

广义上讲,数据整理是重塑、聚合、分离或以其他方式将你的数据从一种格式转换为更有用的格式的过程。
例如,假设我们想对一个非常初级的动量交易策略进行逐步分析,其内容如下。
- 在每个月的开始,我们买入在过去7天、14天、21天或28天内价格涨幅最大的加密货币。我们要评估这些时间窗口中的每一个。
- 然后,我们正好持有7天,然后卖出我们的头寸。请注意:这是个特意设计的简单策略,只为说明问题。
我们会怎样去评估这个策略呢?
这是一个展示数据处理技术的好问题,因为所有的艰苦工作都在于把你的数据集塑造成适当的格式。一旦你有了适当的分析基础表(ABT),回答这个问题就变得简单了。
本指南不是什么。
这不是一份关于投资或交易策略的指南,也不是对加密货币的认可或反对。潜在的投资者应该独立形成自己的观点,但本指南将介绍这样做的工具。
同样,本教程的重点是数据处理技术和将原始数据集转化为帮助你回答有趣问题的格式的能力。
在我们开始之前,有一个简短的提示。
本教程的设计是精简的,它不会涉及任何一个主题的太多细节。在你身边打开Pandas库文档作为补充参考可能会有所帮助。
Python数据处理教程内容
下面是我们分析的步骤。
步骤1:设置你的环境。
首先,确保你的电脑上安装了以下东西。
- Python 2.7+或Python 3
- Pandas
- Jupyter笔记本(可选,但建议安装)
我们强烈建议安装Anaconda发行版,它带有所有这些软件包。只需按照该下载页面上的说明即可。
一旦你安装了Anaconda,只需启动Jupyter(通过命令行或Navigator应用)并打开一个新的笔记本。
Python 3或Python 2.7以上都可以。
第二步:导入库和数据集。
让我们从导入Pandas开始,这是处理关系型(即表格式)数据集的最佳Python库。Pandas将为本教程做大部分的重活。
-
提示:我们将给Pandas一个别名。以后,我们可以用
pd来调用这个库。
# Pandas for managing datasets
import pandas as pd
接下来,让我们对显示选项进行一些调整。首先,让我们显示小数点后2位的浮点数,使表格不那么拥挤。不要担心,这只是一个显示设置,并没有降低基础精度。让我们也扩大一下显示的行和列的数量限制。
# Display floats with 2 decimal places
pd.options.display.float_format = '{:,.2f}'.format
# Expand display limits
pd.options.display.max_rows = 200
pd.options.display.max_columns = 100
在本教程中,我们将使用由Brave New Coin管理并在Quandl上发布的价格数据集。完整版追踪1900多个法币-加密货币交易对的价格指数,但它需要高级订阅,所以我们提供了一个有少数加密货币的小样本。
要跟上进度,你可以下载BNC2_sample.csv。点击该链接将带你到谷歌硬盘,然后直接点击右上方的下载图标。
一旦你下载了数据集,并放在与你的Jupyter笔记本相同的文件目录下,你就可以运行下面的代码,将数据集读入Pandas数据框架,并显示示例观测值。
# Read BNC2 sample dataset
df = pd.read_csv('BNC2_sample.csv',
names=['Code', 'Date', 'Open', 'High', 'Low',
'Close', 'Volume', 'VWAP', 'TWAP'])
# Display first 5 observations
df.head()

请注意,我们使用
names=
参数为
pd.read_csv()
以设置我们自己的列名,因为原始数据集没有任何列名。
数据字典(用于代码GWA_BTC)。
- 日期: 计算指数值的那一天。
- 开盘: 当天比特币的开盘价格指数,以美元计。
- 高点:当天以美元计的比特币价格指数的最高值。
- 低点:当天以美元计的比特币价格指数的最低值。
- 收盘: 当天以美元计算的比特币收盘价格指数。
- 成交量: 当天比特币的交易量。
- VWAP: 当天交易的比特币的成交量加权平均价格。
- TWAP: 当天交易的比特币的时间加权平均价格。
第三步:了解数据。
处理数据的一个最常见的原因是,当有 "太多的 "信息挤在一个表中时,特别是在处理时间序列数据时。
一般来说,所有的观察值在粒度和单位上都应该是相等的。
会有一些例外,但在大多数情况下,这个经验法则可以使你免于许多麻烦。
- 粒度相等 例如,你可以有10行来自10种不同加密货币的数据。然而,你不应该有第11行的平均值或其他10行的总价值。这第11行将是一个聚合,因此在粒度上与其他10行不相等。
- 单位上的等价 你可以有10行在不同日期收集的美元价格。但是,你不应该有另外10行以欧元报价的记录。任何聚合、分布、可视化或统计都将变得毫无意义。
我们目前的原始数据集就打破了这两条规则。
存储在CSV文件或数据库中的数据通常是 "堆叠 "或 "记录 "格式。他们使用单一的
'Code'
列作为元数据的集合。例如,在样本数据集中,我们有以下的代码。
# Unique codes in the dataset
print( df.Code.unique() )
# ['GWA_BTC' 'GWA_ETH' 'GWA_LTC' 'GWA_XLM' 'GWA_XRP' 'MWA_BTC_CNY'
# 'MWA_BTC_EUR' 'MWA_BTC_GBP' 'MWA_BTC_JPY' 'MWA_BTC_USD' 'MWA_ETH_CNY'
# 'MWA_ETH_EUR' 'MWA_ETH_GBP' 'MWA_ETH_JPY' 'MWA_ETH_USD' 'MWA_LTC_CNY'
# 'MWA_LTC_EUR' 'MWA_LTC_GBP' 'MWA_LTC_JPY' 'MWA_LTC_USD' 'MWA_XLM_CNY'
# 'MWA_XLM_EUR' 'MWA_XLM_USD' 'MWA_XRP_CNY' 'MWA_XRP_EUR' 'MWA_XRP_GBP'
# 'MWA_XRP_JPY' 'MWA_XRP_USD']
首先,看到一些代码是以GWA开头,而另一些则以MWA开头吗?根据文档页面,这些实际上是完全不同类型的指标。
- MWA代表"市场加权平均值",它们显示的是区域价格。每种加密货币都有多个MWA代码,每种当地法币都有一个。
- 另一方面,GWA代表"全球加权平均数",它显示全球指数化的价格。因此,GWA是MWA的汇总,在颗粒度上并不等同。(注意:样本数据集中只包括了一部分地区的MWA代码)。
例如,让我们看一下比特币在同一日期的代码。
# Example of GWA and MWA relationship
df[df.Code.isin(['GWA_BTC', 'MWA_BTC_JPY', 'MWA_BTC_EUR'])
& (df.Date == '2018-01-01')]

正如你所看到的,我们在一个特定的日期有多个加密货币的条目。让事情更复杂的是,地区MWA数据是以其当地货币计价的(即非等价单位),所以你还需要历史汇率。
不同的粒度和/或不同的单位使分析变得复杂,最好的情况是根本不可能。
幸运的是,一旦我们发现了这个问题,修复它实际上是微不足道的。
第四步:过滤不需要的观察结果。
最简单而又最有用的数据处理技术之一就是去除不需要的观测值。
在上一个步骤中,我们了解到GWA代码是区域MWA代码的汇总。因此,为了执行我们的分析,我们只需要保留全球的GWA代码。
# Number of observations in dataset
print( 'Before:', len(df) )
# Before: 31761
# Get all the GWA codes
gwa_codes = [code for code in df.Code.unique() if 'GWA_' in code]
# Only keep GWA observations
df = df[df.Code.isin(gwa_codes)]
# Number of observations left
print( 'After:', len(df) )
# After: 6309
现在我们只剩下GWA代码了,我们所有的观测值在粒度和单位上都是相等的。我们可以自信地继续下去。
第五步:对数据集进行透视。
接下来,为了分析我们上述的动量交易策略,对于每个加密货币,我们需要计算之前7天、14天、21天和28天的回报,每个月的第一天。
然而,用目前的 "堆叠 "数据集这样做将是一个巨大的痛苦。这将涉及编写辅助函数、循环和大量的条件逻辑。相反,我们将采取一种更优雅的方法。
首先,我们将 枢轴数据集,同时只保留一个价格列。在本教程中,让我们保留VWAP(成交量加权平均价格)列,但你可以为大多数列做一个很好的案例。
# Pivot dataset
pivoted_df = df.pivot(index='Date', columns='Code', values='VWAP')
# Display examples from pivoted dataset
pivoted_df.tail()

正如你所看到的,我们的透视数据集中的每一列现在代表一种加密货币的价格,每一行包含一个日期的价格。所有的特征现在都是按日期排列的。
第6步:转移透视的数据集。
为了方便计算之前7天、14天、21天和28天的收益,我们可以使用Pandas的移动方法。
这个函数将数据框架的索引移到一定数量的时期。例如,当我们将我们的透视数据集移动1时,会发生什么。
print( pivoted_df.tail(3) )
# Code GWA_BTC GWA_ETH GWA_LTC GWA_XLM GWA_XRP
# Date
# 2018-01-21 12,326.23 1,108.90 197.36 0.48 1.55
# 2018-01-22 11,397.52 1,038.21 184.92 0.47 1.43
# 2018-01-23 10,921.00 992.05 176.95 0.47 1.42
print( pivoted_df.tail(3).shift(1) )
# Code GWA_BTC GWA_ETH GWA_LTC GWA_XLM GWA_XRP
# Date
# 2018-01-21 nan nan nan nan nan
# 2018-01-22 12,326.23 1,108.90 197.36 0.48 1.55
# 2018-01-23 11,397.52 1,038.21 184.92 0.47 1.43
注意到移位后的数据集现在有1天前的数值吗?我们可以利用这一点来计算7、14、21、28天窗口的前期回报。
例如,要计算之前7天的回报,我们需要
prices_today / prices_7_days_ago - 1.0
这就意味着:
# Calculate returns over 7 days prior
delta_7 = pivoted_df / pivoted_df.shift(7) - 1.0
# Display examples
delta_7.tail()

计算我们所有窗口的回报率就像写一个循环并把它们存储在一个字典里一样简单。
# Calculate returns over each window and store them in dictionary
delta_dict = {}
for offset in [7, 14, 21, 28]:
delta_dict['delta_{}'.format(offset)] = pivoted_df / pivoted_df.shift(offset) - 1.0
注意:通过移动数据集来计算回报率需要满足两个假设。(1) 观察值按日期升序排序;(2)没有遗漏的日期。为了保持本教程的简洁,我们在 "台下 "检查了这一点,但我们建议你自己去确认。
第7步:熔化移位后的数据集。
现在我们已经用透视的数据集计算出了回报,我们要对回报进行 "解透"。通过取消透视,或 融化数据,我们就可以创建一个分析基表(ABT),其中 每一行都包含某个特定日期的特定硬币的所有相关信息。
我们不能直接转移原始数据集,因为不同币种的数据是相互堆叠的,所以边界会有重叠。换句话说,BTC的数据会泄露到ETH的计算中,ETH的数据会泄露到LTC的计算中,以此类推。
为了融化这些数据,我们将:
-
reset_index()这样我们就可以按名称调用各列。
-
调用
melt()方法。
-
将要保留的列传入
id_vars=参数。
-
使用
value_name=参数命名熔化的列。
下面是一个数据框架的情况。
# Melt delta_7 returns
melted_7 = delta_7.reset_index().melt(id_vars=['Date'], value_name='delta_7')
# Melted dataframe examples
melted_7.tail()

要对所有返回的数据框架进行这样的操作:
delta_dict
像这样循环。
# Melt all the delta dataframes and store in list
melted_dfs = []
for key, delta_df in delta_dict.items():
melted_dfs.append( delta_df.reset_index().melt(id_vars=['Date'], value_name=key) )
最后,我们可以创建另一个融化的数据框架,其中包含前瞻性的7天回报。这将是我们用于评估交易策略的"目标变量"。
简单地将透视的数据集移到
-7
以获得 "未来 "价格,像这样。
# Calculate 7-day returns after the date
return_df = pivoted_df.shift(-7) / pivoted_df - 1.0
# Melt the return dataset and append to list
melted_dfs.append( return_df.reset_index().melt(id_vars=['Date'], value_name='return_7') )
我们现在有5个融化的数据集存储在
melted_dfs
列表中,其中一个是后向7天、14天、21天和28天的回报,一个是前向7天的回报。
第8步:减少-合并熔化的数据。
剩下要做的就是将我们融化的数据框架连接到一个单一的分析基表。我们将需要两个工具。
首先是Pandas的 合并函数,其工作原理类似于SQL JOIN。例如,要合并前两个融化的数据框
# Merge two dataframes
pd.merge(melted_dfs[0], melted_dfs[1], on=['Date', 'Code']).tail()

看到我们现在如何将delta_7和delta_14放在同一行吗?这就是我们的分析基表的开始。我们现在需要做的是将所有熔化的数据帧与我们可能需要的其他特征的基础数据帧合并在一起。
最优雅的方法是使用Python的内置 减少函数。首先我们需要导入它。
from functools import reduce
接下来,在我们使用该函数之前,让我们创建一个
feature_dfs
列表,其中包含来自原始数据集加上融化的数据集的基础特征。
# Grab features from original dataset
base_df = df[['Date', 'Code', 'Volume', 'VWAP']]
# Create a list with all the feature dataframes
feature_dfs = [base_df] + melted_dfs
现在我们准备使用reduce函数。Reduce将一个两个参数的函数累积应用于一个序列(例如一个列表)中的对象。例如,
reduce(lambda x,y: x+y, [1,2,3,4,5])
计算
((((1+2)+3)+4)+5)
。
因此,我们可以像这样减少-合并所有的特征。
# Reduce-merge features into analytical base table
abt = reduce(lambda left,right: pd.merge(left,right,on=['Date', 'Code']), feature_dfs)
# Display examples from the ABT
abt.tail(10)

我们的分析基表(ABT)的数据字典。
- 日期:计算指数值的那一天。
- 代码:哪种加密货币。
- VWAP:当天的交易量加权平均价格。
- delta_7:前7天的回报(1.0 = 100%回报)。
- delta_14:过去14天的回报(1.0 = 100%回报)。
- delta_21:前21天的回报率(1.0=100%回报率)。
- delta_28:前28天的回报(1.0=100%的回报)。
- return_7:未来7天的回报(1.0=100%的回报)。
顺便说一下,注意到最后7个观测值没有
'return_7'
的值吗?这是预料之中的,因为我们无法计算数据集最后7天的 "未来7天回报"。
从技术上讲,通过这个ABT,我们已经可以回答我们最初的目标。例如,如果我们想挑选在2017年9月1日拥有最大动力的硬币,我们可以简单地显示该日期的行,并查看之前7天、14天、21天和28天的回报。
# Data from Sept 1st, 2017
abt[abt.Date == '2017-09-01']

而如果你想以编程方式挑选具有最大势头的加密货币(例如,在之前的28天内),你可以写。
max_momentum_id = abt[abt.Date == '2017-09-01'].delta_28.idxmax()
daily_df.loc[max_momentum_id, ['Code','return_7']]
# Code GWA_LTC
# return_7 -0.10
# Name: 3543, dtype: object
然而,由于我们只对每个月的第一天的交易感兴趣,我们可以让事情变得更简单。
第9步:(可选)用group-by进行汇总。
作为最后一步,如果我们想只保留每个月的第一天,我们可以用一个 group-by后面加上一个 聚合.
-
首先,从日期字符串的前7个字符创建一个新的
'month'特征。
-
然后,通过
'Code'和
'month'对观察结果进行分组。Pandas将创建数据的 "单元格",按代码和月份将观测值分开。
-
最后,在每个组中,只需取
.first()观察值并重新设置索引。
注意:我们假设你的数据框架仍然是按日期正确排序的。
下面是它全部组合起来的样子。
# Create 'month' feature
abt['month'] = abt.Date.apply(lambda x: x[:7])
# Group by 'Code' and 'month' and keep first date
gb_df = abt.groupby(['Code', 'month']).first().reset_index()
# Display examples
gb_df.tail()
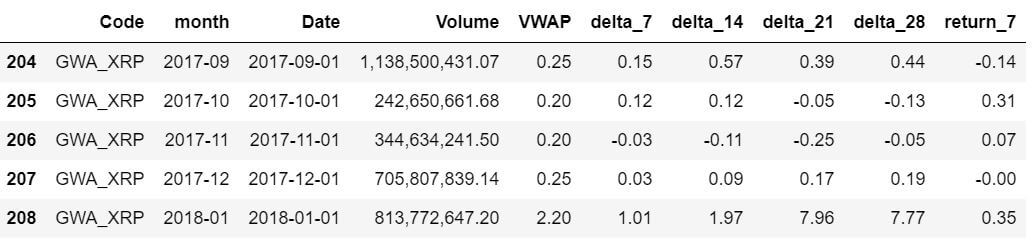
正如你所看到的,我们现在有了一个适当的ABT与。
- 只有每个月的第一天的相关数据。
- 从之前的7天、14天、21天和28天计算的动量特征。
- 你7天后的未来回报。
换句话说,我们完全有必要评估我们在一开始提出的简单交易策略!这就是我们所需要的。
恭喜你......你已经走到了这个Python数据处理教程的尽头。
我们介绍了在Python中过滤、操作和转换数据集的几个关键工具,但我们只是触及了表面。Pandas是一个非常强大的库,有大量的附加功能。
为了继续学习,我们建议下载更多的数据集进行动手实践。提出一个有趣的问题,计划你的方法,并依靠文档的帮助。
完整的代码,从头到尾。
这里有所有的主要代码,都在一个地方,在一个脚本中。
# 2. Import libraries and dataset
import pandas as pd
pd.options.display.float_format = '{:,.2f}'.format
pd.options.display.max_rows = 200
pd.options.display.max_columns = 100
df = pd.read_csv('BNC2_sample.csv',
names=['Code', 'Date', 'Open', 'High', 'Low',
'Close', 'Volume', 'VWAP', 'TWAP'])
# 4. Filter unwanted observations
gwa_codes = [code for code in df.Code.unique() if 'GWA_' in code]
df = df[df.Code.isin(gwa_codes)]
# 5. Pivot the dataset
pivoted_df = df.pivot(index='Date', columns='Code', values='VWAP')
# 6. Shift the pivoted dataset
delta_dict = {}
for offset in [7, 14, 21, 28]:
delta_dict['delta_{}'.format(offset)] = pivoted_df / pivoted_df.shift(offset) - 1
# 7. Melt the shifted dataset
melted_dfs = []
for key, delta_df in delta_dict.items():
melted_dfs.append( delta_df.reset_index().melt(id_vars=['Date'], value_name=key) )
return_df = pivoted_df.shift(-7) / pivoted_df - 1.0
melted_dfs.append( return_df.reset_index().melt(id_vars=['Date'], value_name='return_7') )
# 8. Reduce-merge the melted data
from functools import reduce
base_df = df[['Date', 'Code', 'Volume', 'VWAP']]
feature_dfs = [base_df] + melted_dfs
abt = reduce(lambda left,right: pd.merge(left,right,on=['Date', 'Code']), feature_dfs)
# 9. Aggregate with group-by.
abt['month'] = abt.Date.apply(lambda x: x[:7])
gb_df = abt.groupby(['Code', 'month']).first().reset_index()
