

用Apache Kafka轻松实现从Oracle到MongoDB的数据移动
在数据库领域,变化数据捕获功能已经存在了很多年。CDC使得监听数据库的变化成为可能,如插入、更新和删除数据,并在ETL、复制和数据库迁移等各种情况下将这些事件发送到其他数据库系统。通过利用Apache Kafka、Confluent Oracle CDC Connector和MongoDB Connector for Apache Kafka,你可以轻松地将数据库变化从Oracle流转到MongoDB。在这篇文章中,我们将把数据从Oracle传到MongoDB,为你提供一步一步的配置,以方便你重新使用、调整和探索功能。
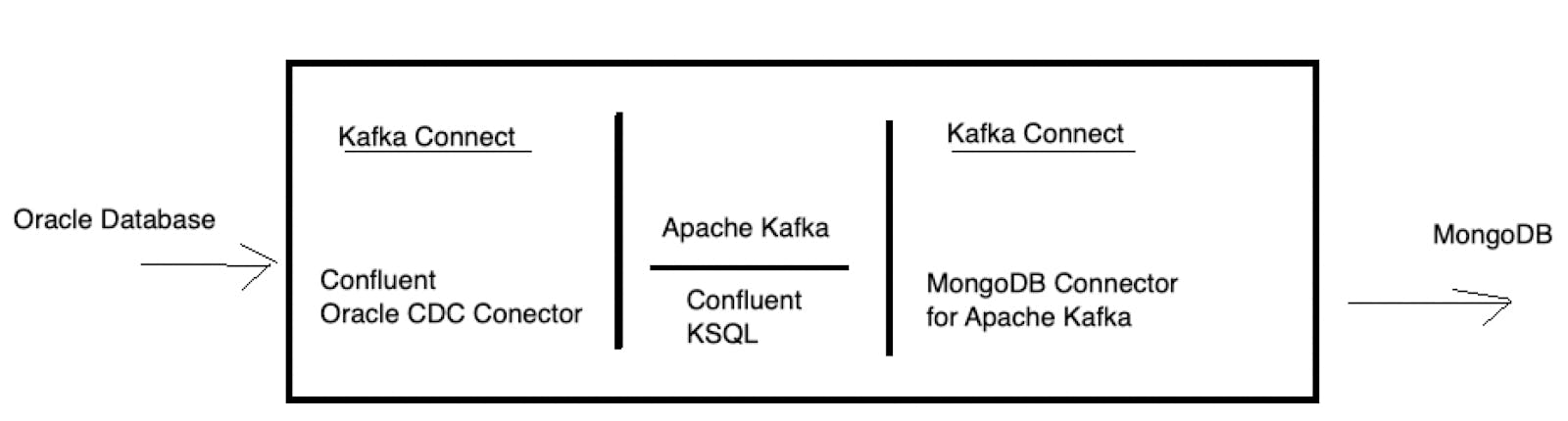
在高层次上,我们将在一个独立的docker compose环境中配置上述参考图像,该环境由以下部分组成:
- Oracle数据库
- MongoDB
- Apache Kafka
- Confluent KSQL
这些容器将全部在本地网络桥接中运行,因此你可以在本地的Mac或PC上玩弄它们。请查看GitHub资源库,下载完整的例子。
准备Oracle Docker镜像
如果你有一个现有的Oracle数据库,从docker-compose文件中删除 "数据库 "部分。如果你还没有一个Oracle数据库,你可以从Docker Hub拉出Oracle数据库企业版。你需要接受Oracle的条款和条件,然后通过docker login ,然后docker pull store/oracle/database-enterprise:12.2.0.1-slim ,登录到你的docker账户,在本地下载镜像。
启动docker环境
docker-compose文件将启动以下内容:
- Apache Kafka,包括Zookeeper、REST API、模式注册表、KSQL
- Apache Kafka连接
- Apache Kafka的MongoDB连接器
- Confluent Oracle CDC连接器
- 甲骨文数据库企业
完整的示例代码可以从GitHub仓库中获得。
要启动该环境,请确保你的Oracle环境已经准备好了,然后git克隆该repo并构建以下内容:
docker-compose up -d --build
一旦编译文件完成,你将需要配置你的Oracle环境,以便被Confluent CDC Connector使用。
第1步:连接到你的Oracle实例
如果你在docker环境中运行Oracle,你可以使用docker exec,如下所示:
docker exec -it oracle bash -c "source /home/oracle/.bashrc; sqlplus /nolog "
connect / as sysdba
第2步:为CDC连接器配置Oracle
首先,检查数据库是否处于存档日志模式:
select log_mode from v$database;
如果模式不是 "ARCHIVELOG",请执行以下操作:
SHUTDOWN IMMEDIATE;
STARTUP MOUNT;
ALTER DATABASE ARCHIVELOG;
ALTER DATABASE OPEN;
验证归档模式:
select log_mode from v$database
LOG_MODE现在应该是,"ARCHIVELOG"。
接下来,为所有的列启用补充日志记录
ALTER SESSION SET CONTAINER=cdb$root;
ALTER DATABASE ADD SUPPLEMENTAL LOG DATA (ALL) COLUMNS;
下面应该在Oracle CDB上运行:
CREATE ROLE C##CDC_PRIVS;
GRANT CREATE SESSION,
EXECUTE_CATALOG_ROLE,
SELECT ANY TRANSACTION,
SELECT ANY DICTIONARY TO C##CDC_PRIVS;
GRANT SELECT ON SYSTEM.LOGMNR_COL$ TO C##CDC_PRIVS;
GRANT SELECT ON SYSTEM.LOGMNR_OBJ$ TO C##CDC_PRIVS;
GRANT SELECT ON SYSTEM.LOGMNR_USER$ TO C##CDC_PRIVS;
GRANT SELECT ON SYSTEM.LOGMNR_UID$ TO C##CDC_PRIVS;
CREATE USER C##myuser IDENTIFIED BY password CONTAINER=ALL;
GRANT C##CDC_PRIVS TO C##myuser CONTAINER=ALL;
ALTER USER C##myuser QUOTA UNLIMITED ON sysaux;
ALTER USER C##myuser SET CONTAINER_DATA = (CDB$ROOT, ORCLPDB1) CONTAINER=CURRENT;
ALTER SESSION SET CONTAINER=CDB$ROOT;
GRANT CREATE SESSION, ALTER SESSION, SET CONTAINER, LOGMINING, EXECUTE_CATALOG_ROLE TO C##myuser CONTAINER=ALL;
GRANT SELECT ON GV_$DATABASE TO C##myuser CONTAINER=ALL;
GRANT SELECT ON V_$LOGMNR_CONTENTS TO C##myuser CONTAINER=ALL;
GRANT SELECT ON GV_$ARCHIVED_LOG TO C##myuser CONTAINER=ALL;
GRANT CONNECT TO C##myuser CONTAINER=ALL;
GRANT CREATE TABLE TO C##myuser CONTAINER=ALL;
GRANT CREATE SEQUENCE TO C##myuser CONTAINER=ALL;
GRANT CREATE TRIGGER TO C##myuser CONTAINER=ALL;
ALTER SESSION SET CONTAINER=cdb$root;
ALTER DATABASE ADD SUPPLEMENTAL LOG DATA (ALL) COLUMNS;
GRANT FLASHBACK ANY TABLE TO C##myuser;
GRANT FLASHBACK ANY TABLE TO C##myuser container=all;
接下来,创建一些对象
CREATE TABLE C##MYUSER.emp
(
i INTEGER GENERATED BY DEFAULT AS IDENTITY,
name VARCHAR2(100),
lastname VARCHAR2(100),
PRIMARY KEY (i)
) tablespace sysaux;
insert into C##MYUSER.emp (name, lastname) values ('Bob', 'Perez');
insert into C##MYUSER.emp (name, lastname) values ('Jane','Revuelta');
insert into C##MYUSER.emp (name, lastname) values ('Mary','Kristmas');
insert into C##MYUSER.emp (name, lastname) values ('Alice','Cambio');
commit;
第3步:创建Kafka主题
打开一个新的终端/shell,按如下方式连接到你的kafka服务器:
docker exec -it broker /bin/bash
当连接后,创建Kafka主题:
kafka-topics --create --topic SimpleOracleCDC-ORCLCDB-redo-log \
--bootstrap-server broker:9092 --replication-factor 1 \
--partitions 1 --config cleanup.policy=delete \
--config retention.ms=120960000
第4步:配置Oracle CDC连接器
资源库中的oracle-cdc-source.json文件包含Confluent Oracle CDC连接器的配置。要配置只需执行:
curl -X POST -H "Content-Type: application/json" -d @oracle-cdc-source.json http://localhost:8083/connectors
第5步:在Kafka中设置kSQL数据流
当Oracle CRUD事件到达Kafka主题时,我们将使用KSQL将这些事件流到一个新的主题中,供Apache Kafka的MongoDB连接器使用:
docker exec -it ksql-server bin/bash
ksql http://127.0.0.1:8088
输入以下命令:
CREATE STREAM CDCORACLE (I DECIMAL(20,0), NAME varchar, LASTNAME varchar, op_type VARCHAR) WITH ( kafka_topic='ORCLCDB-EMP', PARTITIONS=1, REPLICAS=1, value_format='AVRO');
CREATE STREAM WRITEOP AS
SELECT CAST(I AS BIGINT) as "_id", NAME , LASTNAME , OP_TYPE from CDCORACLE WHERE OP_TYPE!='D' EMIT CHANGES;
CREATE STREAM DELETEOP AS
SELECT CAST(I AS BIGINT) as "_id", NAME , LASTNAME , OP_TYPE from CDCORACLE WHERE OP_TYPE='D' EMIT CHANGES;
为了验证流的创建。
SHOW STREAMS。
这个命令将显示如下:
Stream Name | Kafka Topic | Format
------------------------------------
CDCORACLE | ORCLCDB-EMP | AVRO
DELETEOP | DELETEOP | AVRO
WRITEOP | WRITEOP | AVRO
------------------------------------
第6步:配置MongoDB Sink
下面是Apache Kafka的MongoDB连接器的配置:
{
"name": "Oracle",
"config": {
"connector.class": "com.mongodb.kafka.connect.MongoSinkConnector",
"topics": "WRITEOP",
"connection.uri": "mongodb://mongo1",
"writemodel.strategy": "com.mongodb.kafka.connect.sink.writemodel.strategy.UpdateOneBusinessKeyTimestampStrategy",
"database": "kafka",
"collection": "oracle",
"document.id.strategy": "com.mongodb.kafka.connect.sink.processor.id.strategy.PartialValueStrategy",
"document.id.strategy.overwrite.existing": "true",
"document.id.strategy.partial.value.projection.type": "allowlist",
"document.id.strategy.partial.value.projection.list": "_id",
"errors.log.include.messages": true,
"errors.deadletterqueue.context.headers.enable": true,
"value.converter":"io.confluent.connect.avro.AvroConverter",
"value.converter.schema.registry.url":"http://schema-registry:8081",
"key.converter":"org.apache.kafka.connect.storage.StringConverter"
}
}
在这个例子中,这个水槽进程从WRITEOP主题消耗记录,并将数据保存到MongoDB。写入模型,UpdateOneBusinessKeyTimestampStrategy,使用定义在PartialValueStrategy属性上的过滤器执行上移操作,在这个例子中,这个属性是"_id "字段。为了方便你,这个配置脚本写在资源库中的mongodb-sink.json文件中。要配置执行:
curl -X POST -H "Content-Type: application/json" -d @mongodb-sink.json http://localhost:8083/connectors
删除事件被写在DELETEOP主题中,并通过以下水槽配置被汇入MongoDB:
{
"name": "Oracle-Delete",
"config": {
"connector.class": "com.mongodb.kafka.connect.MongoSinkConnector",
"topics": "DELETEOP",
"connection.uri": "mongodb://mongo1”,
"writemodel.strategy": "com.mongodb.kafka.connect.sink.writemodel.strategy.DeleteOneBusinessKeyStrategy",
"database": "kafka",
"collection": "oracle",
"document.id.strategy": "com.mongodb.kafka.connect.sink.processor.id.strategy.PartialValueStrategy",
"document.id.strategy.overwrite.existing": "true",
"document.id.strategy.partial.value.projection.type": "allowlist",
"document.id.strategy.partial.value.projection.list": "_id",
"errors.log.include.messages": true,
"errors.deadletterqueue.context.headers.enable": true,
"value.converter":"io.confluent.connect.avro.AvroConverter",
"value.converter.schema.registry.url":"http://schema-registry:8081"
}
}
curl -X POST -H "Content-Type: application/json" -d @mongodb-sink-delete.json http://localhost:8083/connectors
这个水槽流程使用DeleteOneBusinessKeyStrategy的写入策略。在这种配置中,水槽从DELETEOP主题中读取,并根据PartialValueStrategy属性上定义的过滤器删除MongoDB中的文档。在这个例子中,该过滤器是"_id "字段。
第7步:向Oracle写入数据
现在你的环境已经设置和配置好了,返回到Oracle数据库并插入以下数据:
insert into C##MYUSER.emp (name, lastname) values ('Juan','Soto');
insert into C##MYUSER.emp (name, lastname) values ('Robert','Walters');
insert into C##MYUSER.emp (name, lastname) values ('Ruben','Trigo');
commit;
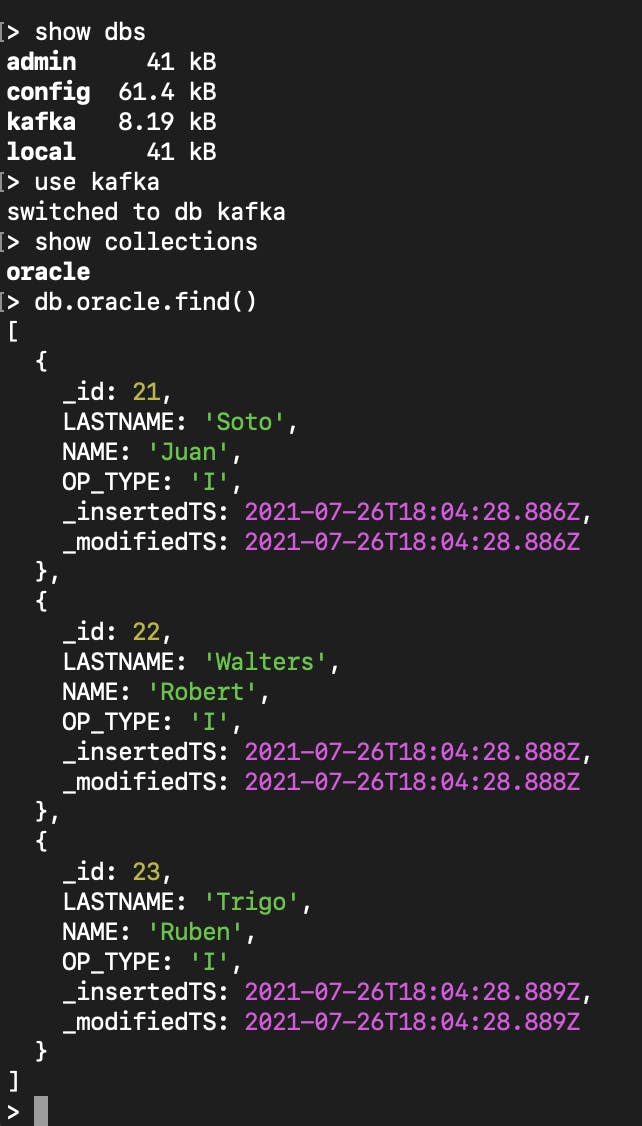
接下来,通过访问MongoDB的shell来注意数据到达MongoDB的情况:
docker exec -it mongo1 /bin/mongo
插入的数据现在将在MongoDB中可用:
如果我们更新Oracle中的数据,例如
UPDATE C##MYUSER.emp SET name=’Rob’ WHERE name=’Robert’;
COMMIT;\
该文件将在MongoDB中被更新为。
{
"_id" : NumberLong(11),
"LASTNAME" : "Walters",
"NAME" : "Rob",
"OP_TYPE" : "U",
"_insertedTS" : ISODate("2021-07-27T10:25:08.867Z"),
"_modifiedTS" : ISODate("2021-07-27T10:25:08.867Z")
}
如果我们删除Oracle中的数据,例如
DELETE FROM C##MYUSER.emp WHERE name=’Rob’; COMMIT;.
带有name='Rob'的文档将不再出现在MongoDB中。
注意,从Oracle到MongoDB的传播可能需要几秒钟。
许多可能性
在这篇文章中,我们通过Apache Kafka和Confluent Oracle CDC Connector和MongoDB Connector for Apache Kafka进行了一个将数据从Oracle转移到MongoDB的基本设置。虽然这个例子相当简单,但你可以使用KSQL添加更复杂的转换,并在你的Kafka环境中集成其他数据源,使生产准备ETL或流媒体环境与最佳解决方案。
