

在本指南中,我们将引导你了解什么是过拟合,如何在你的模型中发现它,以及如果你的模型是过拟合,该怎么做。
到最后,你会知道如何一劳永逸地处理这个棘手的问题。
目录
过度拟合的例子
假设我们想根据一个学生的简历来预测她是否会获得工作面试。
现在,假设我们从10,000份简历及其结果的数据集中训练一个模型。
但现在有一个坏消息。
当我们在一个新的("未见过的")简历数据集上运行该模型时,我们只得到了50%的准确率。
我们的模型不能很好地从我们的训练数据概括到未见过的数据。
这就是所谓的过拟合,它是机器学习和数据科学中的一个常见问题。
事实上,过度拟合在现实世界中一直在发生。你只需要打开新闻频道就能听到这样的例子。

过度拟合选举优先权(来源:XKCD)
信号与噪声
你可能听说过Nate Silver写的那本著名的《信号与噪音》。
在预测性建模中,你可以把 "信号 "看作是你希望从数据中学习的真正的基本模式。
另一方面,"噪音 "指的是数据集中的不相关信息或随机性。
例如,假设你正在对儿童的身高与年龄进行建模。如果你对人口的一大部分进行抽样调查,你会发现一个相当清晰的关系。

身高与年龄(来源:CDC)
这就是信号。
然而,如果你只能对当地的一所学校进行抽样调查,这种关系可能会更模糊。它将受到异常值(例如,父亲是NBA球员的孩子)和随机性(例如,在不同年龄段进入青春期的孩子)的影响。
噪声会干扰信号。
这就是机器学习发挥作用的地方。一个运作良好的ML算法会把信号和噪音分开。
如果算法太复杂或太灵活(例如,它有太多的输入特征,或者它没有被正确规范化),它最终会 "记住噪音",而不是找到信号。
然后,这种过拟合模型将根据该噪声进行预测。它在训练数据上会表现得异常好......但在新的、未见过的数据上却表现得非常差。
拟合度
在统计学中,拟合度指的是一个模型的预测值与观察到的(真实)值有多密切。
一个学会了噪音而不是信号的模型被认为是 "过拟合 "的,因为它适合训练数据集,但对新数据集的拟合度很差。
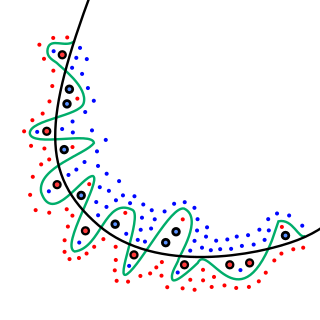
虽然黑线对数据的拟合很好,但绿线是过拟合。
过度拟合与欠拟合
我们可以通过观察相反的问题,即欠拟合,更好地理解过度拟合。
当一个模型过于简单--被太少的特征告知或被太多的正则化--使得它在从数据集学习时缺乏灵活性时,就会发生欠拟合。
简单的学习者倾向于在他们的预测中具有较少的方差,但对错误的结果有更多的偏见(见:偏见-方差权衡)。
另一方面,复杂的学习者倾向于在他们的预测中拥有更多的方差。
偏见和方差都是机器学习中预测错误的形式。
通常情况下,我们可以减少偏见带来的错误,但可能会因此而增加方差带来的错误,反之亦然。
这种太简单(高偏差)与太复杂(高方差)之间的权衡是统计学和机器学习中的一个关键概念,也是影响所有监督学习算法的一个概念。

偏倚与方差(来源:EDS)
如何检测过拟合
过度拟合的一个关键挑战,以及一般的机器学习,是我们无法知道我们的模型在新数据上的表现如何,直到我们实际测试它。
为了解决这个问题,我们可以将我们的初始数据集分成独立的训练和测试子集。

训练-测试分割
这种方法可以大致了解我们的模型在新数据上的表现。
如果我们的模型在训练集上的表现比在测试集上的表现好得多,那么我们就很可能是过度拟合。
例如,如果我们的模型在训练集上有99%的准确率,但在测试集上只有55%的准确率,这将是一个很大的红旗。
如果你想看看这在Python中是如何工作的,我们有一个使用Scikit-Learn的机器学习的完整教程。
另一个建议是,从一个非常简单的模型开始,作为一个基准。
然后,当你尝试更复杂的算法时,你会有一个参考点,看看额外的复杂性是否值得。
这就是奥卡姆剃刀的测试。如果两个模型的性能相当,那么你通常应该选择更简单的那个。
如何防止过度拟合
检测过度拟合是有用的,但它并不能解决问题。幸运的是,你有几个选项可以尝试。
下面是几个最流行的解决过拟合的方法。
交叉验证
交叉验证是防止过度拟合的强大预防措施。
这个想法很聪明。使用你的初始训练数据来生成多个小型的训练-测试分片。使用这些分片来调整你的模型。
在标准的k-fold交叉验证中,我们将数据划分为k个子集,称为folds。然后,我们在k-1个折叠上反复训练算法,同时使用剩余的折叠作为测试集(称为 "保留折叠")。
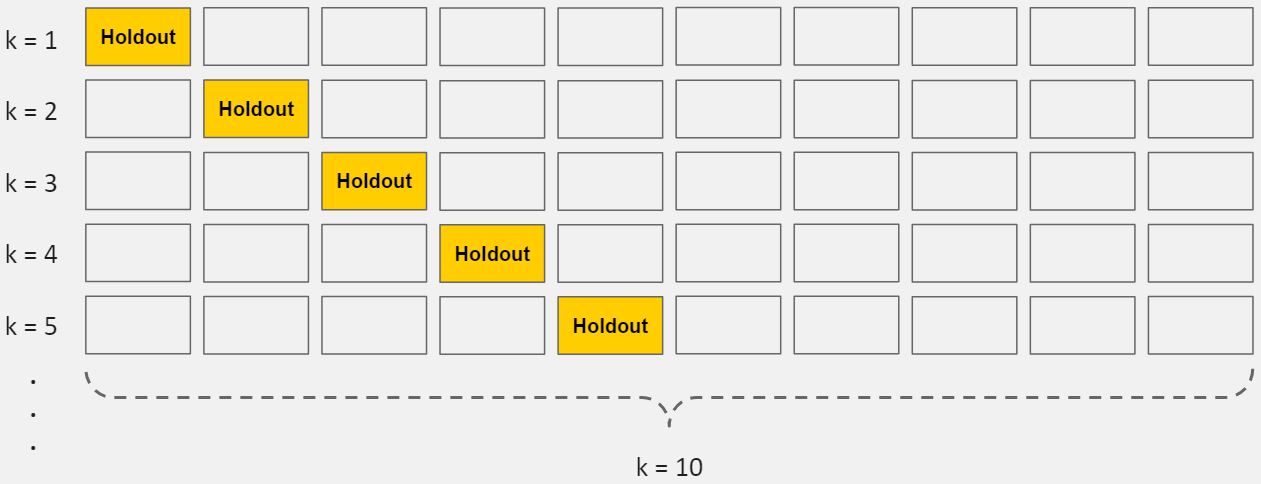
K-折交叉验证
交叉验证法允许你只用你的原始训练集来调整超参数。这允许你保持你的测试集作为一个真正未见过的数据集来选择你的最终模型。
用更多的数据进行训练
这不是每次都有效,但用更多的数据训练可以帮助算法更好地检测信号。在前面对儿童身高与年龄进行建模的例子中,很明显,对更多的学校进行抽样调查将有助于你的模型。
当然,情况并不总是这样的。如果我们只是增加了更多的噪声数据,这种技术就不会有帮助。这就是为什么你应该始终确保你的数据是干净和相关的。
删除特征
一些算法有内置的特征选择。
对于那些没有的算法,你可以通过删除不相关的输入特征来手动提高其泛化能力。
一个有趣的方法是讲述一个关于每个特征如何融入模型的故事。这就像数据科学家对软件工程师的橡皮鸭子调试技术的改造,他们通过对橡皮鸭子逐行解释来调试他们的代码。
如果有什么不合理的地方,或者很难证明某些特征的合理性,这是一个识别它们的好方法。
此外,有几个特征选择启发式方法,你可以用来作为一个好的起点。
早期停顿
当你在迭代训练一个学习算法时,你可以衡量模型的每个迭代的表现。
直到一定数量的迭代,新的迭代会改善模型。然而,在那之后,模型的泛化能力会减弱,因为它开始过度拟合训练数据。
早期停止是指在学习者通过该点之前停止训练过程。
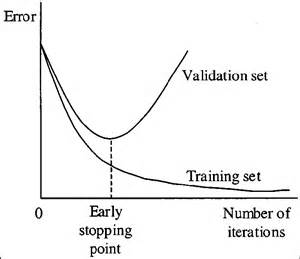
今天,这种技术主要用于深度学习,而其他技术(如正则化)则是经典机器学习的首选。
正则化
正则化是指一系列广泛的技术,用于人为地迫使你的模型变得更简单。
该方法将取决于你所使用的学习者的类型。例如,你可以修剪决策树,在神经网络上使用退出,或者在回归的成本函数上添加一个惩罚参数。
通常情况下,正则化方法也是一个超参数,这意味着它可以通过交叉验证进行调整。
我们在这里对算法和正则化方法有一个更详细的讨论。
组合
集合是一种机器学习方法,用于合并来自多个独立模型的预测结果。有几种不同的合集方法,但最常见的两种是。
装袋法试图减少复杂模型的过拟合机会。
- 它并行地训练大量的 "强 "学习者。
- 一个强大的学习者是一个相对不受约束的模型。
- 然后,Bagging将所有的强学习者结合在一起,以便 "平滑 "他们的预测。
Boosting试图提高简单模型的预测灵活性。
- 它依次训练了大量的 "弱 "学习者。
- 一个弱学习者是一个受限制的模型(即你可以限制每个决策树的最大深度)。
- 序列中的每一个都专注于从前面一个的错误中学习。
- 然后,Boosting将所有的弱学习者组合成一个单一的强学习者。
虽然bagging和boosting都是集合方法,但它们从相反的方向来处理问题。
装袋使用复杂的基础模型并试图 "平滑 "它们的预测,而提升使用简单的基础模型并试图 "提升 "它们的总体复杂性。
接下来的步骤
我们刚刚涵盖了相当多的概念。
- 信号、噪声,以及它们与过拟合的关系。
- 统计学中的拟合度
- 拟合不足与过度拟合
- 偏差-变异的权衡
- 如何使用训练-测试分割来检测过度拟合
- 如何使用交叉验证、特征选择、正则化等来防止过度拟合。
希望看到所有这些概念联系在一起有助于澄清其中一些概念。
要想真正掌握这个主题,我们建议得到实际的练习。
虽然这些概念一开始可能会让人感到不知所措,但一旦你开始在真实世界的代码和问题中看到它们,它们就会 "一目了然"。
