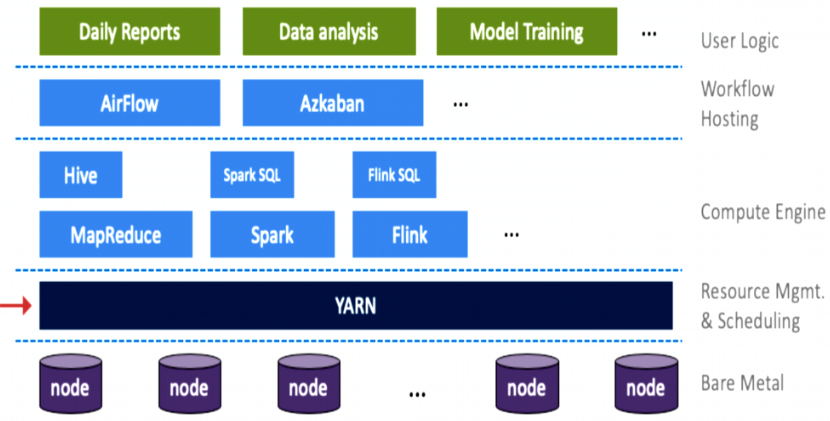
YARN整体架构
系统架构
-
Resource Manager
- 资源管理和调度
- 任务生命周期管理
- 对外进行交互
-
Node Manager
- 提供集群资源
- 管理Container运行
任务运行生命周期核心流程
02.核心模块
Resource Manager
整体架构
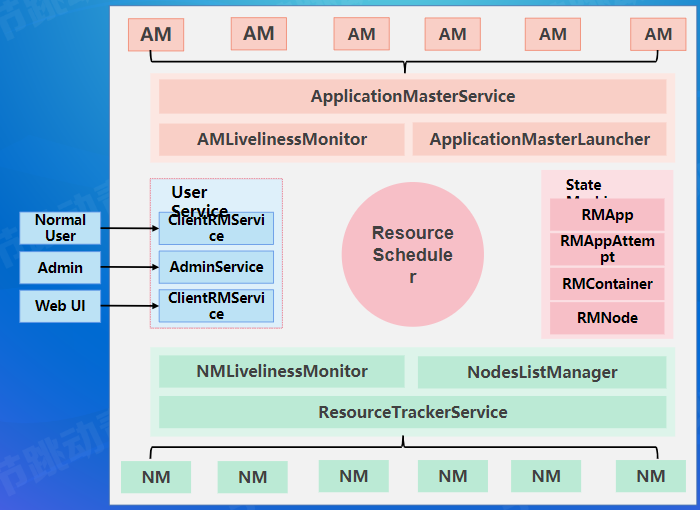
主要职责
RM负责集群所有资源的统一管理和分配,接收各节点汇报信息并按照一定策略分配给各个任务。
-
与客户端交互
-
启动和管理所有AM
-
管理所有NM
-
资源管理与调度
- 组织资源(资源池)
- 组织任务(队列)
- 接收资源请求
- 分配资源
状态机管理
RMApp状态机
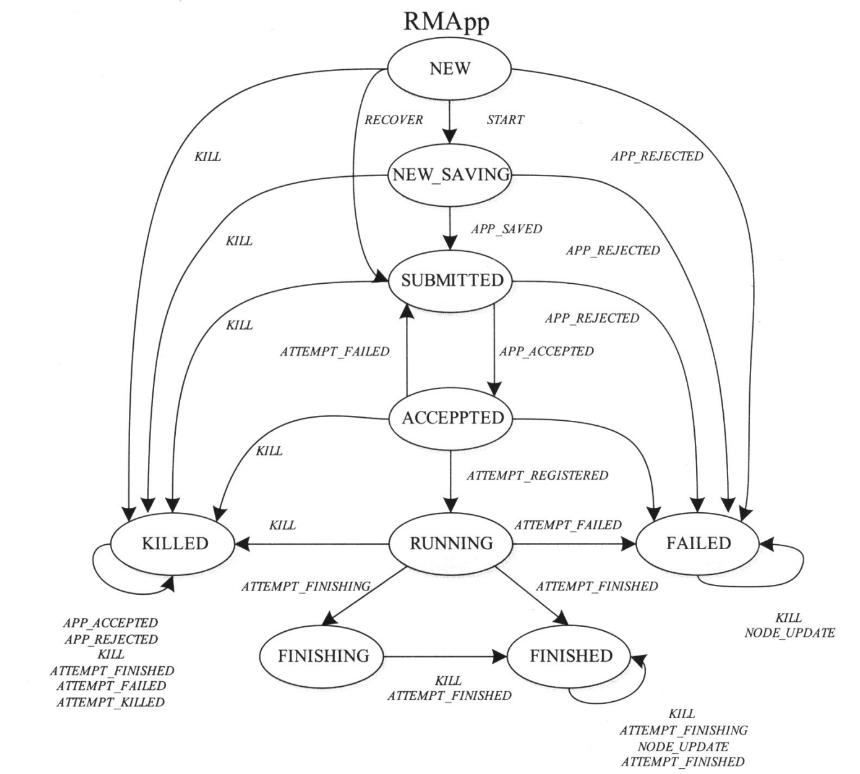
- NEW_SAVING:收到任务后,创建RMApplmpl对象并将基本信息持久化;
- ACCEPTED:调度器接受该任务后所处的状态,任务等待被分配资源;
- RUNNING:任务成功获取到资源并在节点运行;
RMAppAttempt
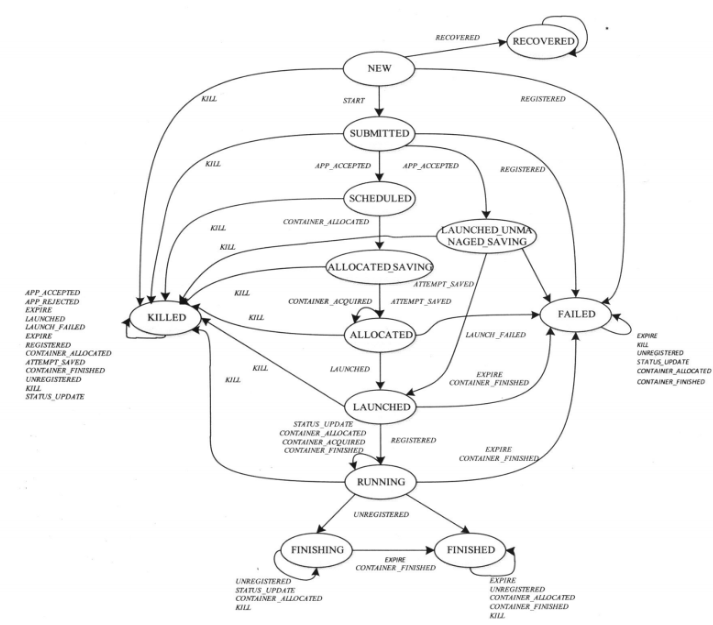
- SCHEDULED:通过合法性检查后所处的状态,开始为该任务分配资源;
- ALLOCATED_SAVING:收到分配的Container后,在持久化完成前所处的状态;
- ALLOCATED:信息持久化完成后所处的状态;LAUNCHED: RM的
- ApplicationMasterLauncher 与 NM通信以启动AM时所处的状态;
RMContainer
- RESERVED:开启资源预留时,当前节点不能满足资源请求时所处的状态;
- ALLOCATED:调度器分配一个 Container 给AM;
- ACQUIRED: Container被AM 领走后的状态;
- EXPIRED: AM获取到Container后,若在—定时间内未启动Container,RM会强制回收该Container;
RMNode
- DECOMMISSIONED:节点下线后的状态;
- UNHEALTHY:节点处于不健康状态,健康检测脚本异常或磁盘故障;
- LOST:节点超过一定时间(默认10分钟)未与RM发生心跳后所处的状态;
调度器分析
任务/资源组织
- 任务按队列组织
- 节点按Label组织
调度流程
- AM与RM心跳:记录资源请求
- 触发时机:节点心跳
- 找Label:获取所有队列
- 找队列:最“饥饿”队列优先
- 找任务:优先级高的任务优先
- 找资源请求:优先级高的请求优先
典型调度器
Node Manager
整体架构
主要职责
NM是节点代理,从AM接受命令(启停Container)并执行,通过心跳方式向RM汇报节点状态并领取命令(清理Container)。
-
与RM交互
- 心跳汇报节点状态
- 领取 RM下达的命令
-
与AM交互
- 启动容器
- 停止容器
- 获取容器状态
状态机管理
Application
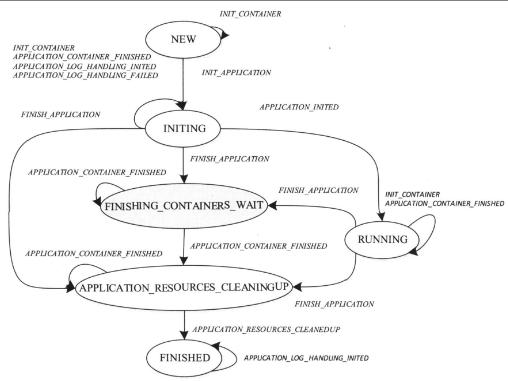
- INITING: Application初始化状态,创建工作目录和日志目录;
- FINISHING_CONTAINERS_WAIT:调等待回收Container所占用的资源所处的状态;
- APPLICATION_RESOURCE_CLEANINGUP:Application所有Container占用的资源被回收后所处的状态;
Container
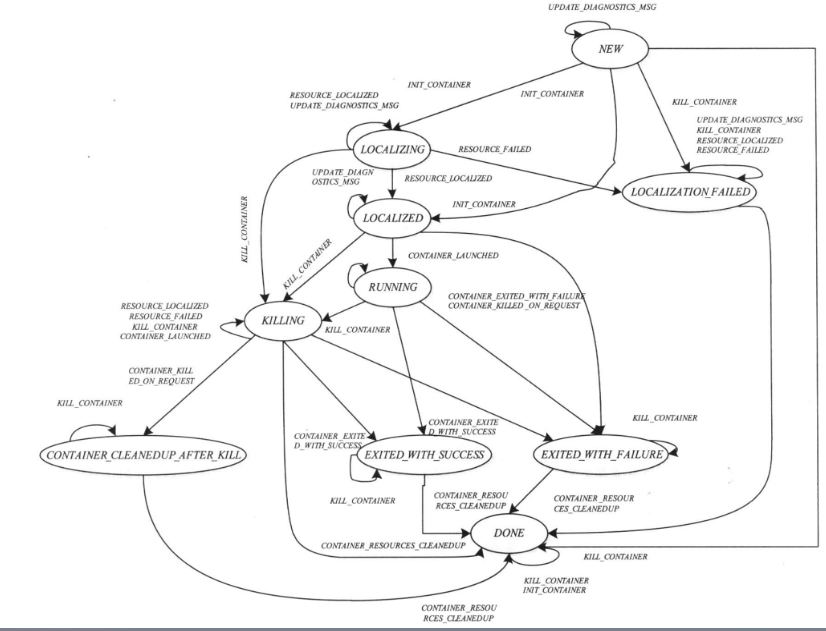
- LOCALIZING:正在从 HDFS下载依赖的资源;
- EXITED_WITH_SUCCESS: Container运行脚本正常退出执行;
- CONTAINER_CLEANUP_AFTER_KILL:Container 被kill后所处的状态
LocalizedResource
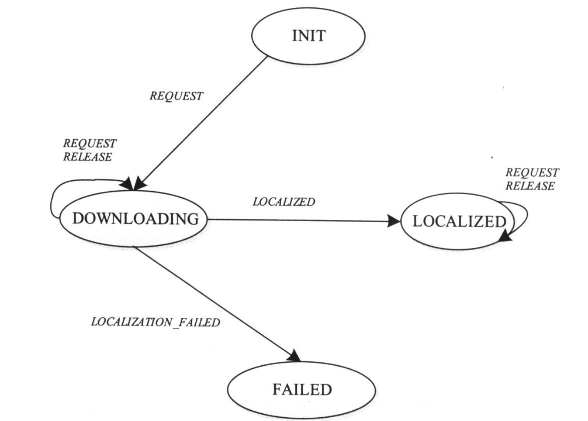
- DOWNLOADING:资源处于下载状态;
- LOCALIZED:资源下载完成;
- FAILED:资源下载失败;
节点健康检测机制
-
节点健康检测机制可时刻掌握NM健康状况并及时汇报给RM,RM根据NM是否健康决定是否为其调度新任务。
-
自定义Shell
- NodeHealthScriptRunner服务周期性执行节点健康状况检测脚本;
- 若输出以“ERROR”开头则不健康;
-
检测磁盘损坏数目
- 判断磁盘损坏标准:若一个目录具有读、写和执行权限,则目录正常;
- LocalDirsHandlerService服务周期性检测NM本地磁盘好坏,坏盘数超过阈值则不健康;
03.重要机制
公平性保障——调度策略
-
为什么需要Fair Share调度策略?
- 实现队列间资源共享,提高资源利用率;
- 缓解繁忙队列压力;
-
什么是Fair Share调度策略?
- 队列空闲时按照一定策略将资源分配给其他活跃队列;
-
Fair Share类型
- Steady Fair Share
- Instantaneous Fair Share
Instantaneous Fair Share定义
Instantaneous Fair Share计算
-
定义
- 所有队列 Fair Share之和<= TotalResource;
- S.minShare <= Fair Share <= S.maxShare;
-
目标
- 找到一个R使其满足:
- R*(All S.wieght)<= TotalResource;
- S.minShare <= R * S.weight <= S.maxShare;
-
结果
- 若S.minShare > R * S.weight, Fair Share = S.minShare
- 若S.maxShare < R * S.weight,Fair Share = S.maxShare
- 其他 Fair Share = R * S.weight
Instantaneous Fair Share计算逻辑
计算Total Resource
-
初始化R上限 RMax
- 获取所有non-fixed Schedulable的maxShare
- 初始化R为1,每次翻倍
- 直到所有Schedulable分完所有资源
-
通过二分法寻找R[O,RMax]
- mid = (left + right)/ 2.0
- 若 plannedResourceUsed == totalResource,right = mid;
- 若plannedResourceUsed < totalResource,left = mid;
- 若 plannedResourceUsed > totalResource,right = mid;
-
计算Fair Share
- 若S.minShare > right * S.weight, Fair Share = S.minShare;
- 若S.maxShare < right * S.weight, Fair Share = S.maxShare;
- 其他情况Fair Share = right * S.weight
DRF(Dominant Resource Fair)调度策略
-
为什么需要DRF调度策略?
- 在保证公平性的前提下进行资源降维;
-
什么是 DRF 调度策略?
- DRF是最大最小公平算法在多维资源上的具体实现;
- 旨在使不同用户的“主分享量”最大化的保持公平;最大最小公平算法:
-
最大化最小资源需求的满足度
- 资源按照需求递增顺序分配;
- 获取的资源不超过自身需求;
- 未满足用户等价分享剩余资源;
DRF调度策略描述
DRF调度策略示例
-
场景:系统有<9CPU,18G>,A每个任务需要<1CPU,4G>,B每个任务需要<3CPU,1G>,对于A因为:1/9<4/18,所以A任务的主资源是内存,B任务的主资源是CPU;
-
数学模型:一定约束条件下的最优化问题,下面x代表A任务的个数, y代表B任务的个数
-
最大化资源分配max(x,y)
-
约束条件:
- (x+3y)<=9(CPU约刺);
- (4x+y)<= 18(内存约束);
- 4x/18 == 3y/9(主资源公平约束);
-
-
-
最终计算得到:x=3, y=2
DRF调度策略计算逻辑

- R表示总资源量,有m个维度
- C已经使用的资源量
- si 用户i的“主分享量”
- Ui分配给用户i的资源量
-
选择最小“主分享量”用户i
-
Di用户i下一个任务资源需求量
-
若资源充足
- 更新已使用资源量
- 更新用户i的已分配资源量
- 更新用户i的“主分享量”
高性能保障——事件机制
状态机管理
- 状态机由一组状态(初始状态、中间状态和最终状态)组成,状态机从初始状态开始运行,接收一组特定事件,经过一系列中间状态后,到达最终状态并退出;
- 每种状态转换由一个四元组表示:转换前状态、转换后状态、事件和回调函数;
- YARN定义了三种状态转换方式如下所示:
事件处理模型
- 所有处理请求都会作为事件进入系统;
- AsyncDispatcher负责传递事件给相应事件调度器;
- 事件调度器将事件转发给另一个事件调度器或带有有限状态机的事件处理器;
- 处理结果以事件形式输出,新事件会再次被转发,直至处理完成;
- YARN 采用了基于事件驱动的并发模型,具有很强的并发性可提高系统性能。
高可用保障——容错机制
高可用性
RM高可用
-
热备方案:Active Master提供服务、Standby Master 作为备节点;
-
基于共享存储的HA解决方案:关键信息写入共享存储系统(ZK) ;
-
两种切换模式:
-
手动模式:“yarn rmadmin”命令手动操作;
-
自动模式:ZK的ActiveStandbyElector进行选主操作,ZK中有一个锁节点,所有RM竞争写一个
- 子节点,ZK保证最终只有一个RM能够创建成功,创建成功的为Active Master;
-
-
Client、AM、NM自动重试:切主时各组件采用round-robin方式尝试连接RM;
NM高可用
- 关键信息存储至leveldb数据库;
- 重启时从yarn-nm-recovery 下的 leveldb 数据库加载数据;
04.公司实践
Gang调度器
为什么需要开发Gang调度器?
流式作业和训练作业的调度需求与批处理有很大的不同:批处理强调高吞吐,而流式训练类型作业更强调低延迟和全局视角;
- 调度缺乏全局视角
- 单App调度过慢
- App间存在资源互锁
Gang调度器有什么典型特点?
-
全局视角
- 作业可自定义配置强弱约束;
- 强约束:必须要满足的条件,
- 弱约束:尽量满足的约束,;
-
低调度延迟
- RM维护所有节点状态信息;
- 资源请求同步分配,毫秒级返回;
-
Gang性资源交付
- 提供 All-or-Nothing语义;
- 可满足的请求全部分配,否则返回失败;
Gang调度器调度流程
-
强约束段:过滤掉不符合条件的节点
-
弱约束阶段:选择合适的节点分配资源(不排序,时间复杂度O(n))
-
Quota 平均:分配后节点已使用资源尽可能平均
- 总请求资源为V1,总节点数为N,已用资源为U,节点目标资源为:S=(V1+ U)/N,遍历所有节点,每个节点分配S - Un即可;
-
跳过高load节点:优先往低 load节点调度
- 满足load阈值节点N1,不满足N2,优先把N1剩余资源分配完,分配后未满足资源量为V2,每个节点分配V2/N2;
-
-
兜底分配
反调度器
为什么需要开发反调度器?
-
调度器的调度决策受“时空”限制
- “时”:触发调度时刻;
- “空”:触发调度时集群状态;
-
任务运行和集群状态高动态性
- 任务资源使用随流量变化而不断波动;
- 调度过程持续进行,集群状态持续变化;
-
需要持续保证最初调度决策的正确性
反调度流程
- 根据AM请求中的强约束,构造强约束集;
- 遍历强约束集选择不再符合强约束条件的节点;√遍历异常节点下的Container,选择需要进行反调度的Container;
- 将反调度Container列表随心跳返回给AM;
单集群规模突破50K
为什么需要提升单集群规模?
-
更好的资源池化和资源共享
- 资源池更大,利于资源分时复用;
- 资源高效共享,提高集群资源利用率;
-
降低运维成本
- YARN原生单集群仅支持5K节点;
- 每多一个集群,运维负担就会加重;
RPC瓶颈
-
RPC层:接收请求、处理请求、返回结果
- RPC处理时间5ms,handler默认80线程;
- 消费吞吐瓶颈约16K/s,RPC Server Queue易打满;
Dispatcher 瓶颈
-
Dispatcher层:将事件传递给对应的事件调度器
- 生产速率过大,AsyncDispatcher Queue容易Pending
- 消费速率过低,NODE_UPDATE事件处理过慢,2K/s瓶颈
Scheduler瓶颈
-
Scheduler层:真正调度
- FSLeafQueue 单Container 分配延迟高,存在空转
心跳反压机制
心跳动态调整:将NM节点心跳周期改为根据RM的压力动态调整
多线程调度
多线程调度:对节点按hashcode放到对应的Scheduler Queue
其他优化
- 事件精简:对内部事件梳理调整,精准修改了一些事件处理逻辑
- 空转优化:调度时过滤不需要资源的App,减少空转
- 内存单位优化:修改内存单位(int -> long)突破单集群21亿 MB限制
- 切主优化:通过对切主过程深度优化,将切主时间控制在秒级
