

线性回归是对因变量和一个或多个自变量之间的关系进行建模的一种常见和有用的方法。它的使用跨越了许多应用,如经济学、医学和科学。无论你是实验室里的专家还是笔记本电脑上的初学者,线性回归都是一种在相对简单的公式基础上实现有价值结果的方法。
在本教程中,你将使用Python和scikit-learn实现一个线性回归模型。为了增加更多的功能,你将使用Flask和Twilio的可编程消息API来帮助你建立数据,并从你的手机上方便地进行预测。
设置你的项目环境
在你深入学习代码之前,你需要在你的电脑上设置项目环境。首先,你应该创建一个存放项目的父目录。在你的电脑上打开终端,导航到一个适合你的项目的目录,输入以下命令,然后点击回车:
mkdir linear-regression-project && cd linear-regression-project
接下来,你将需要有一个地方来存储你的数据和模型。每次最多只有一个数据文件和一个模型文件,而且这些文件将被存储在同一个目录中。在linear-regression-project目录中,键入以下命令来创建一个名为model 的新目录:
mkdir model
作为 Python 良好编程实践的一部分,你还应该创建一个虚拟环境。如果你在 UNIX 或 macOS 上工作,运行下面的命令来创建和激活一个虚拟环境。第一个命令是创建虚拟环境,第二个命令是激活它:
python3 -m venv venv
source venv/bin/activate
然而,如果你在Windows上工作,运行这些命令来代替:
python -m venv venv
venv\bin\activate
在激活你的虚拟环境之后,你应该安装一些 Python 包。在本教程中,你将使用以下软件包:
- Flask来构建你的应用程序。
- Twilio Python Helper Library,与Twilio APIs进行交互。
- Pickle来保存和加载模型。
- pandas来组织数据。
- scikit-learn来建立线性回归模型。
要安装这些包,运行这个命令:
pip install flask python-dotenv twilio pickle-mixin pandas scikit-learn
你的环境已经设置好了。现在你已经准备好开始创建应用程序了。
创建你的线性回归模块
首先,你将创建一个Python模块来帮助你与线性回归模型进行交互和构建。在linear-regression-project目录中,创建一个名为linregress.py 的文件。
复制并粘贴以下代码到linregress.py中:
from sklearn.linear_model import LinearRegression
import pandas as pd
import pickle
import os.path
PATH_TO_DATA="./model/data.csv"
PATH_TO_MODEL="./model/model.pkl"
在上面的代码片段中,必要的模块被导入,模型和数据的路径被定义。按照路径的定义,数据将被格式化为CSV文件,模型将被格式化为一个序列化的pickle文件。
此外,linregress.py中会有三个函数。update,makePrediction, 和clearData 。这些函数与数据和模型交互,它们各自以字符串的形式返回关于模型的信息。下面将逐步介绍每个函数。然而,linregress.py的完整代码可以在本节末尾找到。
定义更新函数
为了帮助你建立数据和模型,你需要创建一个允许你更新数据和模型的函数。这个函数的预期要求如下:
- 该函数接收一个列表。
- 列表的一个前提条件是它至少有两个元素,而且每个元素都是数字。
- 列表的第一个元素是因变量,后面的任何元素都是自变量。
- 如果数据还没有被初始化,那么我们就用传入函数的列表来初始化它。
- 该函数拟合并保存了一个线性回归模型。
- 该函数返回一个字符串,确认模型已被拟合,并与训练R2值一起保存。
首先,让我们着手创建和加载数据。在linregress.py文件中复制并粘贴以下代码,在这里你定义了数据和模型的路径:
def update(aList):
# If the data exists, load and update. Else, initialize it
if os.path.exists(PATH_TO_DATA):
df = pd.read_csv(PATH_TO_DATA)
if len(aList) != len(df.columns):
return 'Dimension size does not match. Number of dependent variables '\
+ f'is 1. Number of independent variables is {len(df.columns)-1}.' \
+ ' Please format as "append y x_0 x_1 x_2 ..."'
# Update data frame and data.csv with aList as a new row
df2 = pd.DataFrame([aList],columns=df.columns)
df = pd.concat([df,df2], ignore_index=True)
df.to_csv(PATH_TO_DATA,index=False)
else:
columnHeader = ['y'] + [f'x_{i}' for i in range(len(aList[1:]))]
df = pd.DataFrame([aList], columns=columnHeader)
df.to_csv(PATH_TO_DATA,index=False)
在上面的代码片段中,有一个if-else语句,涵盖了数据是否已经被初始化。如果数据已经存在,那么它可以被初始化为一个pandas DataFrame。之后,DataFrame被更新为作为参数传入的列表(aList )。然后,更新后的DataFrame被保存为data.csv 文件。
然而,还有一种可能,就是数据还没有被初始化。如果是这种情况,那么DataFrame应该用一个列表和一个列头来初始化。所以,列头是用列表理解法创建的 (见Python 数据结构文档中关于列表理解法的章节)。然后,aList 和columnHeader 都被传入以初始化 DataFrame,并且 DataFrame 被保存为data.csv文件。
接下来,你需要拟合线性回归模型并保存该模型。复制并粘贴以下代码在if-else块的下面(和外面):
# Fit linear regression
y = df['y'].values
X = df.drop(['y'], axis=1)
lr = LinearRegression().fit(X,y)
# Save model
with open(PATH_TO_MODEL, 'wb') as f:
pickle.dump(lr, f)
# Return message to reply
vars = '\n'.join([f'{name} = {val}' for name, val in zip(df.columns, aList)])
return f'Appended:\n{vars}\nModel fitted and saved.\n'\
+ f'Training R2 = {str(round(lr.score(X,y),3))}'
在上面的代码片段中,模型被拟合和保存,并返回给用户的信息。为了建立线性回归模型,因变量和自变量由它们各自的列来定义。然后,拟合一个线性回归模型。之后,使用pickle保存模型,该函数返回一条消息,表示模型已经被拟合和保存。R2值也会被返回,以便给用户一个关于模型拟合程度的估计。
定义makePrediction和clearData函数
在模型被拟合后,你可以进行预测。要做到这一点,你可以定义一个函数,接收一个列表并计算出预测值。这个函数的预期要求如下:
- 该函数接收了一个列表。
- 列表的前提条件是它至少有一个元素,并且每个元素都是数字的。
- 所有的元素都是因变量。
- 该函数加载模型并计算预测值。
复制并粘贴以下代码到linregress.py文件中,在update 函数的下面:
def makePrediction(Xs):
if not os.path.exists(PATH_TO_MODEL):
return "Data and model doesn't exist. Cannot make a prediction."
with open(PATH_TO_MODEL,'rb') as f:
model = pickle.load(f)
# Check if dimension size is valid
if model.n_features_in_ != len(Xs):
return 'Dimension size does not match. Number of independent variables '\
+ f'is {model.n_features_in_}. Please format as "predict x_0 x_1 x_2 ..."'
# Make and return prediction
columnHeader = [f'x_{i}' for i in range(len(Xs))]
df_x = pd.DataFrame([Xs],columns=columnHeader)
vars = '\n'.join([f'{name} = {val}' for name, val in zip(columnHeader,Xs)])
return f'{vars}\nPrediction: y = ' + str(round(model.predict(df_x)[0], 3))
让我们简单地看一下上面的代码片段。首先,为了进行预测,模型必须存在。因此,该函数首先检查模型是否存在,然后才可以继续进行预测。如果模型确实存在,保存的模型将被加载到变量model 。然后,该函数检查列表的大小是否与模型中定义的自变量数量相匹配。最后,预测结果被计算并返回。
为了增加更多的功能,定义了clearData 函数来删除数据和模型。在linregress.py中复制并粘贴以下代码,放在makePrediction 函数的下面:
def clearData():
if os.path.exists(PATH_TO_DATA):
os.remove(PATH_TO_DATA)
os.remove(PATH_TO_MODEL)
return "Data and model cleared."
为了避免删除文件时出现错误,文件需要存在。因此,该函数检查数据的路径是否存在(这也意味着模型的路径存在)。如果它确实存在,数据和模型都可以安全地被删除。
完成线性回归模块
你已经完成了线性回归模块的编码。你的代码应该看起来像这样:
from sklearn.linear_model import LinearRegression
import pandas as pd
import pickle
import os.path
PATH_TO_DATA="./model/data.csv"
PATH_TO_MODEL="./model/model.pkl"
def update(aList):
# If the data exist, initialize it
if os.path.exists(PATH_TO_DATA):
df = pd.read_csv(PATH_TO_DATA)
if len(aList) != len(df.columns):
return 'Dimension size does not match. Number of dependent variables '\
+ f'is 1. Number of independent variables is {len(df.columns)-1}.' \
+ ' Please format as "append y x_0 x_1 x_2 ..."'
# Update data frame and data.csv with new row
df2 = pd.DataFrame([aList],columns=df.columns)
df = pd.concat([df,df2], ignore_index=True)
df.to_csv(PATH_TO_DATA,index=False)
else:
columnHeader = ['y'] + [f'x_{i}' for i in range(len(aList[1:]))]
df = pd.DataFrame([aList], columns=columnHeader)
df.to_csv(PATH_TO_DATA,index=False)
# Fit linear regression
y = df['y'].values
X = df.drop(['y'], axis=1)
lr = LinearRegression().fit(X,y)
# Save model
with open(PATH_TO_MODEL, 'wb') as f:
pickle.dump(lr, f)
# Return message to reply
vars = '\n'.join([f'{name} = {val}' for name, val in zip(df.columns, aList)])
return f'Appended:\n{vars}\nModel fitted and saved.\n'\
+ f'Training R2 = {str(round(lr.score(X,y),3))}'
def makePrediction(Xs):
if not os.path.exists(PATH_TO_MODEL):
return "Data and model doesn't exist. Cannot make prediction."
with open(PATH_TO_MODEL,'rb') as f:
model = pickle.load(f)
# Check if dimension size is valid
if model.n_features_in_ != len(Xs):
return 'Dimension size does not match. Number of independent variables '\
+ f'is {model.n_features_in_}. Please format as "predict x_0 x_1 x_2 ..."'
# Make and return prediction
columnHeader = [f'x_{i}' for i in range(len(Xs))]
df_x = pd.DataFrame([Xs],columns=columnHeader)
vars = '\n'.join([f'{name} = {val}' for name, val in zip(columnHeader,Xs)])
return f'{vars}\nPrediction: y = ' + str(round(model.predict(df_x)[0], 3))
def clearData():
if os.path.exists(PATH_TO_DATA):
os.remove(PATH_TO_DATA)
os.remove(PATH_TO_MODEL)
return "Data and model cleared."
你可以通过直接运行这些函数来测试这个模块。要看你如何使用这个模块通过文本信息建立一个线性回归模型,请继续看下面的部分。
创建你的应用程序
以下是该应用程序的预期流程:
- 一个用户给Twilio的电话号码留言。
- 用户可以给一个命令留言,这个命令可以添加数据,进行预测,或者清除数据。
- 如果用户没有输入下面的命令,或者没有正确地格式化命令,那么就会返回一条消息,说明如何格式化命令。
在linear-regression-project目录中,创建一个名为app.py 的新文件。为了遵循预期的流程,复制并粘贴以下代码到app.py:
from flask import Flask, request
from twilio.twiml.messaging_response import MessagingResponse
import linregress as lr
app = Flask(__name__)
def validFormat(aString):
s = aString.split()
if len(s) > 0 and all(i.isnumeric() for i in s[1:]):
match s[0].lower():
case "append":
return len(s) >= 3
case "predict":
return len(s) >= 2
case "clear":
return len(s) == 1
case other:
return False
else:
return False
def reply(message):
response = MessagingResponse()
response.message(message)
return str(response)
上面的代码片段包括导入语句和一些辅助函数。第3行的import语句导入了你在上一节中制作的模块。
validFormat 函数检查传入的字符串是否有效。这些条件必须得到满足,字符串才能有效地被格式化:
- 每个单词或数字都用空格隔开。
- 每个命令的第一个字必须是 "append"、"predict "或 "clear"。
- append "命令后面必须有2个或更多的数字。
- predict "后面必须有1个或更多的数字。
- 清除 "命令后面不能有任何数字。
此外,为了使代码看起来更整洁,定义了reply 辅助函数。该函数用于创建一个TwiML MessagingResponse对象,以便应用程序能够向用户发送消息。
接下来,你需要定义"/sms "端点,为应用程序提供主要功能。复制并粘贴app.py中reply 函数下面的其余代码:
@app.route("/sms", methods=['GET','POST'])
def sms_reply():
incoming_message = request.form['Body']
if validFormat(incoming_message):
s = incoming_message.split()
match s[0].lower():
case "append":
return reply(lr.update(s[1:]))
case "predict":
return reply(lr.makePrediction(s[1:]))
case "clear":
return reply(lr.clearData())
else:
return reply('Invalid format. To append data, type ' \
+ '"append y x_0 x_1 ..." To make a prediction, type '\
+ '"predict x_0 x_1 ..." To clear, type "clear".')
if __name__ == "__main__":
app.run()
匹配大小写语句在Python 3.10及以上版本中可用,所以如果你打算使用这个代码片段,请务必升级你的版本。
在代码中,从"/sms "URL的请求中接收传入的消息体。然后,该函数使用辅助函数validFormat ,以检查传入的消息是否被有效地格式化。如果不是,则返回关于如何格式化命令的指示。否则,根据传入的信息,使用从linregress模块导入的适当函数,因此用户可以更新、预测或清除线性回归模型。
然而,这个应用还没有完全完成。继续看下一节,弄清楚如何配置webhook以及如何运行该应用程序。
设置ngrok隧道和webhook
如果你过早地运行该程序,你将不会收到电话号码的信息。有两件事需要解决。首先,你需要通过打开ngrok隧道到你的本地机器,将你的本地服务器连接到一个公开访问的URL。第二,你需要通过使用webhook将Twilio电话号码连接到应用程序。
在你的机器上安装并验证了ngrok后,打开另一个命令提示符窗口,并运行这个命令,打开一个通往5000端口的隧道:
ngrok http 5000
之后,你的命令提示符应该看起来像这样:
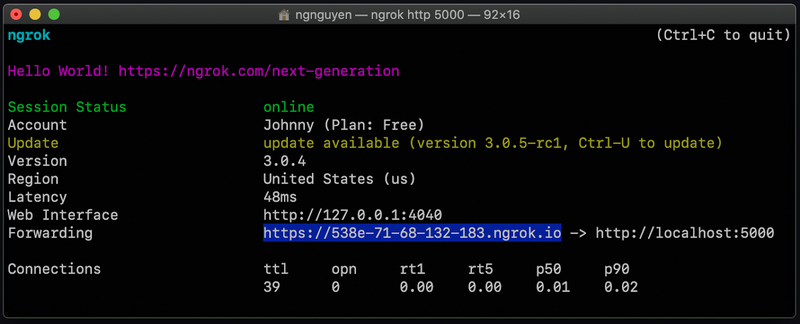
在Forwarding这个词的旁边,应该有一个指向https://localhost:5000 的URL*。*你的URL应该与上面显示的不同。复制该URL,因为它将被用于设置网络钩子。让这个命令提示符打开。
在你的Twilio控制台的左侧,导航到电话号码>管理>活动号码。点击活动号码将带你到**活动号码**页面。点击你将在此应用中使用的电话号码的链接。
这将带你到该电话号码的配置页面。向下滚动到 "消息",将你之前复制的URL粘贴到 "消息来了"部分,并在URL的末尾添加"/sms"。这是Flask应用程序的端点,TwiML响应会被发送到这里。所以你的URL应该是类似于your-ngrok-url.ngrok.io/sms ,并且应该像下面的例子一样进行粘贴。
点击页面底部的 "保存"来更新号码的设置。现在你终于准备好运行该应用程序了。
运行应用程序
要运行该应用程序,请在激活虚拟环境的线性回归-项目目录中运行该命令:
flask run
之后,你的应用程序应该可以正常工作了。每当有人向你的Twilio电话号码发送短信时,Flask应用程序将在/sms 端点接收一个请求,并根据用户的信息返回一个响应。继续尝试向你的线性回归模型添加数据。在追加了几个数据点之后,你就可以进行预测了。你可以将其用于不同的应用,如预测租金价格或收益率。或者做一些古怪的事情,比如根据西瓜的尺寸、密度和敲击频率来预测完美的西瓜如何?这种可能性是无穷无尽的。
总结
恭喜你使用Twilio的可编程消息传输API构建了一个应用程序在本教程中,你学会了如何创建一个线性回归Python模块,并将其用于一个允许用户用线性回归进行预测的SMS应用。该应用程序使用pandas和scikit-learn来格式化数据并制作线性回归模型,能够更新、删除和进行预测。你可以根据自己的喜好自由地定制这个应用程序。例如,你可以在scikit-learn中探索不同类型的机器学习算法,如随机森林回归器。你可以做的其他事情是为不同的数据维度和类型调整代码,或者也许你可以尝试把它改为分类器,而不是回归。看看这个列表,你可以用 sci-kit learn 执行不同类型的监督学习。
